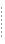| ドキュメントのダウンロード | サイトマップ | 用語集 | |
|
|||
| bea ホーム | 製品 | dev2dev | support | askBEA |
|
|
||||||||
| e-docs > Tuxedo > Tuxedo アプリケーション実行時の管理 > 分散アプリケーションでのネットワーク管理 |
|
Tuxedo アプリケーション実行時の管理
|
分散アプリケーションでのネットワーク管理
ここでは、次の内容について説明します。
分散アプリケーション用のネットワークの構築
分散アプリケーション用のネットワークを構築する作業は、主にコンフィギュレーション・フェーズまたはセットアップ・フェーズで行われます。ネットワークを定義し、アプリケーションを起動すると、ネットワークは自動的に構築されます。
この章では、ネットワークを介してデータを移動する方法と、ネットワークに関する操作を制御するコンフィギュレーション・ファイルのパラメータを設定する方法について説明します。
ネットワーク・データの圧縮
BEA Tuxedo システムでは、アプリケーションのプロセス間で送信されるデータを圧縮できます。データ圧縮は便利な機能であり、特に、大規模なコンフィギュレーションを運用する場合に重要です。データ圧縮は、同じマシン上でメッセージの送受信を行う場合 (ローカル・データ圧縮)、または異なるマシン間でメッセージの送受信を行う場合 (リモート・データ圧縮) に使用できます。データ圧縮には次の利点があります。
圧縮レベルの設定
データ圧縮を使用するには、コンフィギュレーション・ファイルの MACHINES セクションの CMPLIMIT パラメータを次のように設定する必要があります。
CMPLIMIT=string_value1[,string_value2]
このパラメータの文字列値には、リモート・プロセス (string_value1) およびローカル・プロセス (string_value2) で処理されるメッセージのサイズのしきい値を指定します。必須パラメータは最初の文字列値 (string_value1) のみです。どちらの文字列も、デフォルトは MAXLONG パラメータの値です。
TMCMPPRFM パラメータを設定して、圧縮と CPU のパフォーマンスとのバランスを調整することもできます。 圧縮レベルを高くすると、圧縮速度は下がりますがネットワーク帯域幅を効率的に利用できます。 圧縮レベルを低くすると、圧縮速度は上がり、CPU 使用率を節約できます。
圧縮レベルを指定するには、次の手順に従います。
TMCMPPRFM 変数の設定方法の詳細については、『ファイル形式、データ記述方法、MIB、およびシステム・プロセスのリファレンス』の tuxenv(5) を参照してください。
データ圧縮のしきい値の選択
メッセージに対して圧縮のしきい値を指定することができます。つまり、指定したしきい値を超えるメッセージは圧縮されます。圧縮のしきい値を指定するには、CMPLIMIT パラメータを設定します。設定の手順については、圧縮レベルの設定を参照してください。
データ圧縮のしきい値を選択する場合は、次の基準を参考にしてください。
ローカル・データ圧縮の場合、アプリケーション内の各マシンに対して、異なるしきい値を割り当てることができます。このような場合は、常に各マシンに対して下限値を選択する必要があります。
注記 IPC キューのブロッキングにより、タイムアウトとメッセージの破棄が頻繁に発生する高トラフィックのアプリケーションでは、ローカル圧縮が常に行われるように設定し、IPC のキューイング・サブシステム上のアプリケーションからの要求を少なくすることができます。
圧縮方法は転送されるデータの種類によって異なるため、環境に応じた最適な設定を行うことをお勧めします。
関連項目
ネットワーク要求のロード・バランシング
ロード・バランシングがオンになっている場合、つまりアプリケーション・コンフィギュレーション・ファイルの RESOURCES セクションで LDBAL が Y に設定されている場合、BEA Tuxedo システムは、リクエストをネットワーク全体に均衡化します。ロード情報はグローバルには更新されないため、各サイトにはリモート・サイトにおけるロードの独自のビューを持ちます。
コンフィギュレーション・ファイルの MACHINES セクションの NETLOAD パラメータ、または TMNETLOAD 環境変数を使用すると、より多くのリクエストをローカル・キューに送るよう強制できます。このパラメータの値はリモート・キューのロードに追加されるため、リモート・キューに実際より多くの作業があるように見えます。そのため、ロード・バランシングがオンになっていても、ローカル要求はリモート・キューよりもローカル・キューに頻繁に送られます。
たとえば、サーバ A とサーバ B がロード・ファクタ 50 のサービスを提供するとします。サーバ A は呼び出し側クライアント (ローカル) と同じマシン上で稼働しており、サーバ B は別のマシン (リモート) 上で稼働しています。NETLOAD を 100 に設定すると、1 つのリクエストがサーバ B に送られる度に約 3 つのリクエストがサーバ A に送られます。
ロード・バランシングに影響するもう 1 つのメカニズムは、アイドル状態のローカル・サーバが優先されるという点です。クライアントと同じマシン上にあるサーバが、希望するサービスを提供し、アイドル状態にある場合、このサーバにリクエストが送られます。ローカル・サーバは直ちに使用可能になるため、この機能はどんなロード・バランシングの設定より優先されます。
関連項目
データ依存型ルーティングの使用
データ依存型ルーティングは、クライアントが次のものにサービスを要求した場合に有用です。
水平分離型データベースは、情報を格納しておくリポジトリです。情報はカテゴリ別に保存されます。これは、各本棚に異なるカテゴリ (伝記、フィクションなど) の本が収納されている図書館に似ています。
ルール・ベース・サーバとは、サービス要求をサービス・ルーチンに転送する前に、サービス要求が特定のアプリケーション固有の条件を満たしているかどうかを判定するサーバです。ルール・ベース・サーバは、ほとんど同じ複数の要求に対して、ビジネス上の理由で多少異なる処理を行う場合に使用すると有用です。
注記 分散型 BEA Tuxedo CORBA アプリケーションのファクトリ・ベース・ルーティングについては、『BEA Tuxedo CORBA アプリケーションのスケーリング、分散、およびチューニング』を参照してください。
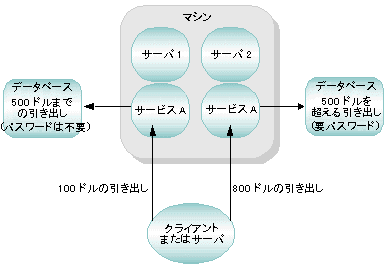
水平分離型データベースを使ったデータ依存型ルーティングの例
銀行取引アプリケーションで 2 つのクライアントが口座 3 と口座 17 という 2 つの口座の現在の残高を照会する要求を発行したとします。口座 3 と口座 17 という 2 つの口座の現在の残高を照会する要求を発行したとします。アプリケーションでデータ依存型ルーティングが使用されている場合、BEA Tuxedo システムでは次の処理が行われます。
次の図は、このプロセスを示しています。
図 4-1 水平分離型データベースを使ったデータ依存型ルーティング
ルール・ベース・サーバでのデータ依存型ルーティングの例 次の規則を持つ銀行取引アプリケーションがあるとします。
2 つのクライアントが1 万円と 8 万円の引き出しを要求したとします。引き出しの規則でデータ依存型ルーティングが有効になっている場合、BEA Tuxedo では次のような処理が行われます
次の図は、このプロセスを示しています。
図 4-2 ルール・ベース・サーバでのデータ依存型ルーティング
ネットワーク・コンフィギュレーションの変更
アプリケーションの稼働中にコンフィギュレーション・パラメータを変更するには、tmconfig(1) を実行します。このコマンドは、BEA Tuxedo システム管理情報ベース (MIB) へのシェル・レベルのインターフェイスです。
tmconfig を使用すると、システムを停止せずに TUXCONFIG ファイルの表示や変更を行うことができます。たとえば、アプリケーションの起動中にマシンやサーバなどの新しいコンポーネントを追加することができます。
関連項目
|

|

|