Understanding IBM WebSphere DataStage
PeopleSoft has an original equipment manufacturer (OEM) agreement with IBM for its WebSphere DataStage ETL tool and bundles this offering with PeopleSoft EPM. The IBM WebSphere DataStage tool uses ETL jobs to target specific data from a PeopleSoft source database and migrate it to the OWS, OWE, and MDW tables. IBM WebSphere DataStage is comprised of a server tool and client tool, which are discussed in more detail below.
IBM WebSphere DataStage provides the following features:
Graphical design tools for designing ETL maps (called jobs)
Data extraction from a variety of data sources
Data aggregation using SQL SELECT statements
Data conversion using predefined or user-defined transformations and functions
Data loading using predefined or user-defined jobs
IBM WebSphere DataStage Terminology
You should be familiar with these IBM WebSphere DataStage terms:
|
Term |
Definition |
|---|---|
|
Administrators |
Administrators maintain and configure DataStage projects. |
|
Aggregator Stages |
Aggregator stages compute totals or other functions of sets of data. |
|
Data Elements |
Data elements specify the type of data in a column and how the data is converted. |
|
Container Stages |
Container stages group reusable stages and links in a job design. |
|
DataStage Package Installer |
This tool enables you to install packaged DataStage jobs and plug-ins. |
|
Hashed File |
A hashed file groups one or more related files plus a file dictionary. DataStage creates hashed files when you run a job that creates hash files (these are delivered with PeopleSoft EPM). Hashed files are useful for storing data from tables from a remote database if they are queried frequently, for instance, as a lookup table. |
|
Hashed File Stage |
A hashed file stage extracts data from or loads data into a database containing hashed files. You can also use hashed file stages as lookups. PeopleSoft ETL jobs use hashed files as lookups. |
|
Inter-process Stage |
An inter-process stage allows you to run server jobs in parallel on a symmetric multiprocessing system. |
|
Plug-in Stages |
Plug-in stages perform processing that is not supported by the standard server job stage. |
|
Sequential File Stage |
A sequential file stage extracts data from or writes data to a text file. |
|
Transform Function |
A transform function takes one value and computes another value from it. |
|
Transformer Stages |
Transformer stages handle data, perform any conversions required, and pass data to another stage. |
|
Job |
A job is a collection of linked stages, data elements, and transforms that define how to extract, cleanse, transform, integrate, and load data into a target database. Jobs can either be server or mainframe jobs. |
|
Job Sequence |
Job sequence invokes and runs other jobs. |
|
Join Stages |
Join stages are mainframe processing stages or parallel job active stages that join two input sources. |
|
Metadata |
Metadata is data about data; for example, a table definition describing columns in which data is structured. |
DataStage Server
The IBM WebSphere DataStage server enables you to schedule and run your ETL jobs:
Image: DataStage Sever
This diagram illustrates the DataStage Server

Three components comprise the DataStage server:
Repository
The Repository stores all the information required for building and running an ETL job.
DataStage Server
The DataStage Server runs jobs that extract, transform, and load data into the warehouse.
DataStage Package Installer
The DataStage Package Installer installs packaged jobs and plug-ins.
DataStage Client
The IBM WebSphere DataStage client enables you to administer projects, edit repository contents, and create, edit, schedule, run, and monitor ETL jobs.
Three components comprise the DataStage client:
DataStage Administrator
DataStage Designer
DataStage Director
DataStage Administrator
The DataStage Administrator enables you to:
Image: DataStage Administrator
This diagram illustrates the tasks that can be performed by the DataStage Administrator.

See Setting DataStage Server Properties and Setting Project Properties.
DataStage Designer
DataStage Designer enables you to:
Create, edit, and view objects in the metadata repository.
Create, edit, and view data elements, table definitions, transforms, and routines.
Import and export DataStage components, such as projects, jobs, and job components.
Create ETL jobs, job sequences, containers, routines, and job templates.
Create and use parameters within jobs.
Insert and link stages into jobs.
Set stage and job properties.
Load and save table definitions.
Save, compile, and run jobs.
DataStage Director
DataStage Director enables you to:
Validate jobs.
Schedule jobs.
Run jobs.
Monitor jobs.
View log entries and job statistics.
Key DataStage Components
IBM WebSphere DataStage contains many different components that support the ETL process. Some of these components include stages, jobs, and parameters. Only the following key DataStage components are discussed in this topic:
DSX Files
Jobs
Hashed Files
Environmental Parameters
Shared Containers
Routines
A complete list of all DataStage components can be found in the WebSphere DataStage Development: Designer Client Guide.
DSX Files
PeopleSoft delivers a *.dsx file for each functional area within EPM. As part of your installation and configuration process you import the *.dsx file into a project that has been defined in your development environment. Included in the *.dsx file are various DataStage objects that define your project. The *.dsx files are organized by functional area and contain related ETL jobs.
Note that *.dsx files use the following naming convention:
<file_name>.dsx, for DataStage 8.1 customers.
For example, Common_Utilities.dsx.
<file_name>_85.dsx, for DataStage 8.5 customers.
For example, Common_Utilities_85.dsx.
To see a list of the PeopleSoft-delivered *.dsx files, refer to the file "DSX Files Import Description.xls" located in the following install CD directory path: <PSHOME>\SRC\ETL.
Each delivered *.dsx file contains the DataStage objects described in the following topics.
ETL Jobs
PeopleSoft delivers predefined ETL jobs for use with IBM WebSphere DataStage. ETL Jobs are a collection of linked stages, data elements, and transformations that define how to extract, transform, and load data into a target database. Stages are used to transform or aggregate data, and lookup information. More simply, ETL jobs extract data from source tables, process it, then write the data to target warehouse tables.
PeopleSoft deliver five types of jobs that perform different functions depending on the data being processed, and the warehouse layer in which it is being processed:
|
Load Stage |
Type |
Description |
|---|---|---|
|
I |
Source to OWS |
Jobs in this category extract data from your PeopleSoft transaction system and populate target warehouse tables in the OWS layer of the warehouse. Source to OWS jobs assign a source system ID (SRC_SYS_ID) for the transaction system from which you are extracting data and populate the target OWS tables with that ID. |
|
I |
Source to MDW |
Jobs in this category extract data from your transaction system and populate target dimension and fact tables in the MDW layer of the warehouse. The Online Marketing data mart is the only product to use this type of job. |
|
II |
OWS to OWE |
Jobs in this category extract data from the OWS tables and populate target D00, F00, and base tables in the OWE layer of the warehouse. OWS to OWE jobs perform lookup validations for the target OWE tables to ensure there are no information gaps and maintain referential integrity. Many of the jobs aggregate your transaction data for the target F00 tables. |
|
II |
OWS to MDW |
Jobs in this category extract data from the OWS tables and populate target DIM and FACT tables in the MDW layer of the warehouse. OWS to MDW jobs generate a surrogate key that helps facilitate dimension key resolution. The surrogate key value is used as the primary key in the target DIM table and as the foreign key in the FACT table. The jobs also perform lookup validations for the target DIM and FACT tables to ensure there are no information gaps and maintain referential integrity. |
|
II |
OWE to MDW |
Jobs in this category extract data from the OWE tables and populate target DIM and FACT tables in the MDW layer of the warehouse. Properties of this job type mirror those of the OWS to MDW job. OWE to MDW jobs generate a surrogate key that helps facilitate dimension key resolution. The surrogate key value is used as the primary key in the target DIM table and as the foreign key in the FACT table. The jobs also perform lookup validations for the target DIM and FACT tables to ensure there are no information gaps and maintain referential integrity. |
All job types identified in the table are incremental load jobs. Incremental load jobs identify and extract only new or changed source records and bring it into target warehouse tables.
ETL Jobs - Naming Convention
PeopleSoft use standard naming conventions for all ETL jobs; this ensures consistency across different projects. The following table provides the naming conventions for PeopleSoft delivered ETL jobs.
|
Object |
Naming Convention |
Example |
|---|---|---|
|
Staging Server Job |
J_Stage_[Staging Table Name]_[Source Release]_[EPM Release] |
J_Stage_PS_AGING_TBL_FSCM91_EPM91 |
|
Sequencer Job |
SEQ_[Staging Table Name]_[Source Release]_[EPM Release] |
SEQ_J_Stage_PS_AGING_TBL_FSCM91_EPM91 |
|
CRC Initial Load Job |
J_Hash_PS_[Staging Table Name]_[Source Release]_[EPM Release] |
J_Hash_PS_AGING_TBL_FSCM91_EPM91 |
|
Common Lookup Load Job |
J_Hash_PS_[Table Name] |
J_Hash_PS_D_LRNG_ENV |
|
MDW Dimension Job |
J_Dim_PS_[Dimension Table Name] |
J_Dim_PS_D_DEPT |
|
MDW Fact Job |
J_Fact_PS_[Fact Table Name] |
J_Fact_PS_F_ENRLMT |
|
OWE Dimension Job |
J_D00_PS_[D00 Table Name without D00 Suffix] |
J_D00_PS_ACCOMP_D00 |
|
OWE Fact Job |
J_F00_PS_[F00 Table Name without F00 Suffix] |
J_F00_PS_JOB_F00 |
|
OWE Base Job |
J_BASE_PS_[Base OWE Table Name] |
J_BASE_PS_XYZ |
Hashed Files
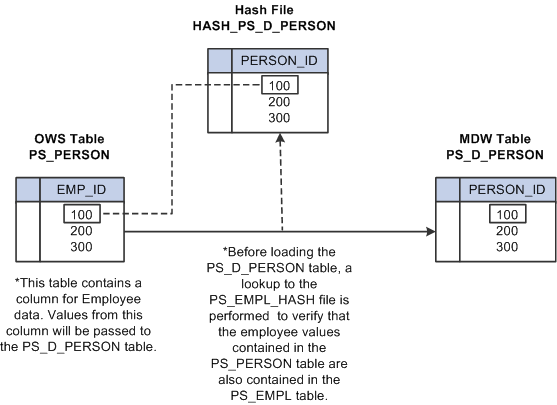
Hash files are views of specific EPM warehouse tables and contain only a subset of the data available in the warehouse tables. These streamlined versions of warehouse tables are used to perform data validation (lookups) within an ETL job and select specific data from lookup tables (such as sourceID fields in dimensions).
In the validation (lookup) process the smaller hash file is accessed, rather than the base warehouse table, improving performance. The following diagram provides an example of a hash file lookup in a job.
Image: Lookup process using hash file
The following diagram provides an example of a hash file lookup in a job.
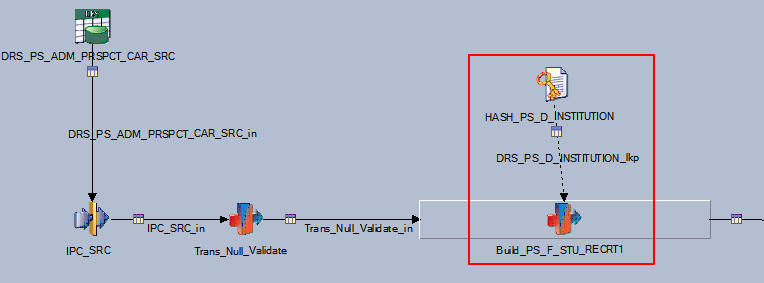
The following detailed view of an ETL job shows the Institution hashed file lookup in the Campus Solutions Warehouse J_Fact_PS_F_STU_RECRT job.
Image: Institution hashed file lookup in the J_Fact_PS_F_STU_RECRT job
This example illustrates the Institution hashed file lookup in the J_Fact_PS_F_STU_RECRT job.
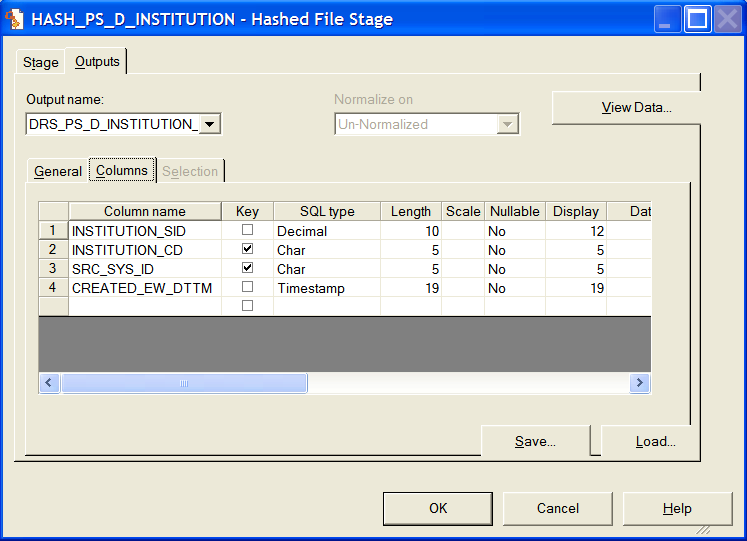
A detailed view of the hashed file stage reveals the fields (including keys) the lookup uses to validate Institution records.
Image: Hashed file stage in the J_Fact_PS_F_STU_RECRT job
This example illustrates the Hashed file stage in the J_Fact_PS_F_STU_RECRT job.
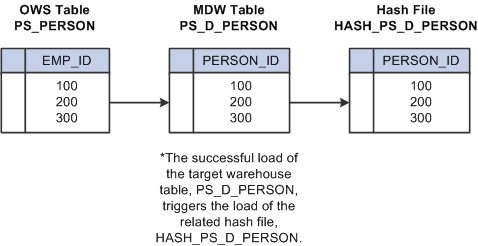
Because hash files are vital to the lookup process, jobs cannot function properly until all hash files are created and populated with data. Before you run any job that requires a hash file, you must first run all jobs that create and load the hash files—also called initial hash file load jobs.
After hash files are created and populated by the initial hash file load jobs, they are updated on a regular basis by the delivered sequencer jobs. Hash files are updated in the same job as its related target warehouse table is updated. In other words, both the target warehouse table and the related hash file are updated in the same sequencer job. The successful load of the target warehouse table in the job triggers the load of the related hash file.
Image: Hash file update process
The following diagram provides an example of the this process.
See Understanding Data Validation and Error Handling in the ETL Process, Incremental Loading Using the Insert Flag and Lookup Validations.
Environmental Parameters
Environmental parameters are user-defined values that represent processing variables in your ETL jobs. Environmental parameters are reusable so they enable you to define a processing variable once and use it in several jobs. They also help standardize your jobs.
Though environmental parameters are reusable, PeopleSoft delivers specific environmental parameters for jobs related to each phase of data movement (such as the OWS to MDW jobs). Therefore, a single environmental parameter is not used across all ETL jobs, rather a subset of variables are used depending on the specific functionality of the job.
Routines
Routines are a set of instructions, or logic, that perform a task within a job. For example, the ToInteger routine converts the input value to an integer. Because routines are reusable you can use them in any number of your ETL jobs.
See Routine Descriptions.
IBM Documentation
For more details on the IBM WebSphere DataStage tool and how to use it, refer to the IBM documentation listed below. You can install PDF versions of the IBM books as part of the IBM WebSphere tools install.
The following table lists the IBM documentation and the information provided.
|
IBM Book |
Description |
|---|---|
|
IBM Information Server: Planning Installation and Configuration Guide |
Provides planning information and complete installation instructions for IBM Information Server. Also includes information about troubleshooting, validating the installation, and configuring the system. |
|
IBM Information Server: Administration Guide |
Describes how suite administrators can manage user access to components and features of IBM Information Server. In addition, describes how suite administrators can create and manage views of logged events and scheduled tasks for all components. |
|
WebSphere DataStage Administration: Administrator Client Guide |
Describes the WebSphere DataStage Administrator client and describes how to perform setup, routine housekeeping, and administration of the WebSphere DataStage engine. |
|
WebSphere DataStage Administration: Deployment Guide |
Describes how to package and deploy WebSphere DataStage jobs and associated objects to assist in moving projects from development to production. |
|
WebSphere DataStage Administration: Director Client Guide |
Describes the WebSphere DataStage Director client and explains how to validate, schedule, run, and monitor WebSphere DataStage parallel jobs and server jobs. |
|
WebSphere DataStage Administration: National Language Support Guide |
Describes how to use the national language support (NLS) features that are available in WebSphere DataStage when NLS is installed. |
|
WebSphere DataStage Development: Designer Client Guide |
Describes the WebSphere DataStage Designer client and gives a general description of how to create, design, and develop a WebSphere DataStage application |
|
WebSphere DataStage Development: Server Job Developer Guide |
Describes the tools that build a server job, and supplies programming reference information |