 Understanding ETL in EPM
Understanding ETL in EPM
This chapter provides an overview of the extract, transform, and load (ETL) process within EPM and discusses:
IBM WebSphere DataStage
ETL load strategies in EPM
Data validation and error handling in the ETL process
OWE Jobs
MDW Jobs
See Also
Understanding PeopleSoft Enterprise Performance Management
ETL Installation and Implementation Prerequisites and Considerations
Understanding ETL in EPM
This section discusses:
ETL and the EPM Architecture.
Data Flow through EPM.
IBM WebSphere DataStage.
 ETL and the EPM Architecture
ETL and the EPM Architecture The PeopleSoft delivered ETL process enables you to extract data from disparate source transaction systems, integrate the data in a single EPM database, transform and enrich the data, and load it into specific EPM data models that are optimized for analysis and reporting. This process is facilitated by the best-in-class data integration platform IBM WebSphere DataStage and PeopleSoft delivered ETL jobs.
The ETL process migrates data across all layers of EPM warehouse structures and consists of two load types:
Stage I Load: Consists of all ETL jobs that extract data from your source transaction system and load it into Operational Warehouse - Staging (OWS) tables. Also included in this type of load (but less common) are ETL jobs that extract data from your source transaction system and load it directly into Multidimensional Warehouse (MDW) tables.
Stage II Load: Consists of all ETL jobs that extract data from the OWS tables and load it into the Operational Warehouse - Enriched (OWE) or the Multidimensional Warehouse (MDW) tables. Also included in this type of load (but less common) are ETL jobs that extract data from the OWE and load it into the MDW.
The following diagram depicts the flow of data through each layer of the EPM architecture using ETL.
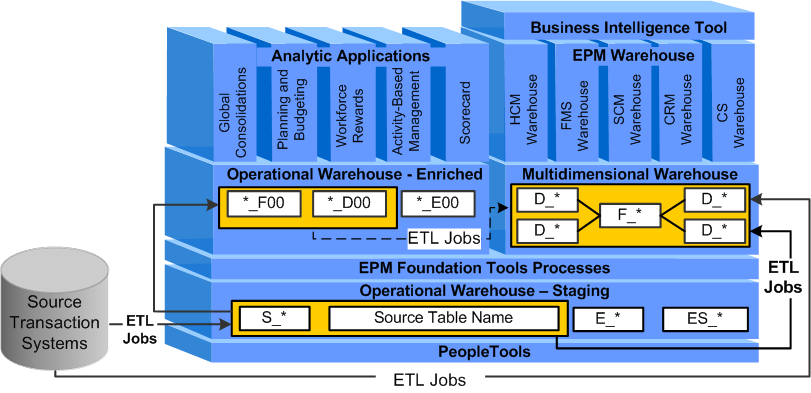
ETL in EPM
After your data is extracted from the OWS it is loaded into specialized data models (target warehouse tables designed to aggregate or enrich your data), which are used by the Analytical Applications and EPM Warehouses for reporting and analysis.
Understanding the Flow of Data Through EPM
Each EPM data warehouse requires a unique set of ETL jobs to populate corresponding target tables with data. Data warehouse target tables may have missing or inaccurate data in them if you do not run all applicable jobs in the proper sequence.
The following sections provide an overview of the ETL jobs required to populate each data warehouse layer with data.
You use ETL jobs to move data into the OWS from your PeopleSoft source system. The following is an overview of the steps required to bring data into the OWS:
Run initial setup (OWS) jobs.
Run source business unit extract jobs.
Run shared lookup jobs.
Run CSW OWS jobs (for CSW Warehouse implementation only).
Run CRM OWS jobs (for CRM Warehouse implementation only).
Run FMS OWS jobs (for FMS Warehouse implementation only).
Run HCM OWS jobs (for HCM Warehouse implementation only).
Run SCM OWS jobs (for SCM Warehouse implementation only).
You use ETL jobs to move data into the OWE from the OWS. The following is an overview of the steps required to bring data into the OWE:
Run the setup - OWE jobs.
Run common dimension jobs.
Some EPM warehouses require OWE data.
For these warehouses see steps below in, 'Moving Data Into the MDW.'
There are three methods of bringing data into the MDW:
Extracting data from the OWS and moving it into the MDW.
This is the most common method and the majority of your data is moved into the MDW in this way.
Extracting data from the OWE and moving it into the MDW.
Certain EPM warehouses use this method, which brings enriched, business unit-based data into the MDW.
For example, the Profitability data mart in the FMS Warehouses uses OWE data that is output from the Global Consolidations analytical application.
Extracting source data directly from a PeopleSoft source system and moving it into the MDW.
This method bypasses the OWS and is only used when large volumes of data must be extracted, such as data used for the Marketing data mart in the CRM Warehouse.
You use ETL jobs to move data into the MDW. The following is an overview of the steps required to bring data into the MDW:
Run Global Dimension Jobs for Campus Solutions Warehouse
Run Global Dimension Jobs for CRM Warehouse
Run Global Dimension Jobs for FMS Warehouse
Run Global Dimension Jobs for HCM Warehouse
Run Global Dimension Jobs for SCM Warehouse
Run Local Dimension Jobs for Campus Solutions Warehouse
Run Local Dimension Jobs for CRM Warehouse
Run Local Dimension Jobs for FMS Warehouse
Run Local Dimension Jobs for HCM Warehouse
Run Local Dimension Jobs for SCM Warehouse
Run CSW SKU Jobs
Run CRM SKU Jobs
Run FMS SKU Jobs
Run HCM SKU Jobs
Run SCM SKU Jobs
Run Global-OWE Jobs for CRM Warehouse
Run Global-OWE Jobs for FMS Warehouse
Run Global-OWE Jobs for HCM Warehouse
Run Global-OWE Jobs for SCM Warehouse
Run CRM-OWE jobs
Run FMS-OWE jobs
Run HCM-OWE jobs
Run SCM-OWE jobs
For more information on the jobs required to load data into the MDW for your EPM Warehouse, see your warehouse specific PeopleBook (for example, the PeopleSoft Campus Solutions Warehouse PeopleBook).
See Also
Running Campus Solutions Warehouse Implementation Jobs
Importing Source Business Units into EPM to Create Warehouse Business Units
Understanding IBM WebSphere DataStage
PeopleSoft has an original equipment manufacturer (OEM) agreement with IBM for its WebSphere DataStage ETL tool and bundles this offering with PeopleSoft EPM. The IBM WebSphere DataStage tool uses ETL jobs to target specific data from a PeopleSoft source database and migrate it to the OWS, OWE, and MDW tables. IBM WebSphere DataStage is comprised of a server tool and client tool, which are discussed in more detail below.
IBM WebSphere DataStage provides the following features:
Graphical design tools for designing ETL maps (called jobs)
Data extraction from a variety of data sources
Data aggregation using SQL SELECT statements
Data conversion using predefined or user-defined transformations and functions
Data loading using predefined or user-defined jobs
IBM WebSphere DataStage TerminologyYou should be familiar with these IBM WebSphere DataStage terms:
|
Term |
Definition |
|
Administrators |
Administrators maintain and configure DataStage projects. |
|
Aggregator Stages |
Aggregator stages compute totals or other functions of sets of data. |
|
Data Elements |
Data elements specify the type of data in a column and how the data is converted. |
|
Container Stages |
Container stages group reusable stages and links in a job design. |
|
DataStage Package Installer |
This tool enables you to install packaged DataStage jobs and plug-ins. |
|
Hashed File |
A hashed file groups one or more related files plus a file dictionary. DataStage creates hashed files when you run a job that creates hash files (these are delivered with PeopleSoft EPM). Hashed files are useful for storing data from tables from a remote database if they are queried frequently, for instance, as a lookup table. |
|
Hashed File Stage |
A hashed file stage extracts data from or loads data into a database containing hashed files. You can also use hashed file stages as lookups. PeopleSoft ETL jobs use hashed files as lookups. |
|
Inter-process Stage |
An inter-process stage allows you to run server jobs in parallel on a symmetric multiprocessing system. |
|
Plug-in Stages |
Plug-in stages perform processing that is not supported by the standard server job stage. |
|
Sequential File Stage |
A sequential file stage extracts data from or writes data to a text file. |
|
Transform Function |
A transform function takes one value and computes another value from it. |
|
Transformer Stages |
Transformer stages handle data, perform any conversions required, and pass data to another stage. |
|
Job |
A job is a collection of linked stages, data elements, and transforms that define how to extract, cleanse, transform, integrate, and load data into a target database. Jobs can either be server or mainframe jobs. |
|
Job Sequence |
Job sequence invokes and runs other jobs. |
|
Join Stages |
Join stages are mainframe processing stages or parallel job active stages that join two input sources. |
|
Metadata |
Metadata is data about data; for example, a table definition describing columns in which data is structured. |
DataStage ServerThe IBM WebSphere DataStage server enables you to schedule and run your ETL jobs:

DataStage Sever
Three components comprise the DataStage server:
Repository
The Repository stores all the information required for building and running an ETL job.
DataStage Server
The DataStage Server runs jobs that extract, transform, and load data into the warehouse.
DataStage Package Installer
The DataStage Package Installer installs packaged jobs and plug-ins.
DataStage ClientThe IBM WebSphere DataStage client enables you to administer projects, edit repository contents, and create, edit, schedule, run, and monitor ETL jobs.
Three components comprise the DataStage client:
DataStage Administrator
DataStage Designer
DataStage Director
DataStage Administrator
The DataStage Administrator enables you to:

DataStage Administrator
See Using DataStage Administrator.
DataStage Designer
DataStage Designer enables you to:
Create, edit, and view objects in the metadata repository.
Create, edit, and view data elements, table definitions, transforms, and routines.
Import and export DataStage components, such as projects, jobs, and job components.
Create ETL jobs, job sequences, containers, routines, and job templates.
Create and use parameters within jobs.
Insert and link stages into jobs.
Set stage and job properties.
Load and save table definitions.
Save, compile, and run jobs.
DataStage Director
DataStage Director enables you to:
Validate jobs.
Schedule jobs.
Run jobs.
Monitor jobs.
View log entries and job statistics.
Key DataStage Components
IBM WebSphere DataStage contains many different components that support the ETL process. Some of these components include stages, jobs, and parameters. Only the following key DataStage components are discussed in this section:
DSX Files
Jobs
Hashed Files
Environmental Parameters
Shared Containers
Routines
A complete list of all DataStage components can be found in the WebSphere DataStage Development: Designer Client Guide.
PeopleSoft delivers a *.dsx file for each functional area within EPM. As part of your installation and configuration process you import the *.dsx file into a project that has been defined in your development environment. Included in the *.dsx file are various DataStage objects that define your project. The *.dsx files are organized by functional area and contain related ETL jobs.
To see a list of the PeopleSoft-delivered *.dsx files, refer to the file "DSX Files Import Description.xls" located in the following install CD directory path: <PSHOME>\SRC\ETL.
Each delivered *.dsx file contains the DataStage objects described in the following sections.
PeopleSoft delivers predefined ETL jobs for use with IBM WebSphere DataStage. ETL Jobs are a collection of linked stages, data elements, and transformations that define how to extract, transform, and load data into a target database. Stages are used to transform or aggregate data, and lookup information. More simply, ETL jobs extract data from source tables, process it, then write the data to target warehouse tables.
PeopleSoft deliver five types of jobs that perform different functions depending on the data being processed, and the warehouse layer in which it is being processed:
|
Load Stage |
Type |
Description |
|
I |
Source to OWS |
Jobs in this category extract data from your PeopleSoft transaction system and populate target warehouse tables in the OWS layer of the warehouse. Source to OWS jobs assign a source system ID (SRC_SYS_ID) for the transaction system from which you are extracting data and populate the target OWS tables with that ID. |
|
I |
Source to MDW |
Jobs in this category extract data from your transaction system and populate target dimension and fact tables in the MDW layer of the warehouse. The Online Marketing data mart is the only product to use this type of job. |
|
II |
OWS to OWE |
Jobs in this category extract data from the OWS tables and populate target D00, F00, and base tables in the OWE layer of the warehouse. OWS to OWE jobs perform lookup validations for the target OWE tables to ensure there are no information gaps and maintain referential integrity. Many of the jobs aggregate your transaction data for the target F00 tables. |
|
II |
OWS to MDW |
Jobs in this category extract data from the OWS tables and populate target DIM and FACT tables in the MDW layer of the warehouse. OWS to MDW jobs generate a surrogate key that helps facilitate dimension key resolution. The surrogate key value is used as the primary key in the target DIM table and as the foreign key in the FACT table. The jobs also perform lookup validations for the target DIM and FACT tables to ensure there are no information gaps and maintain referential integrity. |
|
II |
OWE to MDW |
Jobs in this category extract data from the OWE tables and populate target DIM and FACT tables in the MDW layer of the warehouse. Properties of this job type mirror those of the OWS to MDW job. OWE to MDW jobs generate a surrogate key that helps facilitate dimension key resolution. The surrogate key value is used as the primary key in the target DIM table and as the foreign key in the FACT table. The jobs also perform lookup validations for the target DIM and FACT tables to ensure there are no information gaps and maintain referential integrity. |
All job types identified in the table are incremental load jobs. Incremental load jobs identify and extract only new or changed source records and bring it into target warehouse tables.
See Understanding ETL Load Strategies in EPM.
ETL Jobs - Naming Convention
PeopleSoft use standard naming conventions for all ETL jobs; this ensures consistency across different projects. The following table provides the naming conventions for PeopleSoft delivered ETL jobs.
|
Object |
Naming Convention |
Example |
|
Staging Server Job |
J_Stage_[Staging Table Name]_[Source Release]_[EPM Release] |
J_Stage_PS_AGING_TBL_FSCM91_EPM91 |
|
Sequencer Job |
SEQ_[Staging Table Name]_[Source Release]_[EPM Release] |
SEQ_J_Stage_PS_AGING_TBL_FSCM91_EPM91 |
|
CRC Initial Load Job |
J_Hash_PS_[Staging Table Name]_[Source Release]_[EPM Release] |
J_Hash_PS_AGING_TBL_FSCM91_EPM91 |
|
Common Lookup Load Job |
J_Hash_PS_[Table Name] |
J_Hash_PS_D_LRNG_ENV |
|
MDW Dimension Job |
J_Dim_PS_[Dimension Table Name] |
J_Dim_PS_D_DEPT |
|
MDW Fact Job |
J_Fact_PS_[Fact Table Name] |
J_Fact_PS_F_ENRLMT |
|
OWE Dimension Job |
J_D00_PS_[D00 Table Name without D00 Suffix] |
J_D00_PS_ACCOMP_D00 |
|
OWE Fact Job |
J_F00_PS_[F00 Table Name without F00 Suffix] |
J_F00_PS_JOB_F00 |
|
OWE Base Job |
J_BASE_PS_[Base OWE Table Name] |
J_BASE_PS_XYZ |
Hash files are views of specific EPM warehouse tables and contain only a subset of the data available in the warehouse tables. These streamlined versions of warehouse tables are used to perform data validation (lookups) within an ETL job and select specific data from lookup tables (such as sourceID fields in dimensions).
In the validation (lookup) process the smaller hash file is accessed, rather than the base warehouse table, improving performance. The following diagram provides an example of a hash file lookup in a job.
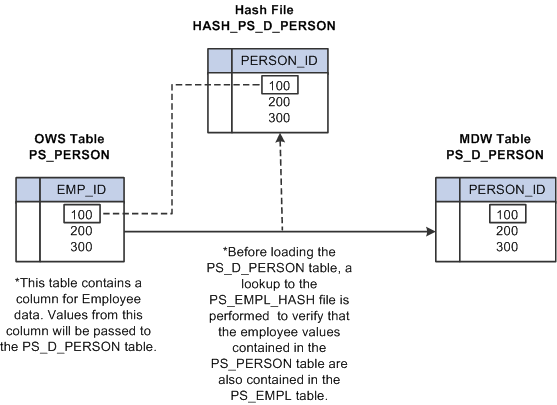
Lookup process using hash file
The following detailed view of an ETL job shows the Institution hashed file lookup in the Campus Solutions Warehouse J_Fact_PS_F_STU_RECRT job.
A detailed view of the hashed file stage reveals the fields (including keys) the lookup uses to validate Institution records.
Because hash files are vital to the lookup process, jobs cannot function properly until all hash files are created and populated with data. Before you run any job that requires a hash file, you must first run all jobs that create and load the hash files—also called initial hash file load jobs.
After hash files are created and populated by the initial hash file load jobs, they are updated on a regular basis by the delivered sequencer jobs. Hash files are updated in the same job as its related target warehouse table is updated. In other words, both the target warehouse table and the related hash file are updated in the same sequencer job. The successful load of the target warehouse table in the job triggers the load of the related hash file. The following diagram provides an example of the this process.
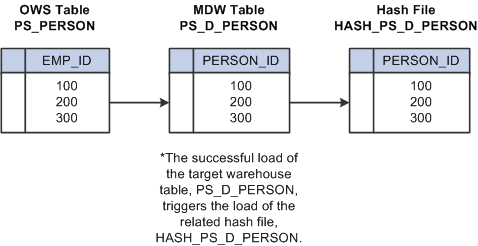
Hash file update process
See Understanding Data Validation and Error Handling in the ETL Process, Incremental Loading Using the Insert Flag and Lookup Validations.
Environmental parameters are user-defined values that represent processing variables in your ETL jobs. Environmental parameters are reusable so they enable you to define a processing variable once and use it in several jobs. They also help standardize your jobs.
Though environmental parameters are reusable, PeopleSoft delivers specific environmental parameters for jobs related to each phase of data movement (such as the OWS to MDW jobs). Therefore, a single environmental parameter is not used across all ETL jobs, rather a subset of variables are used depending on the specific functionality of the job.
See Environmental Parameters Information.
Shared containers are reusable job elements. A shared container is usually comprised of groups of stages and links, and is stored in the DataStage repository. You can use shared containers to make common job components available throughout your project. Because shared containers are reusable you can define them once and use them in any number of your ETL jobs. PeopleSoft delivers the following shared containers:
StoreLangStagingList
StoreMaxLastUpdDttm
StoreMaxRecordID
StorMaxSnapDate
StoreMaxValueDecimal
FactStoreMaxRecordID
Routines are a set of instructions, or logic, that perform a task within a job. For example, the ToInteger routine converts the input value to an integer. Because routines are reusable you can use them in any number of your ETL jobs.
See Routine Descriptions.
IBM Documentation
For more details on the IBM WebSphere DataStage tool and how to use it, refer to the IBM documentation listed below. You can install PDF versions of the IBM books as part of the IBM WebSphere tools install.
The following table lists the IBM documentation and the information provided.
Understanding ETL Load Strategies in EPM
This section provides an overview of ETL load strategies in EPM and discusses:
Incremental loading using the datetime stamp
Incremental loading using Cyclical Redundancy Check (CRC) logic
Incremental loading using the insert flag and lookup validations
Overview of ETL Load Strategies in EPMPeopleSoft delivers ETL jobs that extract data from your source transaction system and load it into target OWE and MDW dimension and fact tables. These jobs employ an incremental load strategy, which uses built-in logic to identify and load only new or updated source records. The benefit of the incremental load process is increased efficiency and faster processing during the extract and load process.
There are three types of incremental load strategies employed in PeopleSoft ETL jobs:
Incremental loading using the datetime stamp
Incremental loading using Cyclical Redundancy Check (CRC) logic
Incremental loading using the insert flag and lookup validations
Note. If this is the first time you are populating your target warehouse tables with data, the incremental jobs recognize that you have no existing data in your tables and perform a complete extract of your source records. Subsequent runs of the incremental jobs will extract only new or changed records.
Incremental Loading with the DateTime Stamp
To ensure only new or changed records are extracted, EPM target tables associate a datetime stamp with each record. Please note that the datetime stamp may appear as DTTM or DT_TIMESTAMP, depending on the source from which the record originates.
When an incremental load job reads a table, it uses a built-in filter condition, [DTTM_Column] > [%DateTimeIn('#LastModifiedDateTime#')] for example, to determine whether any records in the table are new or changed since the last load. The last update date time is retrieved from the related hashed file using the GetLastUpdDateTime routine. If the retrieved date time is less than the current value in the DTTM column, the record will be updated in the EPM table. This process can be done quickly because the DTTM column is the only value being processed for each record.
Each time a new or updated record is loaded, the present date time stamp is recorded for the last update time stamp and is used as a basis for comparison the next time the incremental load job is run.
Note. If the last update time field is null for a record, the record is processed each time the job is executed.
Incremental Loading Using Cyclical Redundancy Check
Some source table records do not have a date timestamp column. When source table records lack a date time stamp, a cyclical redundancy check (CRC) must be performed to determine new or changed records. Unlike incremental loading that targets the DTTM column for each record, the CRC process must read the entire record for each record in the source table and generate a CRC value, which it uses to compare against the target warehouse record.
Note. In the next section, the student note titled, "Examining the OWS Job: J_STAGE_PS_S_CAL_DEFN_TBL_FSCM91_EPM91" provides an example of CRC logic in a job.
Incremental Loading Using the Insert Flag and Lookup Validations
To ensure only new or changed records are loaded to EPM target tables, some jobs use an insert flag in combination with lookup validations. The following example will illustrate this process.
In the job J_Fact_PS_F_KK_FS_RCVD, the Trans_Assign_Values transformation contains the processing logic used to load new or updated records to the target table:
A closer look at the Trans_Assign_Values transformation shows that the Trans_Assign_Values_out and Trans_Assign_Values_update constraints are used to filter new or updated records:
The Trans_Assign_Values_out constraint will insert a new record when the InsertFlag is set to 'Y' and the ErrorFound flag is set to 'N.'
The Trans_Assign_Values_upd constraint will update a record when the InsertFlag is set to 'N' and the ErrorFound flag is set to 'N.'
Looking at the stage variables in the same transformation, note that the InsertFlag value (Y or N) is set based on the HASH_PS_F_KK_FS_RCVD_LKP:
The HASH_PS_F_KK_FS_RCVD_LKP uses incoming values for the source keys KK_FS_SID and SEQ_NBR to determine the SID value for each row of fact data. If the lookup returns a null SID value based on the source keys, the InsertFlag is set to 'Y' (insert a new record). If the lookup returns an existing SID value based on the source keys, the InsertFlag is set to 'N' (update existing record).
Also note that the ErrorFound flag value (Y or N) is set based on the ErrorFoundFundSource stage variable. However, the value of the ErrorFoundFundSource stage variable is determined in an earlier transformation, the Trans_SID_Lkp transformation:
Looking at the ErrorFoundFundSource stage variable in the same transformation, note that its value is set based on the HASH_D_KK_FUND_SOURCE_LKP:
The HASH_D_KK_FUND_SOURCE_LKP uses incoming values for the source keys FUND_SOURCE and SRC_SYS_ID to determine the SID value for each row of fact data. If the lookup returns a null SID value based on the source keys, the ErrorFoundFundSource is set to 'Y' (error found). If the lookup returns an existing SID value based on the source keys, the ErrorFoundFundSource is set to 'N' (no error).
Note. Normally the $ERR_VALIDATE parameter is set to 'Y.' By default EPM is delivered with the value set to Y, which means that records failing validation are moved an error table.
Special Load Requirements
The complex process behind integrating and aggregating disparate source data can create some special load requirements in EPM. For example, subrecords are used extensively in EPM target tables to provide additional depth and breadth of processing.
Passing Default Values to EPM Target Tables
Due to data aggregation and other processing requirements, EPM target tables may contain columns that do not exist in your source transaction tables. Because of the differences between source and EPM columns, there are sometimes no source values to populate the EPM columns. Therefore, default values must be used to populate the EPM columns instead.
|
Warehouse Layer |
Data Type |
Default Value |
|
OWS |
Char |
'-' |
|
Num |
0 |
|
|
Date |
Null |
|
|
OWE |
Char |
' ' |
|
Num |
0 |
|
|
Date |
Null |
|
|
MDW |
Char |
'-' |
|
Num |
0 |
|
|
Date |
Null |
For MDW fact records, fact rows coming from the source normally contain a valid reference to an existing row in the dimension table, in the form of a foreign key using a business key field. However, occasionally a fact row does not contain the dimension key. To resolve this issue, each MDW dimension contains a row for Value Not Specified, with predefined key values of zero—for a missing numeric value—and a hyphen—for a missing character value.
PeopleSoft delivers several routines to pass default values to the EPM columns. For example, the routine GetNumDefault is used to pass numeric default values to a target warehouse table. A separate routine is delivered for each data type (such as varchar and numeric).
Subrecords are a collection of specific columns that repeat across multiple EPM target tables. Subrecords can perform a variety of functions, including tracking data to its original source and facilitating customizations that enable type 2 slowly changing dimensions. For example, the subrecord LOAD_OWS_SBR contains columns such as CREATED_EW_DTTM, LAST_UPD_DTTM, and BATCH_SID which help track target warehouse table load history.
It is important to populate subrecords with the appropriate data. Thus, it is important that you thoroughly familiarize yourself with the PeopleSoft delivered subrecords and their associated columns.
Understanding Data Validation and Error Handling in the ETL Process
Accurate reporting is completely dependent on the data stored in data warehouse OWE and MDW tables; if incomplete or incorrect data resides in these tables, reporting and analysis can be flawed. Given the considerable dependence on data in EPM tables, all source data entering EPM must be validated.
Data validations are performed when you run ETL jobs. Because we want to ensure that complete, accurate data resides in the OWE and MDW tables, data validations are embedded in the jobs that load data from the OWS to the OWE and MDW. Therefore, data that passes the validation process is loaded into OWE and MDW target tables, while data that fails the validation process is redirected to separate error tables in the OWS. This ensures that flawed data never finds its way into the target OWE and MDW tables.
Error tables log the source values failing validation to aid correction of the data in the source system. There is an error table for each OWS driver table. OWS driver tables are those tables that contain the primary information for the target entity (for example customer ID).
Data Completeness Validation and Job Statistic Summary for Campus Solutions, FMS, and HCM Warehouses
A separate data completeness validation and job statistic capture is performed against the data being loaded into Campus Solutions, FMS, and HCM MDW tables (for example, validating that all records, fields, and content of each field is loaded, determining source row count versus target insert row count, and so forth). The validation and job statistic tracking is also performed in ETL jobs. The data is output to the PS_DAT_VAL_SMRY_TBL and PS_DATVAL_CTRL_TBL tables with prepackaged Oracle Business Intelligence (OBIEE) reports built on top of the tables.
See Oracle's Fusion Campus Solutions Intelligence for PeopleSoft 9.1 Preface.
Describing the Data Validation MechanismThe following graphic represents the data validation-error handling process in the PeopleSoft delivered J_DIM_PS_D_DET_BUDGET job:
Note that two hashed file validations are performed on the source data: the HASH_PS_PF_SETID_LOOKUP (which validates SetID) and HASH_PS_D_DT_PATTERN (which validates pattern code). Any data failing validation of these lookups is sent to the OWS error table (DRS_PS_ES_CAL_BP_TBL) via the Load_Error_PF_SETID_LOOKUP and Load_Error_D_DT_PATTERN_LOOKUP.
A closer look at the stage variables in the Trans_Gen_Key transformer stage demonstrate how the data validation process works (open the stage, then click the Show/Hide Stage Variables button on Transformer toolbar):
Note that the ErrorFoundSetID and ErrorFoundDDTPATTERN stage variable derivations are set to Y if the SETID lookup or pattern code validations fail.
The value of the ErrorFound stage variable, however, depends on the values of the ErrorFoundSetID and ErrorFoundDDTPATTERN stage variables, as well as the value of the $ERR_VALIDATE parameter, which can be configured to Y or N. If the $ERR_VALIDATE parameter is set to Y, rows that fail validation are written to the error table. If the value is set to N, rows that fail validation still pass to the target table.
Also note the AbortJob stage variable derivation uses the $ERR_THRESHOLD parameter to limit the number of error records allowed in the job. If the number of error records exceed the value set for the $ERR_THRESHOLD parameter, the job automatically aborts. For example, if $ERR_THRESHOLD is set to 50, the job aborts if the number of records with errors exceeds 50. You can set the value of the $ERR_THRESHOLD parameter to meet your specific business requirements.
Using the SetID lookup validation as an example, if a record fails validation, a Y value is assigned to the ErrorFoundSetID stage variable. If the $ERR_VALIDATE parameter is also set to Y, the failed record is sent to the PS_ES_CAL_BP_TBL error table.
For records that pass validation, an N value is assigned to the ErrorFound stage variable and the records are sent to the target table.
Disabling Data Validation
You can disable error validation in OWS jobs by configuring the value of the $ERR_VALIDATE parameter. By default the value is set to Y, which means that records failing validation are moved an error table. If you set the $ERR_VALIDATE value to N, records failing validation will still pass to the target table.
Describing the Data Completeness Validation and Job Statistic Summary
MechanismThe ETL component of the new data validation feature can be found using the following navigation in the DataStage Designer repository window: Jobs, Data_Validation.
Data Validation - Job Summary Data
The ETL logic for the new data validation feature is contained in a reusable, common component called SEQ_J_Handle_DATA_VALIDATION, which is a sequencer job:
Since the logic is reusable, the sequencer job is incorporated into all the existing sequencer jobs that load the MDW. Also, because the logic is contained within a sequencer job, there is no need to modify existing server jobs to implement the logic.
Here is the SEQ_J_Handle_DATA_VALIDATION sequencer job incorporated into an existing sequencer job for the Campus Solutions Warehouse, SEQ_J_Fact_PS_F_ADM_APPL_STAT:
Note. If you have customized your ETL jobs, you can implement the new data validation component simply by attaching it to the associated sequencer job.
The SEQ_J_Handle_DATA_VALIDATION sequencer job consists of the following server jobs:
J_Load_PS_DATA_VALIDATE_ERRTBL
J_Load_PS_DATA_VALIDATE_NOERRTBL
J_Load_DATAVALIDATE_NOTARGET
J_Load_PS_DATA_VALIDATE_ERRTBL_NOTARGET
A closer look at these server jobs shows that they load the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table:
The Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table consolidates all your job run statistic and error data, and is used as the foundation for the delivered data validation OBIEE reports (which are discussed in a separate section below).
The following graphic and table provide a more detailed look at the columns included in the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table:
|
Column |
Description |
|
JOB_NAME |
Populated with the server job name for each job run. This is a composite Primary Key. |
|
BATCH_SID |
Contains the BATCH_SID for the corresponding job run. This is a composite Primary Key. |
|
SRC_COUNT |
Contains the row count from the source that was extracted by the job. |
|
TGT_INS_COUNT |
Contains the row count for rows inserted into the target table by the job. |
|
TGT_UPD_COUNT |
Contains the row count for rows updated in the target table by the job. |
|
TGT_DEL_COUNT |
Contains the row count for rows deleted from the target table by the job. |
|
ERROR_ROWS |
Contains the count of unique rows from the source that failed to load the target due to lookup validation failure. Will default to '-' when:
|
|
JOB_START_DTTM |
Contains the server job start time. This will be the LASTUPD_EW_DTTM in the target tables. |
|
JOB_END_DTTM |
Contains the server job end time. |
|
JOB_RUN_STATUS |
Contains the run status of a job and whether the data has been loaded into the target completely. Job run status values are:
Note. Even if data validation is disabled for a job, job run status is still captured so that you can use the delivered Job Run Statistics OBIEE report to monitor job status. |
|
DATA_VAL_FLAG |
Flag indicating whether the data validation flag is enabled or disabled for the server job. |
|
ERROR_DETAILS |
Contains the error table names and total count of rows loaded into each error table. When no rows are loaded into error table it will be defaulted to "-" |
|
LASTUPDOPRID |
Contains the DataStage user information who triggered or ran the job. |
|
TARGET_TABLE |
Contains the target table name to which data was loaded. |
Data Validation - Job Statistic Data
The SEQ_J_Handle_DATA_VALIDATION sequencer job also includes a mechanism to capture job statistic data. Note that within the sequencer job is the routine GetJobCntrlInfo:
The GetJobCntrlInfo routine retrieves job information (such as error table and exception flag) from the Data Validation Control (HASH_PS_DATVAL_CTRL_TBL) hashed file:
The job information in the hashed file is also used by the server jobs that load the Data Validation Summary (PS_DAT_VAL_SMRY_TBL) table.
The Data Validation Control (PS_DATVAL_CTRL_TBL) table stores job statistic data for each OWS to MDW job run, such as source count, target count, error count, and error table list. The table is delivered prepopulated with the necessary data for the ETL jobs that perform data validation.
Note. If you have customized your ETL Jobs, you must manually update/insert data for the customized job in the PS_DATVAL_CTRL_TBL table and then run the J_Hash_PS_DATVAL_CTRL_TBL server job to update the related hashed file. EPM development provides a process document on how to perform these tasks.
The following graphic and table provide a more detailed look at the columns included in the Data Validation Control (PS_DATVAL_CTRL_TBL) table:
|
Column |
Description |
|
JOB_NAME |
Populated with the server job name that loads the OWS and MDW table. This is a primary key in this table. |
|
SEQ_JOB_NAME |
Populated with the Sequencer Name of the server job. |
|
SOURCE_TBL_LIST |
Contains the list of source table names used in the job. |
|
TARGET_TBL_LIST |
Contains the list of target target table names used in the job. This column may also contain parameter names when the target table is parameterized. |
|
ERROR_TBL_LIST |
Contains the list of error tables populated in the job. |
|
TGT_DEL_STG_LNK |
Identifies the active stage that precedes the DRS stage that performs a delete on target table, which is used to retrieve the target deleted row count. |
|
SRC_ACT_STG_LNK |
Identifies the active stage that succeeds the source DRS stage, which is used to retrieve the source row count. |
|
ERR_TBL_QRY |
Contains the error table query that is used to fetch the count of unique errors rows that failed to load the target. |
|
EXCEPTION_FLAG |
Contains 'Y' for jobs when source row count might not tally with the sum of target and error row counts (due to functional or job design). Otherwise, contains 'N.' |
|
GEN_SQL_FLAG |
Contains 'Y' if DRS stage uses generated sql query. Otherwise, contains 'N' if DRS stage uses user-defined SQL query. |
|
JOB_CATEGORY |
Contains the category (folder) information in the DataStage Project Repository for the job. |
|
WH_NAME |
Contains the EPM Warehouse name related to the job. The data validation component uses this value to select the appropriate parameter file at runtime. |
|
MART_NAME |
Contains the data mart name that corresponds to the parent EPM Warehouse, for the job run. |
|
JOB_TYPE |
Contains the job type information for the job. Job type values include:
|
|
SUBJECT_NAME |
Contains the functional area that corresponds to the parent data mart, for the job. |
|
LASTUPDOPRID |
Contains the user information associated with the insert or update actions, for a given job. |
|
LASTUPDDTTM |
Contains the timestamp when data was last modified. |
The PS_DATVAL_CTRL_TBL is also used as a source in the J_Load_PS_DATVAL_JOB_ERR server job:
The J_Load_PS_DATVAL_JOB_ERR server job loads the Data Validation Job Error (PS_DATVAL_JOB_ERR) table, which contains specific error table information and corresponding source table information for each job. The data in the PS_DATVAL_JOB_ERR table is used to populate page prompt values in the Error Table reports, based on the job selected in the report.
Note. The J_Load_PS_DATVAL_JOB_ERR server job shown here is for illustrative purposes only, the job is not accessible within the DataStage job tree. PeopleSoft delivers the PS_DATVAL_JOB_ERR table populated with all the necessary data and the J_Load_PS_DATVAL_JOB_ERR server job is used by PeopleSoft only, it cannot be viewed within the DataStage job tree.
The following graphic and table provide a more detailed look at the columns included in the Data Validation Job Error (PS_DATVAL_JOB_ERR) table:
|
Column |
Description |
|
SEQ_NBR |
Contains the unique sequence number for each error table. |
|
JOB_NAME |
Populated with the server job name for each job run. |
|
ERROR_TABLE |
Contains the error table name related to the job. |
|
SOURCE_TABLE |
Contains the name of the source table used with a corresponding error table. |
|
LASTUPDOPRID |
Contains the user information associated with the insert or update actions, for a given job. |
Enabling or Disabling the Data Completion Validation Feature
The Data Validation and Error Reporting feature is designed as optional, and you can enable it or disable it for each staging job using the delivered parameter files. For example, you can access the HCM_DATA_VALIDATION_SETUP parameter file and change the DATA_VALIDATION value from 'N' (do not perform data validation) to 'Y' (perform data validation) for each job:
PeopleSoft delivers a separate parameter file for each EPM Warehouse and for Global/Common dimension jobs:
CS_DATA_VALIDATION_SETUP.txt
FMS_DATA_VALIDATION_SETUP.txt
HCM_DATA_VALIDATION_SETUP.txt
GLOBAL_DATA_VALIDATION_SETUP.txt
Understanding OWE Jobs
When you run the ETL jobs that migrate your data from OWS tables to OWE tables, the jobs convert source SetIDs and Business Units to Warehouse SetIDs and Business Units. Therefore, source business units are consolidated into a common Warehouse Business Unit and the OWE tables are Warehouse Business Unit and Warehouse SetID based.
This section provides an overview of OWE fact and dimension load jobs.
OWE Dimension Load Jobs
A typical OWE dimension job loads data from an OWS source table to a target OWE dimension table. The basic flow of an OWE dimension job starts with a DRS source stage and includes transformation stages to perform lookup validations against OWS or OWE tables, depending on the job requirements.
In the job J_BASE_PS_PRODUCT_TBL, a SetID lookup is performed since the target dimension table is Warehouse SetID based. Specifically, the Trans_SOURCE_SETID_TO_PF_SETID transformation contains the processing logic used to convert incoming source SetIDs to a Warehouse SetID:
A closer look at the Trans_SOURCE_SETID_TO_PF_SETID transformation shows that the SetID lookup is performed against the HASH_PS_PF_SETID_LOOKUP hashed file:
Note that the HASH_PS_PF_SETID_LOOKUP represents the PS_PF_SETID_LOOKUP table, which is one of the output tables populated when you run the Business Unit Wizard.
The HASH_PS_PF_SETID_LOOKUP uses incoming values for the source keys SRC_SYS_ID, SRC_RECNAME, SRC_SETID, and PF_RECNAME to determine the Warehouse SetID value for each row of dimension data. If the lookup returns a Warehouse SetID value based on the source keys, the Warehouse SetID is passed to the target dimension table DRS_PS_PRODUCT_TBL. If the lookup does not locate a Warehouse SetID value based on the source keys, the value is passed instead to the error table DRS_PS_E_S_PRODUCT_TBL.
OWE Fact Load Jobs
A typical OWE fact job loads data from an OWS source table to a target OWE fact table. The basic flow of an OWE fact job starts with a DRS source stage and includes transformation stages to perform lookup validations.
In the job J_F00_PS_LEDGER, a business unit lookup is performed since the target fact table is Warehouse Business Unit based. Specifically, the Trans_SRCBU_PFBU transformation contains the processing logic used to convert incoming source business units to a Warehouse Business Unit.
A closer look at the Trans_SRCBU_PFBU transformation shows that the business unit lookup is performed against the HASH_PS_PF_BUS_UNIT_MAP hashed file:
Note that the HASH_PS_PF_BUS_UNIT_MAP lookup represents the PS_PF_BUS_UNIT_MAP table, which is one of the output tables populated when you run the Business Unit Wizard.
The HASH_PS_PF_BUS_UNIT_MAP uses incoming values for the source keys SRC_SYS_ID and SETCNTRLVALUE to determine the Warehouse Business Unit value for each row of fact data. If the lookup returns a Warehouse Business Unit value based on the source keys, the Warehouse Business Unit is passed to the target fact table DRS_PS_LEDGER_F00. If the lookup does not locate a Warehouse Business Unit value based on the source keys, the value is passed instead to the error table DRS_PS_E_LEDGER_for_SETID_BUSINESS_UNIT.
Understanding MDW Jobs
This section provides an overview of MDW fact and dimension load jobs.
MDW Dimension Load Jobs
A MDW dimension job loads data from an OWS source table (or in some cases, an OWE table) to a target MDW dimension table. The basic flow of a MDW dimension job starts with a DRS source stage and includes transformation stages with data validation lookups, when necessary, using the SID.
SID validations work in the same manner as the data validations described in the Understanding Data Validation and Error Handling in the ETL Process section above, except the SID is the unique key identifier used. The job will also contain lookups for attribute values, such as description fields.
The following is an example of a typical MDW dimension load job.
Next the job performs a lookup on the target dimension table hash file to check if equivalent business keys are already present for each record. If the record is present, the existing SID is used. If the record is not present, a new SID is generated. The job loads valid data into the target DRS stage and updates the hash file used for incremental loading.
MDW Fact Load Jobs
A MDW fact job loads data from an OWS source table (or in some cases, an OWE table) to a target MDW fact table. The basic flow of a MDW fact job starts with a DRS source stage and includes transformation stages to validate values for SID lookup dimension tables.
Because transaction tables are based on business unit and some dimension tables are SETID based, sometimes a SETID indirection lookup must be performed against the SETCTRL table to obtain the corresponding SETID for the business unit, and then use the value for the lookup. These lookups provide the values for the SID columns in the fact tables. The MDW fact job performs data validation lookups and diverts records that fail the lookup to an OWS error table (in this case, the PS_ECAMPUS_EVENT error table).
Next, data transformations are sometimes performed in transformation stages, such as aggregation of values or string manipulation.
The HASH_PS_F_ADM_FUNNEL lookup is the final validation in this job and it is required for incremental loading of the MDW target fact table (PS_F_ADM_FUNNEL). This lookup fetches the CREATED_EW_DTTM value for records in the hashed file and determines whether equivalent business keys are already present. If a matching record exists in the hashed file, the same created date time is extracted from this lookup. The record is then updated in the target fact table. If the record is not present, a new record is inserted in the target fact table.
The job also updates the hash file used for incremental loads. A very small number of MDW fact load jobs use destructive loading, in which case the server job truncates the target table prior to loading data.