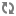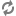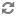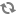Use the
CasCrawler.createCrawl() method to create a new crawl of
any type (file system, CMS crawl, record store merger, or custom data source).
The syntax of the method is:
CasCrawler.createCrawl(CrawlConfig crawlConfig)
The
crawlConfig parameter is a
CrawlConfig object that has the configuration
settings of the crawl.
To create a new crawl:
Make sure that you have created a connection to the CAS Server.
Instantiate a
CrawlIdobject and set the Id for the crawl in the constructor.You can create an Id with alphanumeric characters, underscores, dashes, and periods. All other characters are invalid for an Id.
For example:
// Create a new crawl Id with the name set to Demo. CrawlId crawlId = new CrawlId("Demo");Instantiate a
CrawlConfigobject and pass in theCrawlIdobject .For example:
// Create a crawl configuration. CrawlConfig crawlConfig = new CrawlConfig(crawlId);
Instantiate a
SourceConfigobjectFor example:
// Create source configuration. SourceConfig sourceConfig = new SourceConfig();
Set the source properties and seeds in the
SourceConfigobject. Detailed information on source properties is provided in other topics.Set the
SourceConfigon theCrawlConfig.For example:
// Set source configuration. crawlConfig.setSourceConfig(sourceConfig);
Optionally, you can set configuration options for such features as document conversion, logging, and filters for files and directories. Detailed information on these options is provided in other topics.
Create the crawl by calling
CasCrawler.createCrawl()and passing theCrawlConfig(the configuration) objects:For example:
crawler.createCrawl(crawlConfig);
If the
CasCrawler.createCrawl() method fails, it throws an
exception:
To catch these exceptions, use a
try block when you issue the method.
If the new crawl is successfully created, it can be started with the
CasCrawler.startCrawl() method.