10g (9.0.4)
Part Number B12121-01
Home |
Solution Area |
Contents |
Index |
| Oracle® Application Server ProcessConnect User's Guide 10g (9.0.4) Part Number B12121-01 |
|
This appendix describes the native formats and translators supported with Oracle Application Server ProcessConnect.
This appendix contains these topics:
Oracle Application Server ProcessConnect provides prepackaged support for the following native formats and translators:
This support provides the following features:
The Oracle Application Server ProcessConnect user interface tool enables you to select document definitions specified in native formats when adding an interaction. Oracle Application Server ProcessConnect uses these document definitions to create a native event type and native event body elements. For example, if you select an XSD document that consists of a header, payload data, and attachment, Oracle Application Server ProcessConnect creates a native event type for the document and separate native event body elements for the header, payload data, and attachment. The XSD native format is also associated with an XSD translator, which translates the native event type and native event body elements into application event type and application event body elements for inbound messages, and translates application event type and application event body elements into native event type and native event body elements for outbound messages.
|
See Also:
The following sections for instructions on selecting a native format:
|
You can use the Oracle Application Server ProcessConnect user interface tool to import XSD native format datatypes by specifying the file that contains the datatype definitions.
|
See Also:
"Importing XSD Datatypes" for instructions on importing an XSD datatypes file. |
You can import XMLSchema definition (XSD) datatype files into Oracle Application Server ProcessConnect. While Oracle Application Server ProcessConnect does provide XSD support, there are XSD tags and attributes that are ignored, not supported, or supported only through workarounds. In addition, other XSD datatypes, datatype members, and attributes can only be added to Oracle Application Server ProcessConnect through XSD files and not through the Oracle Application Server ProcessConnect user interface tool.
The following sections describe Oracle Application Server ProcessConnect-specific characteristics for importing XSD datatype files:
See Also:
The following XSD tags are ignored by Oracle Application Server ProcessConnect. Importing an XSD file that contains these tags does not cause errors. The tags are simply ignored.
Table A-1 lists the XSD attributes ignored by Oracle Application Server ProcessConnect. Importing an XSD file that contains these attributes does not cause errors. The attributes are simply ignored.
You receive error messages if any of the following tags appear in an XMLSchema file being imported. This section describes existing workarounds for these tags.
This section contains the following topics:
all has attribute minOccurs with allowed values of 0 and 1, and attribute maxOccurs that must have a value of 1. Since all can only occur at the top level of complexType, and cardinality is not supported for complexType, minOccurs="0" is not supported.
Unsupported XSD Fragment:
<xs:complexType name="unsupported_3_1">
<xs:all minOccurs="0">
<xs:element name="m1" type="xs:int" minOccurs="0"/>
<xs:element name="m2" type="xs:string"/>
<xs:element name="m3" type="xs:string"/>
</xs:all>
</xs:complexType>
Corresponding Valid Instances:
<unsupported_3_1/> <unsupported_3_1> <m2>foo</m2> <m3>bar</m3> </unsupported_3_1> <unsupported_3_1> <m1>123</m1> <m2>foo</m2> <m3>bar</m3> </unsupported_3_1>
Change the minimum cardinality of each member to 0. This enables all originally valid instances to remain valid. However, this causes some instances that are not valid according to the original XSD to now become valid. This is because the original XSD fragment required that either all member elements with minOccurs="1" occur in the instance, or no member elements occur in the same instance, regardless of cardinality.
Modified XSD Fragment:
<xs:complexType name="workaround_3_1"> <xs:all> <xs:element name="m1" type="xs:int" minOccurs="0"/> <xs:element name="m2" type="xs:string"minOccurs="0"/> <xs:element name="m3" type="xs:string"minOccurs="0"/> </xs:all> </xs:complexType>
Corresponding Valid Instances:
All the valid instances from "Corresponding Valid Instances:" are still valid according to the modified XSD. However, the following invalid instances according to the original XSD are now also valid.
<workaround_3_1> <!-- according to the original, if the all group occurs, it must contain both m2 and m3 --> <m2>foo</m2> </workaround_3_1> <workaround_3_1> <!-- according to the original, if the all group occurs, it must contain both m2 and m3 --> <m1>123</m1> <m3>bar</m3> </workaround_3_1>
This section contains the following topics:
There is no support for attribute wildcards. No occurrence of anyAttribute is allowed in an XSD document.
There is no current workaround. Remove and replace all occurrences of anyAttribute from the XSD file with explicit declarations of the expected attributes.
This section contains the following topics:
Complex datatypes do not have cardinality; only their members do. If a choice or sequence group appears at the top level of a complexType (that is, its parent is complexType, restriction, extension, or group), it becomes the direct content of its parent complex datatype. There is no member that points to it, and thus no way to preserve the cardinality.
<xs:complexType name="unsupported_3_2_1"> <xs:choice minOccurs="0" maxOccurs="2"> <xs:element name="member1" type="xs:string"/> <xs:element name="member2" type="xs:string"/> </xs:choice> </xs:complexType> <xs:complexType name="unsupported_3_2_2"> <xs:sequence maxOccurs="unbounded"> <xs:element name="member1" type="xs:int"/> </xs:sequence> </xs:complexType>
Nest the block, complete with its minOccurs and maxOccurs, inside a sequence. This way, the original block is created as an anonymous complex datatype that has a compound member with the appropriate cardinality referencing it. This workaround does not impact the set of valid instances.
<xs:complexType name="unsupported_3_2_1"> <xs:sequence> <xs:choice minOccurs="0" maxOccurs="2"> <xs:element name="member1" type="xs:string"/> <xs:element name="member2" type="xs:string"/> </xs:choice> </xs:sequence> </xs:complexType> <xs:complexType name="unsupported_3_2_2"> <xs:sequence> <xs:sequence maxOccurs="unbounded"> <xs:element name="member1" type="xs:int"/> </xs:sequence> </xs:sequence> </xs:complexType>
This section contains the following topics:
mixed="true" in an XSD type means that the corresponding instance can have unrestricted simple content, complex content as specified in the type, or a mixture of both. There is no workaround for instances with mixed content. If instances either always have simple content or always have complex content, then there is a workaround.
Unsupported XSD Fragments:
<xs:complexType name="text" mixed="true"> <xs:sequence> <xs:element name="header" type="xs:string" minOccurs="0"/> <xs:element name="note" type="xs:string" minOccurs="0" maxOccurs="unbounded"/> <xs:element name="footer" type="xs:string" minOccurs="0"/> </xs:sequence> </xs:complexType>
Corresponding Valid Instances:
Since all member elements have minOccurs="0", an instance containing only scalar data is valid:
<text>here is some plain text</text>
It is also valid for the instance to contain only complex content:
<text> <header>text begins</header> <footer>text ends</footer> </text>
There is no support or workaround for mixed content instances such as this one in Oracle Application Server ProcessConnect:
<text>this text has no header, two notes, <note>note 1</note>, and <note>note 2</note>, and a footer <footer>end</footer></text>
Determine first whether instance data always has simple or complex content.
Workaround for instances that always have simple content:
If the mixed attribute occurs in a complexType tag, replace the complexType with a simpleType that restricts anySimpleType. For example, replace this mixed content type:
<xs:complexType name="text" mixed="true"> <xs:sequence> <xs:element name="header" type="xs:string" minOccurs="0"/> <xs:element name="note" type="xs:string" minOccurs="0" maxOccurs="unbounded"/> <xs:element name="footer" type="xs:string" minOccurs="0"/> </xs:sequence> </xs:complexType>
with the following:
<xs:simpleType name="text"><xs:restriction base="xs:anySimpleType"/></xs:simpleType>
If mixed occurs in a complexContent tag, replace complexContent with a simpleContent extension. Set the base to anySimpleType. Add all attributes of complexContent and its base type to simpleContent. For example, replace this mixed content type:
<xs:complexType name="baseType"> <xs:all> <xs:element name="name" type="xs:string" minOccurs="0"/> </xs:all> <xs:attribute name="sku" type="xs:string"/> </xs:complexType> <xs:complexType name="mixedType"> <xs:complexContent mixed="true"> <xs:extension base="baseType"> <xs:sequence> <xs:element name="type" type="xs:string" minOccurs="0"/> </xs:sequence> <xs:attribute name="id" type="xs:short"/> </xs:extension> </xs:complexContent> </xs:complexType>
with the following:
<xs:complexType name="mixedType"> <xs:simpleContent> <xs:extension base="xs:anySimpleType"> <xs:attribute name="sku" type="xs:string"/> <xs:attribute name="id" type="xs:short"/> </xs:extension> </xs:simpleContent> </xs:complexType>
Workaround for instances that always have complex content:
If every instance has complex content, remove the mixed="true" attribute. Using the examples in the previous section, the workarounds are as follows:
<xs:complexType name="text"> <xs:sequence> <xs:element name="header" type="xs:string" minOccurs="0"/> <xs:element name="note" type="xs:string" minOccurs="0" maxOccurs="unbounded"/> <xs:element name="footer" type="xs:string" minOccurs="0"/> </xs:sequence> </xs:complexType>
and
<xs:complexType name="mixedType"> <xs:complexContent> <xs:extension base="baseType"> <xs:sequence> <xs:element name="type" type="xs:string" minOccurs="0"/> </xs:sequence> <xs:attribute name="id" type="xs:short"/> </xs:extension> </xs:complexContent> </xs:complexType>
This section contains the following topics:
The list tag cannot occur in any XSD file being imported.
There is no current workaround. All list types must be removed from the XSD file.
This section contains the following topics:
The union tag cannot occur in any XSD being imported.
There is no current workaround. All union types must be removed from the XSD file.
This section contains the following topics:
simpleContent, both restriction and extension, is modeled as a complex datatype. Complex datatypes can only be derived by restriction from other complex datatypes, and not from scalar datatypes. Therefore, the base type of a simpleContent restriction must be a complexType.
<xs:complexType name="unsupported_3_4_1"> <xs:simpleContent> <xs:restriction base="xs:string"> <xs:attribute name="foo" type="xs:string"/> </xs:restriction> </xs:simpleContent> </xs:complexType> <xs:complexType name="unsupported_3_4_2"> <xs:simpleContent> <xs:restriction> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="4"/> </xs:restriction> </xs:simpleType> <xs:attribute name="bar" type="xs:string"/> </xs:restriction> </xs:simpleContent> </xs:complexType>
Declare a new complexType with simpleContent that extends the base simpleType. If the simpleType is locally defined, then it must be moved and defined as a global type. This new complexType can then be used as the base type for the original simpleContent restriction.
<xs:complexType name="helper_3_4_1"> <xs:simpleContent> <xs:extension base="xs:string"/> </xs:simpleContent> </xs:complexType> <xs:complexType name="unsupported_3_4_1"> <xs:simpleContent> <xs:restriction base="helper_3_4_1"> <xs:attribute name="foo" type="xs:string"/> </xs:restriction> </xs:simpleContent> </xs:complexType> <xs:simpleType name="simplehelper_3_4_2"> <xs:restriction base="xs:string"> <xs:length value="4"/> </xs:restriction> </xs:simpleType> <xs:complexType name="helper_3_4_2"> <xs:simpleContent> <xs:extension base="simplehelper_3_4_2"/> </xs:simpleContent> </xs:complexType> <xs:complexType name="unsupported_3_4_2"> <xs:simpleContent> <xs:restriction base="helper_3_4_2"> <xs:attribute name="bar" type="xs:string"/> </xs:restriction> </xs:simpleContent> </xs:complexType>
This section contains the following topics:
Since complex datatypes do not have facets, the restriction of facets in simpleContent is not supported. Therefore, restriction cannot have any of the following content: enumeration, length, maxExclusive, maxInclusive, maxLength, minExclusive, minInclusive, minLength, pattern, totalDigits, fractionDigits, and whiteSpace. This section describes only the case where the base type is a complexType with simpleContent. If the base type is a simpleType, see "restriction (simpleContent) if the base attribute refers to a simpleType or if it has a locally defined base simpleType".
<xs:simpleType name="simpleBase"> <xs:restriction base="xs:string"> <xs:minLength value="2"/> <xs:maxLength value="8"/> </xs:restriction> </xs:simpleType> <xs:complexType name="complexBase"> <xs:simpleContent> <xs:extension base="simpleBase"> <xs:attribute name="id" type="xs:short"/> </xs:extension> </xs:simpleContent> </xs:complexType> <xs:complexType name="unsupported_3_5"> <xs:simpleContent> <xs:restriction base="complexBase"> <xs:maxLength value="6"/> </xs:restriction> </xs:simpleContent> </xs:complexType>
You cannot preserve the inheritance tree along with the appropriate facets and attributes. Instead, remove the facets from the derived type. If the type must have those facets, then perform the following tasks:
simpleType with the exact facets needed.
complexType with simpleContent that extends the simpleType.
complexType as the base type for the simpleContent restriction.
In this case, all attributes must be explicitly declared in the restriction.
Workaround 1 (Removing facets):
<xs:complexType name="unsupported_3_5"> <xs:simpleContent> <xs:restriction base="complexBase"/> </xs:simpleContent> </xs:complexType>
Workaround 2 (Redefining the type):
<xs:simpleType name="simpleBase2"> <xs:restriction base="simpleBase"> <xs:maxLength value="6"/> </xs:restriction> </xs:simpleType> <xs:complexType name="complexBase2"> <xs:simpleContent> <xs:extension base="simpleBase2"/> </xs:simpleContent> </xs:complexType> <xs:complexType name="unsupported_3_5"> <xs:simpleContent> <xs:restriction base="complexBase2"> <xs:attribute name="id" type="xs:short"/> </xs:restriction> </xs:simpleContent> </xs:complexType>
Unlike the other unsupported structures, this one is not detected by the XSD converter. Before importing any XSDs, check for this structure. If a native event is created from an XSD with empty groups, a runtime error occurs during translation.
References to group definitions with no members are not supported for this Oracle Application Server ProcessConnect release. In the following example, LOCALADDR is a valid group, but EMPTY_GROUP and EMPTY_CONTENT are both empty and therefore are unsupported groups. The global element USAddress is unsupported because it references unsupported groups.
Unsupported XSD Fragment
<xs:group name="LOCALADDR"> <xs:sequence> <xs:element name="street" type="xs:string"/> <xs:element name="aptNo" type="xs:string" minOccurs="0"/> </xs:sequence> </xs:group> <xs:group name="EMPTY_GROUP"/> <xs:group name="EMPTY_CONTENT"> <xs:sequence/> </xs:group> <xs:element name="LocalAddress"> <xs:complexType> <xs:group ref="LOCALADDR"/> </xs:complexType> </xs:element> <xs:element name="USAddress"> <xs:complexType> <xs:sequence> <xs:group ref="EMPTY_CONTENT"/> <xs:group ref="LOCALADDR"/> <xs:element name="city" type="xs:string"/> <xs:element name="state" type="xs:string"/> <xs:group ref="EMPTY_GROUP"/> </xs:sequence> </xs:complexType> </xs:element>
Corresponding Valid Instances
<LocalAddress> <street>500 Oracle Pkwy</street> </LocalAddress> <USAddress> <street>500 Oracle Pkwy</street> <city>Redwood Shores</city> <state>CA</state> </USAddress>
The workaround is to remove all references to the empty groups. This has no impact on the set of valid instances. The group definitions do not need to be removed. In the preceding example, LocalAddress remains the same, and the references to EMPTY_CONTENT and EMPTY_GROUP are removed from USAddress.
Modified XSD Fragment
<xs:element name="USAddress"> <xs:complexType> <xs:sequence> <xs:group ref="LOCALADDR"/> <xs:element name="city" type="xs:string"/> <xs:element name="state" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element>
Corresponding Valid Instances
The same instances are valid with the workaround as with the original XSD.
These sections describes procedures permitted by the XMLSchema, but that cannot be matched to an instance. Workarounds are provided.
This structure occurs when a choice contains two or more elements with the same qualified name. Validation error AIP-16744 appears if this structure is encountered in the XSD file.
This section contains these topics:
If a datatype with two identically named choice members is created from an XSD file, there is no way to determine an exact match from instance XML to either of the members.
<xsd:complexType Name="Buyer"> <xsd:choice> <xsd:element name="Name" type="xsd:string"/> <xsd:element name="Name" type="xsd:string"/> </xsd:choice> </xsd:complexType>
"Name" can be matched to either of the "Name" members in the XSD.
<Buyer> <Name>Rakesh</Name> </Buyer>
The second "Name" datatype member is redundant and must be removed. This does not impact the set of valid instances.
<xsd:complexType Name="Buyer"> <xsd:choice> <xsd:element name="Name" type="xsd:string"/> </xsd:choice> </xsd:complexType>
This occurs when a sequence contains two or more elements with the same qualified name with no mandatory elements between them, and the first occurrence has a cardinality other than [1,1]. In this case, it is not always possible to determine the element to which an instance matches. Validation error AIP-16744 appears if such a structure is encountered in the XSD file.
The following sections provide examples of the ways in which this can occur in an XSD file. The workaround in each case is to combine the elements into a single element by adding up the different minOccurs and maxOccurs.
Unsupported XSD Fragments:
In this example, Buyer1 has two optional "Name" elements, and Buyer2 has one optional and one required "Addr" element:
<xs:complexType Name="Buyer"> <xs:sequence> xs:element name="Buyer1"> <xs:complexType> <xs:sequence> <xs:element name="Name" minOccurs="0" type="xsd:string"/> <xs:element name="Name" minOccurs="0" type="xsd:string"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Buyer2"> <xs:complexType> <xs:sequence> <xs:element name="Addr" minOccurs="0" type="xsd:string"/> <xs:element name="Addr" maxOccurs="2" type="xsd:string"/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType>
If there was a mandatory element with a different name in between the two "Name" elements, then that XSD construct is deterministic and valid in Oracle Application Server ProcessConnect.
<xsd:complexType Name="ValidBuyer"> <xsd:sequence> <xsd:element name="Name" minOccurs="0" type="xsd:string"/> <xsd:element name="Pid" type="xsd:string"/> <xsd:element name="Name" minOccurs="0" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
Corresponding Instance XML:
In this corresponding instance of Buyer, "Name" can match to either of the "Name" members under Buyer1, and the first "Addr" can match to either "Addr" member under Buyer2.
<Buyer> <Buyer1> <Name>Rakesh</Name> </Buyer1> <Buyer2> <Addr>500 Oracle Pkwy</Addr> <Addr>Redwood Shores</Addr> </Buyer2> </Buyer>
In this instance of ValidBuyer, "Name" matches exactly to the first "Name" member element.
<ValidBuyer> <Name>Rakesh</Name> <Pid>1234</Pid> </ValidBuyer>
Combine the redundant members into a single member, which makes the datatype deterministic and valid in Oracle Application Server ProcessConnect. This workaround does not impact the set of valid instances.
To determine the cardinality of the member, add the cardinalities of the original members. In the example, both "Name" elements have a cardinality of [0,1]. Therefore the consolidated "Name" element has a cardinality of [0,2]. The "Addr" elements have cardinalities [0,1] and [1,2], so the consolidated "Addr" element has a cardinality of [1,3].
<xs:complexType Name="Buyer"> <xsd:sequence> <xs:element name="Buyer1"> <xs:complexType> <xs:sequence> <xs:element name="Name" minOccurs="0" maxOccurs="2" type="xsd:string"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Buyer2"> <xs:complexType> <xs:sequence> <xs:element name="Addr" minOccurs="1" maxOccurs="3" type="xsd:string"/> </xs:sequence> </xs:complexType> </xs:element> </xsd:sequence> </xs:complexType>
Unsupported XSD Fragments:
<xsd:complexType Name="Buyer"> <xsd:sequence> <xsd:element name="Name" maxOccurs="unbounded" type="xsd:string"/> <xsd:element name="Name" minOccurs="0" maxOccurs="unbounded" type="xsd:string"/> <xsd:element name="Name" minOccurs="0" maxOccurs="unbounded" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
If the XSD construct has another mandatory element in between, then that XSD construct is deterministic and valid in Oracle Application Server ProcessConnect.
<xsd:complexType Name="ValidBuyer"> <xsd:sequence> <xsd:element name="Name" maxOccurs="unbounded" type="xsd:string"/> <xsd:element name="Pid" maxOccurs="unbounded" type="xsd:string"/> <xsd:element name="Name" maxOccurs="unbounded" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
Corresponding Instance XML:
The second "Name" instance can be matched to any of the "Name" elements in Buyer.
<Buyer>
<Name>Rakesh</Name>
<Name>Ram</Name>
</Buyer>
Each instance can be exactly matched here to its corresponding element:
<ValidBuyer> <Name>Rakesh</Name> <Name>Ram</Name> <Pid>1234</Pid> <Name>Aninda</Name> </ValidBuyer>
Combine the redundant members into a single member, which makes the datatype deterministic and valid in Oracle Application Server ProcessConnect. This workaround does not impact the set of valid instances.
Replace all the redundant members with a single member that has the combined cardinality of all the redundant elements. In the example, the original cardinalities are [1,unbounded), [0,unbounded), and [0,unbounded), so the combined cardinality is [1,unbounded).
<xsd:complexType Name="Buyer"> <xsd:sequence> <xsd:element name="Name" minOccurs="1" maxOccurs="unbounded" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
Unsupported XSD Fragment:
<xsd:complexType Name="Buyer"> <xsd:sequence> <xsd:element name="Name" maxOccurs="2" type="xsd:string"/> <xsd:element name="Name" maxOccurs="2" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
Corresponding Instance XML:
name2 matches to both "Name" elements.
<Buyer> <Name>name1</Name> <Name>name2</Name> <Name>name3</Name> </Buyer>
Workaround:
Replace the two "Name" elements with a single "Name" element having their combined cardinality.
<xsd:complexType Name="Buyer"> <xsd:sequence> <xsd:element name="Name" minOccurs="2" maxOccurs="4" type="xsd:string"/> </xsd:sequence> </xsd:complexType>
XSD constructs result in instances with some elements that cannot be correctly matched to an Oracle Application Server ProcessConnect datatype member by looking at a single instance element. Subsequent instance elements must be checked. These XSD constructs cause validation error AIP-16744. This section contains the following topics:
In this XSD file, complex type "AttachRef" has a choice of "FileName" and a sequence of "FileName" and "URI". In instance XML, "FileName" can be matched to an XSD element based on the presence of "URI". This requires lookahead on the instance XML at runtime that is not currently done.
<xsd:complexType name="AttachRef" > <xsd:choice> <xsd:element name="FileName" type="xsd:string"/> <xsd:sequence> <xsd:element name="FileName" type="xsd:string"/> <xsd:element name="URI" type="xsd:string" /> </xsd:sequence> </xsd:choice> </xsd:complexType> <xsd:complexType name="Name"> <xsd:choice> <xsd:sequence> <xsd:element name="First" type="xsd:string"/> <xsd:element name="Middle" type="xsd:string"/> </xsd:sequence> <xsd:sequence> <xsd:element name="First" type="xsd:string"/> <xsd:element name="Nickname" type="xsd:string" /> </xsd:sequence> </xsd:choice> </xsd:complexType>
Corresponding Instance XML:
In the following instance, "FileName" must be matched to the "FileName" element that is directly under "Attachref".
<AttachRef> <FileName>a.xml</FileName> </AttachRef>
"FileName" must be matched here to the "FileName" element under sequence because "URI" cannot be the next element in the instance for the top-level "FileName"".
<AttachRef> <FileName>a.xml</FileName> <URI>http://www.oracle.com</URI> </AttachRef>
For these kind of constructs, instance elements cannot be matched correctly without looking ahead at the subsequence elements that are not currently supported in Oracle Application Server ProcessConnect.
Take the common part of the different choice members and put this as the first element in a sequence. Then create a new choice that has a member for each of the remainders of the original choice members, and add this as the second element in the sequence. This does not impact the set of valid instances.
In the first example, the top level choice block is replaced with a sequence that has two elements. The first element is the redundant "FileName". The second element is a choice between "URI" and nothing, which can be designed as an optional choice block with a single element, or more simply as an optional element.
<xsd:complexType name="AttachRef" > <xsd:sequence> <xsd:element name="FileName" type="xsd:string"/> <xsd:element name="URI" type="xsd:string" minOccurs="0"/> </xsd:sequence> </xsd:complexType>
In the second example, the top level choice block is replaced with a sequence that has two elements. The first element is the redundant "First". The second element is a choice between "Middle" and "Nickname".
<xsd:complexType name="Name" > <xsd:sequence> <xsd:element name="First" type="xsd:string"/> <xsd:choice> <xsd:element name="Middle" type="xsd:string"/> <xsd:element name="Nickname" type="xsd:string"/> </xsd:choice> </xsd:sequence> </xsd:complexType>
Table A-2 lists the attributes with unsupported values. An error occurs if any of these attributes having an unsupported value are encountered in an XMLSchema document.
The following constructs are not supported by Oracle Application Server ProcessConnect in XML instances.
This attribute occurs within an instance element and specifies the actual type of the instance element. If xsi:type is present in an XML instance that contains elements declarations of the actual type, it causes the following runtime translation exception errors:
Error -: AIP-10412: Translation step failed during execution: Error -: AIP-14114: Translation error occured in translator oracle.tip.ts.translation.xsd.translator.XSDInboundTranslator : oracle.tip.ts.exception.DomainResourceException: Error -: AIP-14117: Input XML is invalid current element nib of namespace Null can not appear in XML Instance after ink from namespace Null according to the datatype model
There is no current workaround.
<billTo xsi:type="unsupported"> <name>Robert Smith</name> <street>8 Oak Avenue</street> <city>Old Town</city> <state>PA</state> <zip>95819</zip> </billTo>
This attribute within an instance element is used to indicate explicitly that the element has a null value. Runtime translation exception error AIP-14117 appears if this tag is encountered in an instance. There is no current workaround.
<shipDate xsi:nil="true"></shipDate>
Within a namespace, names must be unique across simpleTypes and complexTypes. However, a simpleType or complexType can have the same name as an attribute, element, group, or attributeGroup.
The following is an example of an unsupported XSD file.
<xs:schema targetNamespace="http://www.oracle.com/ipdemo" xmlns="http://www.oracle.com/ipdemo" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:simpleType name="foo"> <xs:restriction base="xs:anySimpleType"/> </xs:simpleType> <xs:complexType name="foo"> <xs:all> <xs:element name="bar" type="xs:string"/> </xs:all> </xs:complexType> </xs:schema>
The following is an example of a supported XSD file.
<xs:schema targetNamespace="http://www.oracle.com/ipdemo" xmlns="http://www.oracle.com/ipdemo" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:simpleType name="foo"> <xs:restriction base="xs:anySimpleType"/> </xs:simpleType> <xs:element name="foo" type="foo"/> </xs:schema>
Within a namespace, names must be unique across global elements, attributes, groups, and attributeGroups. If this occurs in an XSD file, the names must be changed.
The following is an example of an unsupported XSD file.
<xs:schema targetNamespace="http://www.oracle.com/ipdemo" xmlns="http://www.oracle.com/ipdemo" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="bar" type="xs:integer"/> <xs:attribute name="bar"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="4"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attributeGroup name="type"> <xs:attribute name="size" type="xs:nonNegativeInteger"/> <xs:attribute name="style" type="xs:string"/> </xs:attributeGroup> <xs:attribute name="type" type="xs:string"/> <xs:group name="color"> <xs:sequence> <xs:element name="r" type="unsignedShort"/> <xs:element name="g" type="unsignedShort"/> <xs:element name="b" type="unsignedShort"/> </xs:sequence> </xs:group> <xs:attributeGroup name="color"> <xs:attribute name="red" type="xs:string"/> <xs:attribute name="green" type="xs:string"/> <xs:attribute name="blue" type="xs:string"/> </xs:attributeGroup> <xs:element name="root"> <xs:complexType> <xs:sequence> <xs:group ref="color"/> <xs:element ref="bar"/> </xs:sequence> <xs:attribute ref="type"/> <xs:attributeGroup ref="type"/> <xs:attribute ref="bar"/> <xs:attributeGroup ref="color"/> </xs:complexType> </xs:element> </xs:schema>
If one of the objects in a name conflict is a group or attributeGroup, change the name of that object. group and attributeGroup names are not used in instances. Otherwise, the conflict is between an element and an attribute. In this case, if the attribute has a locally defined type, move this type definition to a top-level type named simpleType. Then, remove the attribute declaration and change all attribute references to local attributes with the name and type of the original attribute declaration.
These workarounds do not impact the set of valid instances.
<xs:schema targetNamespace="http://www.oracle.com/ipdemo" xmlns="http://www.oracle.com/ipdemo" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="bar" type="xs:integer"/> <xs:simpleType name="bar"> <xs:restriction base="xs:string"> <xs:length value="4"/> </xs:restriction> </xs:simpleType> <xs:attributeGroup name="typeAttrGroup"> <xs:attribute name="size" type="xs:nonNegativeInteger"/> <xs:attribute name="style" type="xs:string"/> </xs:attributeGroup> <xs:attribute name="type" type="xs:string"/> <xs:group name="colorGroup"> <xs:sequence> <xs:element name="r" type="unsignedShort"/> <xs:element name="g" type="unsignedShort"/> <xs:element name="b" type="unsignedShort"/> </xs:sequence> </xs:group> <xs:attributeGroup name="colorAttrGroup"> <xs:attribute name="red" type="xs:string"/> <xs:attribute name="green" type="xs:string"/> <xs:attribute name="blue" type="xs:string"/> </xs:attributeGroup> <xs:element name="root"> <xs:complexType> <xs:sequence> <xs:group ref="colorGroup"/> <xs:element ref="bar"/> </xs:sequence> <xs:attribute ref="type"/> <xs:attributeGroup ref="typeAttrGroup"/> <xs:attribute name="bar" type="bar"/> <xs:attributeGroup ref="colorAttrGroup"/> </xs:complexType> </xs:element> </xs:schema>
This section describes XSD datatypes, datatype members, and attributes that can only be added to Oracle Application Server ProcessConnect through XSD files and not through the Oracle Application Server ProcessConnect user interface tool.
The following tags enable you to create derived datatypes:
extension
The Oracle Application Server ProcessConnect user interface tool cannot create complex datatypes that are extensions of other datatypes. Use the extension element in XSD files to perform this task.
restriction
The Oracle Application Server ProcessConnect user interface tool cannot create complex datatypes that are restrictions of other complex datatypes. Use the restriction element in XSD files to perform this task. However, the Oracle Application Server ProcessConnect user interface tool does support the creation of scalar datatypes that are restrictions of other scalar datatypes.
Anonymous
The Oracle Application Server ProcessConnect user interface tool cannot create anonymous datatypes. Use XSD files to perform this task by not specifying names for datatype definitions.
Abstract
The Oracle Application Server ProcessConnect user interface tool cannot create abstract datatypes. Use XSD files to perform this task by setting the attribute abstract to be true for datatype definitions.
Reference Only
The Oracle Application Server ProcessConnect user interface tool cannot create reference-only datatypes. Use XSD files to perform this task by specifying datatype definitions within top-level (global) element definitions.
Those datatypes defined within global element definitions become reference-only datatypes.
Member Group Type
The Oracle Application Server ProcessConnect user interface tool cannot create member-group-type datatypes. Use XSD files to perform this task by defining substitution groups. A member-group-type datatype is created out of each substitution group.
Element/Attribute
The Oracle Application Server ProcessConnect user interface tool cannot create datatype members of type Attribute. Use XSD files to define attributes for complex datatypes.
Anonymous
The Oracle Application Server ProcessConnect user interface tool cannot create anonymous datatype members. Use XSD files to specify names for elements of complex datatype definitions.
Qualified
The Oracle Application Server ProcessConnect user interface tool cannot create qualified datatype members. Use XSD files to do so by qualifying elements or attributes; that is, specifying targetNamespace and setting elementFormDefault, attributeFormDefault, or both to be qualified or setting form to be qualified individually for elements and attributes.
Member Group Head
The Oracle Application Server ProcessConnect user interface tool cannot create member-group-head datatype members. Use XSD files to do so by defining substitution groups. A member-group-head datatype member is created out of each nonabstract substitution group.
Oracle Application Server ProcessConnect supports the use of native formats that adhere to the standards of the data definition description language (D3L).
This section contains these topics:
This section defines and describes when D3L is used.
D3L is an XML-based message description language that describes the structure that a native, non-XML format message (known as the wire message) must follow to communicate with Oracle Application Server ProcessConnect.
Not all parties in an integration use XML as their native message payload format. Parties also use other native formats in their wire messages, which are best described as structured records of bytes, characters, or both. For these native formats to be successfully translated into a format understood by other parties, the content of their messages must follow a predefined, structured set of rules.
D3L provides both a predefined, structured set of rules and translation capabilities for the native format of wire messages. Specifically, D3L provides:
The D3L descriptions must comply with a syntax defined by the D3L document type definition (DTD). D3L enables you to describe the record layout of binary, string, structured, and sequence data. Use D3L only when the number of fields in the underlying wire message is fixed and known. D3L is not suitable for:
See Also:
This section provides an example of how the contents of a wire message are described in a D3L file. This file can then be specified after you select D3L as your translator in the Oracle Application Server ProcessConnect user interface tool.
Satisfying these requirements enables a native event and native event body elements to be created from the wire message content and then successfully translated into an application event (XML) and its event body elements.
|
See Also:
Chapter 11, "Managing Adapter Interactions and Event Types" for instructions on selecting D3L as a translator and specifying a D3L file |
This example shows a party's wire message (named price) that contains payload data for updating the price of personal computer model number 2468 to 199.99. Logically, the wire message can be described as using the following format and structure:
message ::= <action> <model> <price>
| Where... | Is... |
|---|---|
|
|
|
|
|
|
|
|
|
The runtime payload data must strictly follow the structure defined in a D3L file (for this example, price.xml) for the D3L translator to translate it into an application event. Figure A-1 shows how a D3L file (price.xml) defines the exact structure that the wire message price must follow to define the three preceding elements of payload data (now with pertinent delimiters introduced).

All three payload data elements are defined as strings with different delimiters for separating their data.
|
See Also:
"Delimited Strings - limstring" for a description of |
This section contains these topics:
This section describes the contents of a sample D3L file named book_reply.xml. The book_reply.xml message has the following logical structure:
replyFlight = AirportCodeFrom AirportCodeTo Itineraries
Itineraries = { ItinRecord }
ItinRecord = DepartureTime ArrivalTime
DepartureTime = DateTimeRecord
ArrivalTime = DateTimeRecord
DateTimeRecord = "MMDDYY"
Note how the <message> attribute type refers to the top-level structure of the message definition. A line-by-line walkthrough of the meaning of each line in the D3L definition is shown in this section.
1 <?xml version="1.0" encoding="US-ASCII"?> 2 <!DOCTYPE message SYSTEM "d3l.dtd"> 3 <message name="replyFlight" type="BookingReplyType"> 4 5 <unsigned4 id="u4" /> 6 <unsigned2 id="u2" /> 7 <struct id="DateTimeRecord"> 8 <field name="DateInfo"> 9 <date format="MMDDYY"> 10 <pfxstring id="datstr" length="u4" /> 11 </date> 12 </field> 13 <field name="TimeHour"><limstring delimiter="*" /></field> 14 <field name="TimeMinute"><limstring delimiter="*" /></field> 15 </struct> 16 <struct id="ItinRecord"> 17 <field name="DepartureTime"><typeref type="DateTimeRecord" /></field> 18 <field name="ArrivalTime"><typeref type="DateTimeRecord" /></field> 19 </struct> 20 <pfxarray id="ItinArray" length="u2"> 21 <typeref type="ItinRecord" /> 22 </pfxarray> 23 <struct id="BookingReplyType"> 24 <field name="AirportCodeFrom"><limstring delimiter="*" /></field> 25 <field name="AirportCodeTo"><limstring delimiter="*" /></field> 26 <field name="Itineraries"><typeref type="ItinArray" /></field> 27 </struct> 28 </message>
These lines define standard information, such as the Prolog and Document Type Declaration (DTD) that must always be these values (for example, specifying d3l.dtd as the DTD). The encoding can vary according to the locale.
These lines define the following:
name (value replyFlight) equals the application event datatype name, which is used when this D3L definition is specified when creating a native event type
type (value BookingReplyType) names the top-level structure that is defined in subsequent lines of this D3L file
These lines define an unsigned, four-byte integer and unsigned, two-byte integer. These datatype declarations are named u4 and u2, respectively, so they can be referred to later. Because they are declarations, they do not directly map to data in the native language, but are instead used in typesets for increased maintainability.
These lines define the fields of a structure named DateTimeRecord:
DateInfo defines a date format of MMDDYY consisting of a length prefixed string (length stored as an unsigned, binary, four-byte integer).
TimeHour defines a string delimited by the character *.
TimeMinute defines a string delimited by the character *.
These lines define the fields of the structure named ItinRecord:
DepartureTime and ArrivalTime both consist of the DataTimeRecord structure defined in "Lines 7 through 15" , referencing it through typerefs.
These lines define a length-prefixed array named InitArray, where each array element is of type ItinRecord. The length is stored ahead of the array contents as a two-byte, unsigned, binary integer.
These lines define the fields of the message structure BookingReplyType (which satisfies the BookingReplyType type reference in the message document element, as shown in "Lines 3 through 4"):
AirportCodeFrom is a string delimited by the character * on both sides.
AirportCodeTo is a string delimited by the character *.
Itineraries is a field of type ItinArray (which is an array of ItinRecord) (See "Lines 16 through 19" and "Lines 20 through 22").
D3L supports the following datatypes and declarations in a D3L file:
D3L supports signed and unsigned integers that can be one, two, four, or eight octets (bytes) in size, and in big- or little-endian byte ordering. D3L also supports byte position alignment.
<field name="quantity"> <unsigned4 endian="big" align="6"/> </field>
The field "quantity" defines a four-byte, unsigned, binary integer, using big (default) endian, and at an alignment of six bytes. For example, D3L ensures that the reading or writing of this integer starts at a position in the buffer, so that position modulus alignment = 0.
Data Example for Example A-1:
Byte addresses (hex):
00 01 02 03 04 05 06 07 08 09 0A 0B
Byte (hex):
00 00 00 00 00 00 80 FF FF FF 00 00
Parsed value (dec):
quantity = 128x2563 + 255x2562 + 255x2561 + 255x2560 = 2164260863 80 FF FF FF
<field name="weight"> <unsigned2 align="3"/> </field> <field name="length"> <unsigned2 align="3"/> </field>
The fields "weight" and "length" define two two-byte unsigned, binary integers, using big-endian, and at an alignment of three bytes.
Data Example for Example A-2:
Byte addresses (hex):
.. 07 08 09 0A 0B 0C 0D 0E ..
Byte (hex):
.. 00 00 EE 88 00 22 F0 00 ..
Parsed value (dec):
weight = 238x2561 + 136x2560 = 61064 length = 34x2561 + 240x2560 = 8944
<field name="temperature"> <signed2 endian="little" /> </field> <field name="pressure"> <unsigned4 endian="big" /> </field> <field name="wind"> <unsigned2 endian="little" align="4" /> </field>
The field "temperature" defines a two-byte, signed, binary integer, using little-endian, and no alignment.
The field "pressure" defines a four-byte, unsigned, binary integer, using big-endian, and no alignment.
The field "wind" defines a two-byte, unsigned, binary integer, using little-endian, and a four-byte alignment.
Data Example for Example A-3:
Byte addresses (hex):
.. 60 61 62 63 64 65 66 67 68 69 ..
Byte (hex):
.. EF FE 00 00 04 0A 00 00 3C 00 .. ^ ^ ^ little end big end alignment
Parsed value (dec):
temperature = 256x256 - (239x2560 + 254x2561) = -273 pressure = 4x2561 + 10x2560 = 1034 wind = 60x2560 + 0x2561 = 60
D3L supports single and double-precision, IEEE format, floating-point data. Single-precision, floating point numbers (known as floats) take up four bytes. Double-precision, floating point numbers (known as doubles) take up eight bytes.
<field name="distance"> <double align="6"/> </field> <field name="age"> <float /> </field>
The field "distance" defines an eight-byte, double-float (floating-point value according to the IEEE 754 floating-point double precision bit layout), at an alignment of six bytes.
The field "age" defines a four-byte, single-float (floating-point value according to the IEEE 754 floating-point single precision bit layout).
Data Example for Example A-4:
Byte addresses (hex):
.. 77 78 79 7A 7B 7C 7D 7E 7F 80 81 xx xx ..
Byte (hex):
00 00 D2 47 D3 CE 16 2A B1 A1 5E 5D 6B 0B .. ^ double ^ float
Parsed value (dec):
distance = 1 x 1038 age = 1 x 1018
D3L supports the following string types:
limarray structure.
This section provides an example:
<field name="CURRENCY_CODE"> <padstring length="4" padchar=" " padstyle="tail"/> </field> <field name="COUNTRY_CODE"> <padstring length="2" padchar="" padstyle="none"/> </field> <field name="TO_USD_RATE"> <padstring length="12" padchar="0" padstyle="head"/> </field>
The field "CURRENCY_CODE" defines a fixed length string of four characters. Any blank (" ") characters (pads) near the end (padstyle="tail") of the string are not considered part of the data value.
The field "COUNTRY_CODE" defines a fixed length string of two characters. Since padstyle is "none", all characters in this field are part of the data value.
The field "TO_USD_RATE" defines a fixed length string of 12 characters. Any zeros ("0" pads) at the beginning (padstyle="head") of the string are not considered part of the data value.
Data Example for Example A-5:
Native byte (character) stream:
GBP UK000012550.00
Parsed values:
CURRENCY_CODE = 'GBP' COUNTRY_CODE = 'UK' TO_USD_RATE = '12550.00'
This section provides an example:
<field name="State"> <limstring delimiter="." /> </field> <field name="Region"> <limstring delimiter="." /> </field> <field name="City"> <limstring delimiter="|" /> </field> <field name="Landmark"> <limstring delimiter="|" /> </field> <field name="Street"> <limstring delimiter="+" /> </field>
The five fields "State", "Region", "City", "Landmark", and "Street" are delimited strings each respectively enclosed by ".", ".", "|", "|", and "+".
Data Example for Example A-6:
Native byte (character) stream:
.FL..Florida Keys.|Key West||Ernest Hemingway Museum|+Whitehead St.+
Parsed values:
State = 'FL' Region = 'Florida Keys' City = 'Key West' Landmark = 'Ernest Hemingway Museum' Street = 'Whitehead St.'
This section provides an example:
<unsigned1 id="ubyte1" /> <unsigned2 id="ubyte2" endian="little" /> <struct> <field name="user"> <pfxstring length="ubyte1" /> </field> <field name="encr_user"> <pfxstring length="ubyte2" /> </field>
The field "user" defines a string, the length of which is defined by a one-byte binary integer preceding the string contents.
The field "encr_user" defines a string, the length of which is defined by a two-byte, little-endian, binary integer preceding the string contents. Note that the value of the length attribute must refer to a datatype declaration done somewhere else in the D3L definition.
Data Example for Example A-7:
Byte addresses (hex):
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 10 11 12
Characters:
03j o e0D00D U Z a c . 1 H K V m I Y
Parsed values:
user='joe'
encr_user = 'DUZac.1HKVmIY'
This section provides an example:
<field name="product"> <termstring endchar=","/> </field> <field name="ordered"> <termstring endchar=","/> </field> <field name="inventory"> <termstring endchar=","/> </field> <field name="backlog"> <termstring endchar=","/> </field> <field name="listprice"> <termstring endchar="\n"/> </field>
The first four fields each are populated with input characters until the terminating/ending character (endchar) is encountered (","). The last field is ended with a line feed.
Data Example for Example A-8:
Native byte (character) stream:
1020,16,18,,1580.00<LF>
Parsed values:
product = '1020' ordered = '16' inventory = '18' backlog = '' listprice = '1580.00'
This section provides an example:
<struct id="PersonInfo" quote='"'> <field name="PersonName"> <qtdtermstring endchar="," /> </field> <field name="Address"> <qtdtermstring endchar="," /> </field> <field name="DOB"> <qtdtermstring endchar="," /> </field> <field name="Telephone"> <qtdtermstring endchar="\n"/> </field> </struct>
Data Example for Example A-9:
The preceding D3L definition (code) parses each of the following input lines:
Native byte (character) stream:
"Smith, John","1 Old Street, Old Town, Manchester",,"0161-499-1717" Fred, "2 Old Street, Old Town,Manchester","20-08-1954","0161-499-1718" "Smith, Bob",,, 0161-499-1719
The parsed values are not listed here. Note, however, that commas within quotation marks are not treated as delimiters. The quote attribute can also be defined as an attribute to the qtdtermstring element. For example:
<qtdtermstring quote="*" endchar="," />
It can also be defined globally at the root element message level. For example:
<message name="my_msg" quote="'" ...>
If no quote attribute is defined anywhere, D3L defaults to using a double quote (") as the quotation character when parsing any qtdtermstring. As a general rule, the quote attribute definition in nearest proximity (structurally) of a qtdtermstring takes precedence.
This section provides an example:
<limarray id="CSV_Type" contchar="," endchar="\n"> <simplestring /> </limarray> <struct> <field name="CSV"> <typeref type="CSV_Type" /> </field>
The field "CSV" references a type declaration "CSV_Type" that is a delimited array where array members are separated by commas (the continuation character contchar=",") and ended by the ending character line feed (endchar="\n")
Data Example for Example A-10:
Native byte (character) stream:
5,18,2.5,255,78.75,9
Parsed values:
name[] = { '5', '18', '2.5', '255', '78.75', '9' }
This section provides an example:
<field name="StartDate"> <date format="MMDDYY"> <termstring endchar="\n"/> </date> </field> <field name="EndDate"> <date format="DDMMYY"> <termstring endchar="\n"/> </date> </field> <field name="Milestone"> <date format="MMDDYYYY"> <termstring endchar="\n"/> </date> </field> <field name="DueDate"> <date format="DDMMYYYY"> <termstring endchar="\n"/> </date> </field>
Data Example for Example A-11:
Byte stream (characters):
11/16/02<LF> 24/11/02<LF> 11/20-2002<LF> 23*11*2002<LF>
Barsed values:
StartDate = Sat Nov 16 00:00:00 PST 2002 EndDate = Sun Nov 24 00:00:00 PST 2002 Milestone = Wed Nov 20 00:00:00 PST 2002 DueDate = Sat Nov 23 00:00:00 PST 2002
D3L supports the seven date formats shown in Table A-3.
The information is stored as a string in one of these formats. The application message format (XML) is fully ISO 8601 compliant. For example, if a native message contains the byte stream:
"11/24/1965 11:10:00 PST"
it is translated to (vice versa for outbound):
<starttime>1965-11-25T07:10:00</starttime>
assuming the following D3L code prescribed the translation:
<field name="starttime"> <date format="MMDDYYYY_HHMISS_Z"> <limstring delimiter='"' /> </date> </field>
This section provides an example:
<unsigned1 id="u1" /> <pfxstring id="HueType" length="u1" /> <struct id="ColorDefinition"> <field name="Red"> <number> <padstring length="4" padstyle="head" padchar=" "/> </number> </field> <field name="Green"> <number> <pfxstring length="u1" /> </number> </field> <field name="Blue"> <number> <limstring delimiter="."/> </number> </field> <field name="Brightness"> <number> <termstring endchar="|"/> </number> </field> <field name="Hue"> <number> <typeref type="HueType"/> </number> </field> </struct>
The declared type "u1" is an unsigned, one-byte integer (0-255). The second type declaration "HueType" is a length prefixed string, where the string length is defined in a one-byte, unsigned, binary integer preceding the string contents.
The field "Red" is a number defined as a fixed-length string of four characters, which can be padded with zeros at the beginning.
The field "Green" is a number defined as a length prefixed string, where the string length is defined in a one-byte, unsigned, binary integer preceding the string contents.
The field "Blue" is a number defined as a "." delimited string; the string beginning and ending is demarcated by ".".
The field "Brightness" is a number defined as a string that is read from the current point until the ending character ("|") is encountered.
The field "Hue" is a number defined as a string of type "HueType" (defined previously).
Data Example for Example A-12:
00 01 02 03 04 05 06 07 08 09 0A 0B 0C 0D 0E 0F 0 1 2 8 03 1 2 8 . 2 5 5 . 0 . 7 10 11 12 13 14 15 16 17 18 19 1A 1B 1C 1D 1E 5 3 3 3 3 | 08 0 . 6 6 6 6 6 6
Parsed values:
Red = 128.0 Green = 128.0 Blue = 255.0 Brightness= 0.753333 Hue = 0.666666
D3L supports structured types; that is, ordered records containing other datatypes (predefined or user-defined). Types can be nested to arbitrary depth. This means you can use structures of sequences of structures of sequences [...] to any finite depth. Recursive, self-referencing data structures, however, are not supported in D3L.
All data fields in a message format description must be named. These names are used as Oracle Application Server ProcessConnect datatype (compound) member names. All names within the same structure must be mutually unique.
The first allowable root element within a D3L file is <message>. The message element must refer to a <struct> (through the IDREF type attribute) that then becomes the top-level data structure of the message.
<message type="ColorDefinition" name="myEV"> <unsigned1 id="u1" /> <pfxstring id="HueType" length="u1" /> <struct id="ColorDefinition"> <field name="Red"> ... <field name="Green"> ...
D3L supports sequences of various types. These include:
The sequence contents can be any other D3L types (predefined or user-defined).
This section provides an example:
<field name="members"> <limarray contchar=";" endchar="."> <simplestring/> </limarray> </field>
The field "members" becomes an array of data elements separated by semicolons (contchar=";"). The end of the array is marked by a period (endchar="."). Each data element in the array is a (simple) string delimited by delimiters defined by the enclosing array (that is, semicolons (;) and periods (.)).
Data Example for Example A-14:
Native byte (character) stream:
John;Steve;Paul;Todd.
Parsed values:
members[] = { 'John', 'Steve', 'Paul', 'Todd' }
This section provides an example:
<unsigned2 id="u2" endian="little" align="4" /> <struct> <field name="measurements"> <pfxarray length="u2" > <signed1 /> </pfxarray> </field>
The field "measurements" becomes an array of signed one-byte binary integers (signed1). The number of elements in the array are determined by the unsigned two-byte binary integer ("u2") at the beginning of the array.
Data Example for Example A-15:
Byte addresses (hex):
.. 08 09 0A 0B 0C 0D 0E 0F 10 ..
Bytes (hex):
.. 06 00 FF A2 6C 24 0E 77 ..
Values (dec):
measurements[] = { -1, -94, 108, 36, 14, 119 }
This section provides an example:
<field name="digits"> <fixarray length="10"> <number> <termstring endchar="-"> </number </fixarray>
The field "digits" becomes an array of numbers (doubles). Each number element in the native byte format is represented as a string that is terminated by a dash (endchar="-"). The number of elements in the array must always be 10 (length="10").
Data Example for Example A-16:
Native byte (character) stream:
1-2-3-4-5-6-7-8-9-0-
Parsed values:
digits[] = { 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 0.0 }
This section provides an example:
<message name="addOrders" type="OrdersType"> <number id="Number"> <termstring endchar="," /> </number> <number id="Price"> <termstring endchar=";" /> </number> <number id="Total"> <termstring endchar="\n"/> </number> <struct id="OrderLineType"> <field name="LineNo"> <typeref type="Number" /> </field> <field name="ProductNo"> <typeref type="Number" /> </field> <field name="Quantity"> <typeref type="Number" /> </field> <field name="LinePrice"> <typeref type="Price " /> </field> </struct> <struct id="OrderType"> <field name="OrderTotal"> <typeref type="Total" /> </field> <field name="OrderLines"> <limarray contchar="\n" endchar="\n\n"> <struct> <field name="OrderLine"> <typeref type="OrderLineType" /> </field> </struct> </limarray> </field> </struct> <number id="ID"> <termstring endchar="\n" /> </number> <imparray id="OrdersArrayType"> <struct> <field name="CustomerID"> <typeref type="ID" /> </field> <field name="CustomerName"> <termstring endchar="\n" /> </field> <field name="Order"> <typeref type="OrderType" /> </field> </struct> </imparray> <struct id="OrdersType"> <field name="OrdersArray"> <typeref type="OrdersArrayType" /> </field> </struct> </message>
The "OrdersType" structure consists of a single field "OrdersArray" that is an implicit array of three fields: "CustomerID", "CustomerName", and "Order" (of type "OrderType"). Since "OrdersArrayType" is an implicit array, it consumes all remaining bytes in the native byte input stream (that is, the size of the array is first known when the input byte stream has been used up).
The field "OrderLines" is a (nested) array, where each array element is of type "OrderLineType". The "OrderLineType" is a structure of four fields: "LineNo", "ProductNo", "Quantity", and "LinePrice".
This abstract structure of the input stream must follow this structure to be parseable:
CustomerID CustomerName Order: OrderTotal OrderLines: LineNo, ProductNo, Quantity, LinePrice LineNo, ProductNo, Quantity, LinePrice ...
Data Example for Example A-17:
Native byte (character) stream:
1234 Boeing 1000 1,555,10,250.00; 2,666,10,750.00; 5678 Lockheed Martin 424 1,555,5,125.00; 2,777,1,100.00; 3,888,2,199.00;
Parsed values:
{OrdersArray= [ { CustomerName=Boeing, CustomerID=1234.0, Order= { OrderTotal=1000.0, OrderLines = [ {OrderLine={LinePrice=250.0, ProductNo=555.0, Quantity=10.0,LineNo=1.0}}, {OrderLine={LinePrice=750.0, ProductNo=666.0, Quantity=10.0,LineNo=2.0}} ] } },{ CustomerName=Lockheed Martin, CustomerID=5678.0,Order={ OrderTotal=424.0,OrderLines = [{ OrderLine={LinePrice=125.0, ProductNo=555.0,Quantity=5.0, LineNo=1.0}},{ OrderLine={LinePrice=100.0, ProductNo=777.0,Quantity=1.0, LineNo=2.0}},{ OrderLine={LinePrice=199.0, ProductNo=888.0,Quantity=2.0, LineNo=3.0}}
]
}
}
]
}
D3L supports data padding. Pads are unnamed gaps in a native format message that satisfy alignment constraints of the underlying native system. Pads are discarded in the Oracle Application Server ProcessConnect application event (XML).
The following D3L example defines a number as a left-aligned string, right-padded with blanks to a field width of 10:
<field name="Quantity"> <number> <padstring length="10" padchar=' ' padstyle="tail" /> </number>
The following native byte (character) stream satisfies this format:
9876.5____
Pads can also be explicitly defined between fields in a structure by using the <pad> element.
The following D3L example shows two fields, which are separated by a pad of size ten.
<struct id="PROD"> <field name=PRODID"> <termstring endchar=";" /> </field> <pad length="10" /> <field name=PRODDESC"> <termstring endchar=";" /> </field> </struct>
The following native byte (character) stream satisfies this format:
48682HW;~~~~~~~~~~WASHER AND DRYER;
A comma-separated values (CSV) file consists of multiple lines. Each line contains values separated by commas that end when a (platform-dependent) new line is encountered:
a,b,c,d 1,2,3
Two string types, termstring and simplestring, are available to facilitate the parsing of CSV files.
termstring
String type termstring is a variation of limstring, but requires only a terminating delimiter and not a beginning delimiter. For example:
<termstring endchar="," />
This parses any string contents until a comma is encountered.
simplestring
String type simplestring is a special datatype only used when the nearest parent structure defines a valid set of delimiters, which for the current data D3L library is limited to limarray. For example:
<limarray contchar="," endchar="\n">
<simplestring />
</limarray>
These string types provide two ways to parse CSV files. The examples provided in the following sections use imparray so that input can be any number of elements, lines, or both.
With this method, all CSVs on each line are assigned to named fields (fixed number of fields for each line). Example A-18 provides an example.
<message name="createPhone" type="phoneRecord"><imparray id="lines"><struct><field name="rectype"> <termstring endchar=","/ > </field> <field name="quantity"><termstring endchar=","/ > </field> <field name="endHour"> <termstring endchar=","/ > </field> <field name="endMin"> <termstring endchar=","/ > </field> <field name="cost"> <termstring endchar="\n"/> </field></struct></imparray> <struct id="phoneRecord"><field name="csv"> <typeref type="lines" /> </field></struct></message>
An example of a native format message payload for Example A-18 can be:
4,,9,22,2324.29 ,,,, 55,2342,11,46,728372339.57
With this method, all CSVs on each line are read into an array (variable number of fields for each line). Example A-19 provides an example.
<message name="createPhone" type="phoneRecord"><limarray id="linearr" contchar="#44" endchar="\n"><simplestring /></limarray> <imparray id="myArray"><struct><field name="line"> <typeref type="linearr" /> </field></struct></imparray> <struct id="phoneRecord"><field name="csv"> <typeref type="myArray" /> </field></struct></message>
An example of a native format message payload for Example A-19 is as follows:
4,,9,22,2324.29 55,2342,11,46,728372339.57 55,2342,11,46,728372339.57,4,,9,22,2324.29 1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0
The delimiters for limstring, termstring, and limarray are enhanced to allow multiple characters, as well as additional encoding styles. The associated ASCII table codes are shown in parentheses:
"\". This works for "\r" (13), "\n" (10), "\t" (9), and "\f" (12).
where:
#13".
\eof",which maps to a virtual end-of-file character. This delimiter can only be used once. No other fields can follow once it has been used.
Example A-20 provides several examples of delimiter encoding styles.
<termstring endchar="#x2C"/> <termstring endchar="\n"/> <limarray id="linearr" contchar="," endchar="\r\n"> <simplestring/> </limarray> <termstring id="FileContents" endchar="\eof"/>
The "\r\n" on line 3 of Example A-20 represents an MS-DOS-style line break.
This section describes Oracle Application Server ProcessConnect enhancements to D3L for this release.
This section contains these topics:
To enable the splitting of D3L definition files into smaller, more manageable units (modules and separate files), a new document type is introduced: definitions.
This document type is only declarative; that is, it defines types, variables, and other metadata structures, but has no actual message definition.
Example A-21 shows an example:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE definitions SYSTEM "D3L-definitions.dtd"> <definitions name="SupportingDefinitions"> <unsigned1 id="u1" /> ... <struct id="CustomerInfoType"> <field name="CustomerID"> ... <variables> <variable id="Std_Delimiter" .. ... </definitions>
If this definition is now linked to (associated with) a D3L message definition, the latter can make references to definitions in the former. Example A-22 shows a D3L file (order.xml) that can use declarations defined in supp_defs.xml:
<?xml version="1.0" encoding="US-ASCII"?> <!DOCTYPE message SYSTEM "D3L.dtd"> <message name="MyOrders" type="MyOrderType" ... <struct id="MyOrderType"> <field name="CustomerInfo> <typeref type="CustomerInfoType" /> ...
The link or association between the D3L message document and the D3L definitions document is established while answering the questions in the Translator Properties : D3L Information section of the Create Event Body Element page when creating the native datatype for the D3L designated event body element. This is shown in Figure A-2.
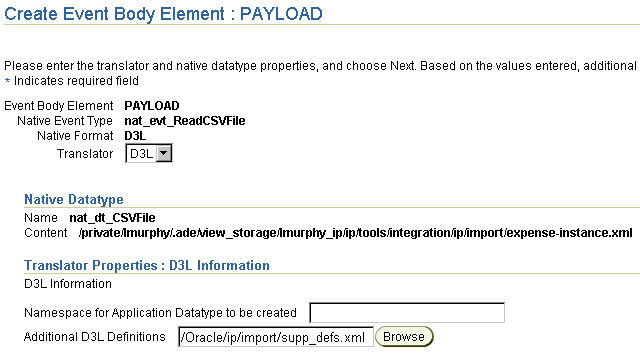
|
See Also:
|
To further promote the modularization of D3L definitions, the definitions document type described "New D3L Document Type" supports a tag that enables you to specify to include (import) another definitions document in the current definitions document. With this feature, the construction shown in Example A-23 is possible:
<definitions name="..."> ... <import location="more_defs.xml" /> ... <import location="even_more_defs.xml" />
The imported file and document must be of type definitions. Recursive includes are not permitted. If the value of the location attribute is not an absolute path name, D3L looks in the following locations (in this order):
The import facility enables you to define a hierarchy of definitions:
The struct element supports an attribute called separatorchar. It allows for the declaration of a separator character, which appears between each of the fields in a given struct. CSV files typically take advantage of this feature.
Example A-24 shows the following declaration:
<struct id="Colors" separatorchar=","> <field name="Red"><simplestring /> </field> <field name="Green"> <simplestring /> </field> <field name="Blue"> <termstring endchar="\n"/> </field> </struct>
This declaration parses the following input:
128,128,255
that is:
Note that the last field is a termstring. Either the enclosing structure must define a terminating character (like the endchar of limarray) or the last field must specify a terminating condition. If the last field ("Blue") in Example A-24 is a simplestring, there is no terminating condition. This results in the last field being assigned the remainder of the input.
Similar to the field separator, the struct element also supports an attribute called terminatorchar. It allows for the declaration of a terminating character, which appears at the end of each field in a given struct (for example, sentences).
Example A-25 shows an example:
<struct id="CommandSet" terminatorchar=";"> <field name="Cmd1"> <simplestring /> </field> <field name="Cmd2"> <simplestring /> </field> <field name="Cmd3"> <simplestring /> </field> <field name="Cmd4"> <simplestring /> </field> </struct>
This declaration parses the following input:
configure;startup;runtest;shutdown;
To enable the specification of a limit on the number of elements accepted in a limarray (delimited array), you can specify the optional attribute cardinality.
Without this attribute, a limarray is simply parsed until endchar is encountered, separating array elements by the contchar character.
This cardinality attribute can assume the values (in double quotes) shown in Table A-4.
| Repetitive Optionality | No | Yes | n (upper bound) |
|---|---|---|---|
|
Required |
|
|
|
|
Optional |
|
|
|
Example A-26 shows an example:
<struct id="jackpot"> <field name="numbers"> <limarray cardinality="*5" endchar="."> <simplestring /> </limarray>
Example input:
2~12~23~28.
If the cardinality attribute is defined to enable more than one array element (that is, one of the following values: "+", "*", "n", "+n", and "*n"), the continuation character attribute contchar can optionally be specified, which marks the separation between array elements. If the attribute is not specified, the default continuation character "~" is used (or whichever character has been assigned to the D3L system variable d3l_contchar).
If the array only contains zero or one elements ("?", "1"), the contchar attribute is ignored.
If both the cardinality and endchar attributes are specified, then the endchar may occur no sooner than such a time where the cardinality criteria has been satisfied.
Fields delimited by separator characters may naturally be empty in the native (wire) message, for example (four phone numbers: work, home, cell, and fax)
650-650-5555,,,650-240-1900,
Example A-27 shows a D3L definition that parses this line:
<struct "phoneNumbers" terminatorchar=","> <field name="Work"> <simplestring /> </field> <field name="Fax"> <simplestring /> </field> <field name="Home"> <simplestring /> </field> <field name="Cell"> <simplestring /> </field> </struct>
This definition fails, since the "Home" and "Fax" fields are being bound to empty values, and by default D3L fields must be bound to nonempty values.
To enable fields to be optional (that is, bound to empty values), the optionality attribute is available. It can assume two values:
If the optionality attribute is not specified, the value "R" is assumed.
To enable the parsing of the phone number native message, the D3L code in Example A-27 must be modified as shown in Example A-28:
<struct "phoneNumbers" terminatorchar=","> <field name="Work" optionality="O"> <simplestring /> </field> <field name="Home" optionality="O"> <simplestring /> </field> <field name="Cell" optionality="O"> <simplestring /> </field> <field name="Fax" optionality="O"> <simplestring /> </field> </struct>
A field can only be defined with optionality="O" if the enclosing struct specifies either a separatorchar or terminatorchar attribute. Otherwise, D3L cannot determine whether or not a field value is present.
D3L supports built-in and user-defined escape sequences, which can appear in the input stream (wire message). The built-in escape sequences consist of the (current) escape character followed by a number (ASCII code) in the range 0-127. If the number is preceded by X, it is read as a hexadecimal number. For example:
"Character for ASCII code 65 is \65" "Decimal digits: \X30 \X31 .. \X39"
In addition to the built-in escape sequences, you can define your own escape sequences using the structure (top-level element) shown in Example A-29:
<escaped-values-map> <value-map native="F" translated="|" /> <value-map native="C" translated="^" /> </escaped-values-map>
When D3L encounters user-defined sequences such as the following:
current_escape_character followed by value_of_native_attribute
it replaces the sequence with the value of the translated attribute. For example, the following native input stream (assuming the escaped-values-map exists):
"field1\Fcomp1\Ccomp2\Ffield3"
reads as follows:
"field1|comp1^comp2|field3"
As indicated previously, the default escape character is \. The escape character can either prefix the sequence, or enclose the sequence. The escape method is configured in the D3L message element, using the attribute escaping:
<message name="..." .. escaping="prefixed">
This makes the following code parseable:
"field separator: \F"
while
<message name="..." .. escaping="enclosed">
needs the escape character on both sides of the sequence:
"field separator: \F\"
The D3L system variable d3l_escapechar contains the current value of the escape character (initially always \), but it can be redefined by an <assignments> tag.
|
See Also:
|
D3L enables you to declare variables, bind values to them at runtime from the input stream, and reference them in syntactic constructs.
Variables are declared in the top-level construct shown in Example A-30:
<variables> <variable id="FieldSep" default="|" maxlen="1" /> <variable id="CompoSep" default="^" maxlen="1" /> </variables>
Variables can be referenced in D3L delimiter attributes by enclosing the variable name with "$" and ";". For example, if you define the variable RecordTerm:
<variables> <variable name="RecordTerm" default="#10" maxlen="1" /> </variables>
it can then be referenced as shown in Example A-31 in a terminatorchar attribute:
<struct id="ContactInfo" terminatorchar="$RecordTerm;"> <field name="SurName"><simplestring /> </field> <field name="FirstName"> <simplestring /> </field> <field name="PhoneNo"> <simplestring /> </field> </struct>
If the variable element attribute default is missing (from a variable declaration), an empty string is assumed. The maxlen attribute must be specified.
D3L defines the following built-in (system) variables, which have predefined meanings:
These variables are automatically defined, as shown in Example A-32:
<variables> <variable name="d3l_escapechar" default="\" maxlen="1" /> <variable name="d3l_contchar" default="~" maxlen="1" /> </variables>
This example definition is just for documentation purposes; these variables cannot be redefined as shown.
The values of these system variables can be changed at runtime through assignment blocks, as described in "Assignment Blocks".
Without assignment blocks, variables only assume the value assigned in the variable declaration block, and are of limited value (may be useful for maintenance purposes, where the value of a line feed sequence can be maintained in just one place).
To allow variables to change at runtime, the assignments construct is available. It enables you to bind either static values (constants) or substrings from runtime message instances to the (declared) D3L variables.
An assignments element can only be referenced (associated) from within the scope of a D3L field (inside a struct) by using the field element attribute assign.
An assignments block, which is associated with a certain field, can make references to (extract) substrings of the current field value. It is also possible to refer to other fields, which are available in the current context (previously parsed fields in the current message).
The current field is referenced with the character sequence "$;". Any previously parsed fields are referenced by the character sequence:
"$field_name;".
Substrings are referenced either by a single index (i) or an index range (i1:i2) right before the ending ";" in a field reference:
$[0];
Single (character) index substring (current field)
$[2:5];
Index range substring (current field)
$OtherField[1];
Single (character) index substring (other field)
$OtherField[3:4];
Index range substring (other field)
The assignments block for a given field is executed after the field has been fully parsed (that is, assigned a value). Field name references in an assignment to not-yet parsed or nonexistent fields result in the empty string, as do illegal or out-of-range substring expressions.
If a certain assignment order must be enforced (XML does not guarantee any element order), an assignment can be ordered by defining an order attribute (a natural number). Order attributes with a lower value are executed before order attributes of higher values.
Example A-33 shows how to use an assignments block:
<variables> <variable name="LineSep" default="." maxlen="1" /> <variable name="ItemSep" default="," maxlen="1" /> </variables> <assignments id="GetSeparators"> <assign variable="ItemSep" value="$[1];" order="1" /> <assign variable="d3l_contchar" value="$[3];" order="2" /> <assign variable="d3l_escapechar" value="$[5];" order="3" /> </assignments>
Having defined and named the assignments block, it can now be referenced in Example A-34 in a field using the assign attribute:
<struct id="MessageEnvelope" terminatorchar="$LineSep;"> <field name="Separators" assign="GetSeparators"> <simplestring /> </field> <field name="Header"> <simplestring /> </field> ...
After the field "Separators" has been parsed, the associated assignments block "GetSeparators" is triggered and executed. All the value references in the block refer to the current field value ("$[n];", with no field name between "$" and "[").
If the input stream for the "Separators" field is as follows:
$:$*$/$.
the following assignments occur:
ItemSep = ':' d3l_contchar = '*' d3l_escapechar = '/'
If the $LineSep variable was also updated in this assignments block (not a typical use case), the subsequent fields in the "MessageEnvelope" struct must be separated by the character assigned to $LineSep.
The D3L message root element <message> supports an attribute parsemode that can either assume the value lenient or strict:
<message name="myNativeType" parsemode="strict|lenient" ...
This setting only impacts D3L structs, where fields are separated by a separatorchar or terminatorchar and where the fields from a certain point and for the rest of the struct are all optional. In addition, the enclosing structure (struct, limarray) must also declare a separator, so the embedded struct knows when to end.
In lenient mode, the trailing optional fields in a struct can be entirely omitted (that is, also including their delimiters). In strict parsemode, the delimiters have to be present for all fields, even though the field values themselves are empty.
Example A-35 shows an example:
<struct id="outer" terminatorchar="."> <field name="fields1"> <typeref type="inner" /> </field> <field name="fields2"> <typeref type="inner" /> </field> </struct> <struct id="inner" separatorchar=","> <field name="f1" optionality="R"> <simplestring /> </field> <field name="f2" optionality="R"> <simplestring /> </field> <field name="f3" optionality="R"> <simplestring /> </field> <field name="f4" optionality="R"> <simplestring /> </field> <field name="f5" optionality="R"> <simplestring /> </field> <field name="f6" optionality="R"> <simplestring /> </field> <field name="f7" optionality="O"> <simplestring /> </field> <field name="f8" optionality="O"> <simplestring /> </field> <field name="f9" optionality="O"> <simplestring /> </field> </struct>
In lenient mode, the following input is parseable:
"1,2,3,4,5,6.1,2,3,4,5,6."
Note that the values for fields "f7", "f8" and, "f9" are missing, including their delimiters. In strict mode, the field values can still be empty, but the separators must be present:
"1,2,3,4,5,6,,,.1,2,3,4,5,6,,,."
To improve the general readability, maintainability, or both of D3L definitions, a type aliasing feature (typedef) is available. It enables you to assign other names to already-defined types. It also permits defining type structures without needing to define embedded fields.
Example A-36 shows an example:
<termstring id="BaseString" endchar="," /> <typedef id="NameType"> <typeref type="BaseString" /> </typedef> <typedef id="PhoneType"> <typeref type="BaseString" /> </typedef> <struct id="ContactType"> <field name="Name"> <typeref type="NameType"/> </field> <field name="Phone"> <typeref type="PhoneType"/> </field> </struct> <typedef name="MainContactType"> <typeref type="ContactType"> </typedef> <typedef name="SecondaryContactType"> <typeref type="ContactType"> </typedef>
This feature provides a limited form of conditional parsing in D3L. It essentially enables you to qualify a D3L struct definition with a sequence of bytes or characters. This sequence must occur at the beginning of the struct for D3L to start parsing the message according to the struct. This starting byte or character sequence can be declared through the struct attribute startswith.
The D3L definitions shown in Example A-37 are now possible:
<struct id="Order" terminatorchar="\n"> <field name="Header" optionality="R"> <typeref type="HeaderType" /> </field> <field name="Discount" optionality="O"> <typeref type="DiscountType" /> </field> <field name="Total" optionality="R"> <typeref type="TotalType" /> </field> </struct> <struct id="HeaderType" startswith="HDR"> <field name="CustomerID"> <typeref type="ID" /> </field> ... </struct> <struct id="DiscountType" startswith="DIS"> <field name="Percentage"> <typeref type="PCT" /> </field> ... </struct> <struct id="TotalType" startswith="TOT"> <field name="TotalAmount"> <typeref type="AMT" /> </field> ... </struct>
This code parses an input stream of the following type:
HDR00032101.... DIS015.75... TOT00045000.00...
In Example A-37, if the line starting with DIS... is missing, the whole Discount field ("DiscountType" struct) is skipped (that is, assigned a blank value).
D3L provides a limited method for performing validation of native events, essentially validating that specific field contents are valid against a set of valid values.
Example A-38 shows a table (set) of valid values:
<validvalues id="table_0267" comment="Days of the week valid values"> <validvalue comment="Monday">MON</validvalue> ... <validvalue comment="Friday">FRI</validvalue> </validvalues>
The comments are only for documentation purposes. Through the id attribute of the validvalues block, you can link it to a field through the field attribute validvalues, as shown in Example A-39.
<struct id="VisitingDays" separatorchar=","> <field name="StartDay" validvalues="table_0267"> <simplestring /> </field> <field name="EndDay" validvalues="table_0267"> <simplestring /> </field> </struct>
This successfully validates the following native message:
WED,FRI
But not this native message:
WED,SUN
If a field contains a nonvalid value, D3L stops the message parsing and reports an error. However, this behavior can be altered slightly by using the attribute validation in the D3L message root element.
If this attribute has the value "full"assigned:
<message name="Patient" validation="full" ...
then all validation errors for the entire native message are reported. If the attribute has the value "first" assigned:
<message name="Patient" validation="first" ...
then only the first validation error is reported. The first option provides completeness, while the second option provides better performance.
Strings that are part of a native message can be encoded in a character set different from the platform default. For example, the message may contain strings represented in Shift_JIS, while the platform default character set is US-ASCII.
D3L internally converts all native strings to Unicode. Therefore, whenever the default platform conversion is not sufficient (as is the case if the native strings are represented in Shift_JIS on non-Japanese machines), the exact Internet Assigned Numbers Authority (IANA) character set name for strings in the native message must be declared through the attribute encoding in the D3L message root element. For example:
<message name="Members" encoding="Shift_JIS" ...
When a native event body element (in the Create Event Body Element wizard) is associated with the D3L translator and D3L definition file, Oracle Application Server ProcessConnect creates a corresponding application event datatype in the repository.
This datatype reflects the XML format, which the D3L translator generates while translating (inbound) the native event body element to its corresponding application event body element. The reverse process takes place in the outbound direction.
The following sections describe how to determine the Oracle Application Server ProcessConnect application event datatype, which is created when importing a D3L definition:
Note that the datatype can be placed in a specific namespace, as shown in Figure A-2.
|
See Also:
"Providing D3L Details" for instructions on creating D3L event body elements |
All scalar D3L fields cause the creation of a scalar Oracle Application Server ProcessConnect datatype member with the name of the field name attribute:
<field name="PatientName" ..> <scalar-type ... /> </field>
If the scalar type of the field is referenced through a typeref, the referenced scalar type is looked up (or created if nonexistent and then looked up) and associated as the member type.
All nonscalar D3L fields (typerefs to structs or arrays) cause the creation of a complex Oracle Application Server ProcessConnect datatype with the name of the field name attribute.
With an array, the values for the complex Oracle Application Server ProcessConnect datatype attributes minOccurs and maxOccurs depend on the value of the D3L cardinality attribute. For example, the following definition:
<field name="EVN.7.1"> <limarray name="EVN.7.1_ARR" cardinality="*">
causes the creation of datatype "EVN.7.1" with the following settings:
minOccurs = 0 maxOccurs = unlimited
The D3L field attribute optionality similarly determines the value of minOccurs and maxOccurs ("R" ~ 1/1, "O" ~ 0/1).
All D3L structs cause the creation of a complex Oracle Application Server ProcessConnect datatype with the name of the name attribute and the datatype members named after the field names. The type of each member is either scalar or complex, depending on whether or not the D3L field type is scalar or structured.
<struct id="CusType" name="CustomerType" ...
For backwards compatibility, if the struct name attribute is not present, the struct id attribute names the complex datatype.
All D3L typedefs cause the creation of a Oracle Application Server ProcessConnect datatype with the name of the type attribute of the typeref element:
<typedef id="EVN.7.1"> <typeref type="FixedString10" /> ..
The created datatype is scalar or complex according to the complexity of the typeref datatype.
All D3L typerefs cause the creation of a datatype with the name of the name attribute of the referenced D3L type (or the id attribute, if the name attribute is not present). Example A-40 shows an example.
<field name="MailAddress"> <typeref type="AddrTyp" /> ---> ... <struct id="AddrTyp" name="AddressType" ...
If a datatype is already present in the Oracle Application Server ProcessConnect design-time repository, D3L simply reuses it (that is, it is not replaced).
Example A-41 through Example A-44 show Oracle Application Server ProcessConnect datatypes created from D3L definitions.
<struct id="ADT-A29" name="ADT-A29.CONTENT" terminatorchar="\r"> <field name="MSH" optionality="R"> <typeref type="MSH" /> </field> <field name="EVN" optionality="R"> <typeref type="EVN" /> </field> </struct>
Oracle Application Server ProcessConnect datatype created from Example A-41:
Datatype :ADT-A29.CONTENT ApplicationEvent CompoundMember :MSH refersTo=MSH.CONTENT cardinality[1,1] CompoundMember :EVN refersTo=EVN.CONTENT cardinality[1,1]
It is implied that MSH.CONTENT and EVN.CONTENT are referring to nonscalar types.
struct id="MSH" name="MSH.CONTENT" startswith="MSH" separatorchar="|"> <field name="MSH.1" optionality="R"> <typeref type="FIX1" /> </field> <field name="MSH.2" optionality="O"> <typeref type="MSH.2" /> </field> <field name="MSH.3" optionality="R"> <typeref type="MSH.3" /> </field> <field name="MSH.4" optionality="R"> <typeref type="MSH.4" /> </field> <field name="MSH.5"> <limarray name="MSH.5_ARR" cardinality="*"> <typeref type="MSH.5" /> </limarray> </field> <field name="MSH.6" optionality="R"> <typeref type="MSH.6" /> </field> <field name="MSH.7"> <limarray name="MSH.7_ARR" cardinality="+"> <typeref type="MSH.7" /> </limarray> </field> </struct>
Oracle Application Server ProcessConnect datatype created from Example A-42:
Datatype :MSH.CONTENT ApplicationEvent ScalarMember :MSH.1 scalarType=FIX1 ScalarMember :MSH.2 scalarType=ST CompoundMember :MSH.3 refersTo=MSH.3.CONTENT cardinality[1,1] CompoundMember :MSH.4 refersTo=MSH.4.CONTENT cardinality[1,1] CompoundMember :MSH.5 refersTo=MSH.5.CONTENT cardinality[0,unlimited] CompoundMember :MSH.6 refersTo=MSH.6.CONTENT cardinality[1,1] CompoundMember :MSH.7 refersTo=MSH.9.CONTENT cardinality[1,unlimited]
It is implied that MSH.[3,4,6].CONTENT are referring to nonscalar types.
<typedef id="MSH.1"> <typeref type="FIX1" /> </typedef> <typedef id="MSH.2"> <typeref type="ST" /> </typedef> <typedef id="MSH.3"> <typeref type="IS" /> </typedef> <typedef id="MSH.4"> <typeref type="ID" /> </typedef>
Oracle Application Server ProcessConnect Datatype created from Example A-43:
Datatype :FIX1 ApplicationEvent primitiveType:string Datatype :ST ApplicationEvent primitiveType:string Datatype :IS ApplicationEvent primitiveType:string Datatype :ID ApplicationEvent primitiveType:string
<struct id="MSH.3" name="MSH.3.CONTENT" separatorchar="^"> <field name="MSH.3.1" optionality="R"> <typeref type="MSH.3.1" /> </field> <field name="MSH.3.2" optionality="O"> <typeref type="MSH.3.2" /> </field> <field name="MSH.3.3" optionality="R"> <typeref type="MSH.3.3" /> </field> <field name="MSH.3.4" optionality="R"> <typeref type="MSH.3.4" /> </field> </struct>
Oracle Application Server ProcessConnect datatype created from Example A-44:
Datatype :MSH.3.CONTENT ApplicationEvent ScalarMember :MSH.3.1 scalarType=ST ScalarMember :MSH.3.2 scalarType=IS ScalarMember :MSH.3.3 scalarType=ST ScalarMember :MSH.3.4 scalarType=ID
Note how typeref "MSH.3.1" resolves to ST. This is likely due the following definition elsewhere:
<typedef id="MSH.3.1"> <typeref type="ST" /> </typedef>
This section contains these topics:
This section provides some D3L sample files. These example files describe how to use the D3L language to define the content of wire messages.
Sample file msg-1.xml represents a structure named VehicleRegistration. Table A-5 describes the D3L fields and Example A-45 shows the msg-1.xml D3L definition.
<?xml version="1.0" encoding="US-ASCII"?> <message type="VehicleRegistration" name="Register"><date format="MMDDYYYY" id="Date_T"><padstring id="FixString10_T" length="10" padchar='' padstyle="none" /></date> <struct id="VehicleRegistration"><!-- Width x Length x Height x Weight (inch/lb) --> <field name="SizeWeight"><typeref type="ShortArray4_T" /></field> <field name="ProductCode"><unsigned2 align="2" endian="big" /></field> <field name="VIN"><unsigned8 align="2" endian="big" /></field> <field name="PreviousOwners"><typeref type="StringArray_T" /></field> <field name="Miles"><unsigned2 align="2" endian="big" /></field> <field name="DateProduced"><typeref type="Date_T" /></field></struct> <fixarray id="ShortArray4_T" length="4"><unsigned2 align="2" endian="little" id="" /></fixarray> <unsigned1 align="2" endian="little" id="Short_T" /> <pfxarray id="StringArray_T" length="Short_T"><typeref type="FixString10_T" /></pfxarray></message>
Note that some type declarations are defined while being used by another structure. Remember that only fields map to actual bytes in the wire message.
The following wire message examples show a hexadecimal and character representation of the same message, which can be parsed by the msg-1.xml D3L file:
0000000 4500 b200 3400 8a0b 30d9 0000 0000 00720000020 55ff 0200 4a6f 6e65 732c 502e 2020 536d0000040 6974 682c 522e 2020 5208 3131 2532 32250000060 3139 3939
0000000 E \0 262 \0 4 \0 212 013 0 331 \0 \0 \0 \0 \0 r0000020 U 377 002 \0 J o n e s , P . S m0000040 i t h , R . R \b 1 1 % 2 2 %0000060 1 9 9 9
Sample file msg-2.xml demonstrates a structure hierarchy named PersonRecord. Table A-6 describes the D3L fields and Example A-46 shows the msg-2.xml D3L definition.
<?xml version="1.0" encoding="US-ASCII"?> <!DOCTYPE message SYSTEM "d3l.dtd"> <message type="PersonRecord" name="Person"> <signed4 id="s4" /> <struct id="CityRecord"> <field name="Name"><limstring delimiter="*" /></field> <field name="State"><limstring delimiter="*" /></field> <field name="Country"><limstring delimiter="," /></field> <field name="Population"><unsigned4 /></field> </struct> <struct id="StateRecord"> <field name="Name"><limstring delimiter=" " /></field> <field name="Capital"><limstring delimiter=" " /></field> <field name="Population"><unsigned4 /></field> </struct> <struct id="PersonRecord"> <field name="Name"><limstring delimiter="," /></field> <field name="Age"><unsigned1 /></field> <field name="DOB"> <date format="MMDDYYYY"> <pfxstring id="dobstr" length="s4" /> </date> </field> <field name="Phone"><unsigned4 /></field> <field name="City"><typeref type="CityRecord" /></field> <field name="State"><typeref type="StateRecord" /></field> </struct> </message>
The following is a combined hexadecimal and character representation of a native message, which can be parsed by msg-2.xml:
000 2c4a 6f68 6e20 446f 652c 1e00 0000 000a ,John Doe,_..... 020 3131 2f32 352f 3139 3635 0000 002c a155 11/25/1965...,.U 040 2a50 6f72 746c 616e 642a 2a4f 522a 2c55 *Portland**OR*,U 060 5341 2c00 000f 4240 204f 7265 676f 6e20 SA,...B@_Oregon_ 100 2053 616c 656d 2000 003d 0900 _Salem_..=..
Sample file msg-3.xml defines a structure named ProductRecord. Table A-7 describes the file fields and Example A-47 shows msg-3.xml file contents.
| Field | Description |
|---|---|
|
|
A string delimited by a space |
|
|
A single-precision, floating-point number |
|
|
A length-prefixed array of |
<?xml version="1.0" encoding="US-ASCII"?> <!DOCTYPE message SYSTEM "d3l.dtd"> <message type="ProductRecord" name="Product"> <unsigned1 id="u1" /> <unsigned2 id="u2" /> <number id="pfxnum"> <padstring length="8" padchar="" padstyle="none" /> </number> <pfxarray id="Unsigned1Tab" length="u1"> <unsigned1 /> </pfxarray> <pfxarray id="Signed4Tab" length="pfxnum"> <unsigned4 /> </pfxarray> <pfxarray id="StrTab" length="u1"> <limstring delimiter=" " /> </pfxarray> <struct id="WidgetRecord"> <field name="Name"><limstring delimiter=" " /></field> <field name="Color"><limstring delimiter=" " /></field> <field name="Weight"><float /></field> </struct> <pfxarray id="WidgetTab" length="u2"> <typeref type="WidgetRecord" /> </pfxarray> <struct id="ProductRecord"> <field name="Manufacturer"><limstring delimiter=" " /></field> <field name="Weight"><float /></field> <field name="Widgets"><typeref type="WidgetTab" /></field> </struct> </message>
Oracle Application Server ProcessConnect provides two DTDs to which D3L (XML) files must conform. Example A-48 shows the first DTD (D3L.dtd) to which D3L (XML) files can conform. This file contains actual message definitions. Example A-49 shows the second DTD file (D3L-definitions.dtd). This file contains declarations (importable and by reference), and no actual message definitions. This enables you to divide D3L documents into smaller, more manageable units (modules or separate files).
<?xml version="1.0" encoding="US-ASCII"?> <!-- ======================================================== --> <!ENTITY % Name "CDATA" > <!ENTITY % Number "NMTOKEN" > <!ENTITY % Comment "CDATA" > <!ENTITY % IdRef "CDATA" > <!-- ======================================================== --> <!ENTITY % DocumentationAttributes " name %Name; #IMPLIED comment %Comment; #IMPLIED " > <!ENTITY % GenericAttributes " %DocumentationAttributes; id ID #IMPLIED " > <!ENTITY % MandatoryGenericAttributes " %DocumentationAttributes; id ID #REQUIRED " > <!-- NEW --> <!ELEMENT validvalue EMPTY> <!ATTLIST validvalue %DocumentationAttributes; value CDATA #REQUIRED > <!ENTITY % ValidValues " validvalue " > <!ELEMENT validvalues ( %ValidValues; )* > <!ATTLIST validvalues %GenericAttributes; > <!ENTITY % Optionality "( R | O )" > <!ENTITY % Cardinality "CDATA" > <!ENTITY % FieldAttributes " name %Name; #REQUIRED comment %Comment; #IMPLIED id ID #IMPLIED optionality %Optionality; #IMPLIED validvalues IDREF #IMPLIED assign IDREF #IMPLIED " > <!ENTITY % NonTypeAttributes " name %Name; #IMPLIED comment %Comment; #IMPLIED " > <!-- ======================================================== --> <!-- NEW --> <!ENTITY % SeparatorChar "CDATA" > <!ENTITY % TerminatorChar "CDATA" > <!ENTITY % StructAttributes " %GenericAttributes; startswith CDATA #IMPLIED separatorchar %SeparatorChar; #IMPLIED terminatorchar %TerminatorChar; #IMPLIED " > <!-- ======================================================== --> <!ENTITY % Align "%Number;" > <!ENTITY % IntegerSize "( 1 | 2 | 4 | 8 )" > <!ENTITY % Endian "( big | little )" > <!ENTITY % IntegerAttributes " %GenericAttributes; endian %Endian; 'big' " > <!ENTITY % IntegerTypes " signed1 | unsigned1 | signed2 | unsigned2 | signed4 | unsigned4 | signed8 | unsigned8 " > <!ENTITY % FloatAttributes " %GenericAttributes; " > <!ENTITY % FloatTypes " float | double " > <!-- ======================================================== --> <!ENTITY % PadStyle "( head | tail | none )" > <!ENTITY % PadChar "CDATA" > <!ENTITY % DelimiterChar "CDATA" > <!ENTITY % StringAttributes " %GenericAttributes; " > <!ENTITY % SimpleStringAttributes " %StringAttributes; " > <!ENTITY % TerminatedStringAttributes " %StringAttributes; endchar %DelimiterChar; #REQUIRED " > <!ENTITY % PaddedStringAttributes " %StringAttributes; length %Number; #REQUIRED padchar %PadChar; #REQUIRED padstyle %PadStyle; #REQUIRED endchar %PadChar; #IMPLIED " > <!ENTITY % PrefixedStringAttributes " %StringAttributes; length IDREF #REQUIRED " > <!ENTITY % DelimitedStringAttributes " %StringAttributes; delimiter %DelimiterChar; #REQUIRED " > <!ENTITY % StringTypes "padstring | pfxstring | limstring | termstring | simplestring" > <!-- ======================================================== --> <!ENTITY % DateFormat "( DDMMYY | DDMMYYYY | MMDDYY | MMDDYYYY | MMDDYYYY_HHMI | MMDDYYYY_HHMISS | MMDDYYYY_HHMISS_Z )" > <!ENTITY % DateAttributes " %GenericAttributes; format %DateFormat; #REQUIRED " > <!-- ======================================================== --> <!ENTITY % NumberAttributes " %GenericAttributes; " > <!-- ======================================================== --> <!ENTITY % ArrayAttributes " %GenericAttributes; " > <!ENTITY % FixedArrayAttributes " %ArrayAttributes; length %Number; #REQUIRED " > <!ENTITY % PrefixedArrayAttributes " %ArrayAttributes; length IDREF #REQUIRED " > <!ENTITY % DelimitedArrayAttributes " %ArrayAttributes; cardinality %Cardinality; #IMPLIED contchar %DelimiterChar; #IMPLIED endchar %DelimiterChar; #IMPLIED delimiter %DelimiterChar; #IMPLIED " > <!ENTITY % ImplicitArrayAttributes " %ArrayAttributes; " > <!-- ======================================================== --> <!ENTITY % ScalarElements " signed1 | unsigned1 | signed2 | unsigned2 | signed4 | unsigned4 | signed8 | unsigned8 | float | double | date | number | padstring | pfxstring | limstring | termstring | simplestring " > <!-- NEW --> <!ENTITY % FileName "CDATA" > <!ELEMENT assign EMPTY > <!ATTLIST assign %DocumentationAttributes; variable %IdRef; #REQUIRED value CDATA #REQUIRED order %Number; #IMPLIED > <!ENTITY % Assignments " assign " > <!ELEMENT assignments ( %Assignments; )* > <!ATTLIST assignments %GenericAttributes; > <!ENTITY % Default "CDATA" > <!ENTITY % MaximumLength "%Number;" > <!ELEMENT variable EMPTY > <!ATTLIST variable %MandatoryGenericAttributes; default %Default; #IMPLIED maxlen %MaximumLength; "1" > <!ENTITY % VariableDeclaration " variable " > <!ELEMENT variables ( %VariableDeclaration; )* > <!ATTLIST variables %GenericAttributes; > <!ELEMENT value-map EMPTY > <!ATTLIST value-map %DocumentationAttributes; native CDATA #REQUIRED translated CDATA #REQUIRED > <!ENTITY % EscapedValuesMapDeclaration " value-map " > <!ELEMENT escaped-values-map ( %EscapedValuesMapDeclaration; )* > <!ATTLIST escaped-values-map %GenericAttributes; > <!ENTITY % TypeElements "%ScalarElements; | struct | fixarray | pfxarray | limarray | imparray " > <!ENTITY % MetaElements " assignments | escaped-values-map | typedef | validvalues | variables " > <!-- ======================================================== --> <!ENTITY % FieldElements "%TypeElements;" > <!ENTITY % MessageElements "%TypeElements; | %MetaElements;" > <!ENTITY % StructElements "field | pad" > <!ENTITY % ArrayElements "%ScalarElements; | struct" > <!ENTITY % EscapeMethod_Prefix "prefixed" > <!ENTITY % EscapeMethod_Enclosed "enclosed" > <!ENTITY % EscapeMethod "( %EscapeMethod_Prefix; | %EscapeMethod_Enclosed; )" > <!ENTITY % ParseMode_Strict "strict" > <!ENTITY % ParseMode_Lenient "lenient" > <!ENTITY % ParseMode "( %ParseMode_Strict; | %ParseMode_Lenient; )" > <!ENTITY % ValidationMode_First "first" > <!ENTITY % ValidationMode_Full "full" > <!ENTITY % ValidationMode "( %ValidationMode_First; | %ValidationMode_Full; )" > <!-- ======================================================== --> <!ELEMENT message ( %MessageElements; )* > <!ATTLIST message name %Name; #REQUIRED type IDREF #REQUIRED comment %Comment; #IMPLIED id ID #IMPLIED escaping %EscapeMethod; 'prefixed' parsemode %ParseMode; 'strict' validation %ValidationMode; 'first' encoding CDATA #IMPLIED > <!-- ======================================================== --> <!ELEMENT struct ( %StructElements; )* > <!ATTLIST struct %StructAttributes; > <!-- ======================================================== --> <!ELEMENT field ( typeref | %FieldElements; ) > <!ATTLIST field %FieldAttributes; > <!-- ======================================================== --> <!ELEMENT typedef ( typeref | %TypeElements; ) > <!ATTLIST typedef %MandatoryGenericAttributes; validvalues IDREF #IMPLIED > <!-- ======================================================== --> <!ELEMENT signed1 EMPTY > <!ATTLIST signed1 %IntegerAttributes; size %IntegerSize; #FIXED "1" align %Align; "1" > <!ELEMENT unsigned1 EMPTY > <!ATTLIST unsigned1 %IntegerAttributes; size %IntegerSize; #FIXED "1" align %Align; "1" > <!ELEMENT signed2 EMPTY > <!ATTLIST signed2 %IntegerAttributes; size %IntegerSize; #FIXED "2" align %Align; "2" > <!ELEMENT unsigned2 EMPTY > <!ATTLIST unsigned2 %IntegerAttributes; size %IntegerSize; #FIXED "2" align %Align; "2" > <!ELEMENT signed4 EMPTY > <!ATTLIST signed4 %IntegerAttributes; size %IntegerSize; #FIXED "4" align %Align; "4" > <!ELEMENT unsigned4 EMPTY > <!ATTLIST unsigned4 %IntegerAttributes; size %IntegerSize; #FIXED "4" align %Align; "4" > <!ELEMENT signed8 EMPTY > <!ATTLIST signed8 %IntegerAttributes; size %IntegerSize; #FIXED "8" align %Align; "8" > <!ELEMENT unsigned8 EMPTY > <!ATTLIST unsigned8 %IntegerAttributes; size %IntegerSize; #FIXED "8" align %Align; "8" > <!-- ======================================================== --> <!ELEMENT float EMPTY > <!ATTLIST float %FloatAttributes; align %Align; "4" > <!ELEMENT double EMPTY > <!ATTLIST double %FloatAttributes; align %Align; "8" > <!-- ======================================================== --> <!ELEMENT padstring EMPTY > <!ATTLIST padstring %PaddedStringAttributes; > <!ELEMENT pfxstring EMPTY > <!ATTLIST pfxstring %PrefixedStringAttributes; > <!ELEMENT limstring EMPTY > <!ATTLIST limstring %DelimitedStringAttributes; > <!-- NEW --> <!ELEMENT simplestring EMPTY > <!ATTLIST simplestring %SimpleStringAttributes; > <!ELEMENT termstring EMPTY > <!ATTLIST termstring %TerminatedStringAttributes; > <!-- ======================================================== --> <!ELEMENT fixarray ( typeref | %ArrayElements; ) > <!ATTLIST fixarray %FixedArrayAttributes; > <!ELEMENT pfxarray ( typeref | %ArrayElements; ) > <!ATTLIST pfxarray %PrefixedArrayAttributes; > <!ELEMENT limarray ( typeref | %ArrayElements; ) > <!ATTLIST limarray %DelimitedArrayAttributes; > <!ELEMENT imparray ( typeref | %ArrayElements; ) > <!ATTLIST imparray %ImplicitArrayAttributes; > <!-- ======================================================== --> <!ELEMENT date ( typeref | %StringTypes; ) > <!ATTLIST date %DateAttributes; > <!-- ======================================================== --> <!ELEMENT number ( typeref | %StringTypes; ) > <!ATTLIST number %NumberAttributes; > <!-- ======================================================== --> <!ELEMENT typeref EMPTY > <!ATTLIST typeref %NonTypeAttributes; type %IdRef; #REQUIRED > <!-- ======================================================== --> <!ELEMENT pad EMPTY > <!ATTLIST pad %NonTypeAttributes; length %Number; #REQUIRED > <!-- ======================================================== -->
<?xml version="1.0" encoding="US-ASCII"?> <!-- ======================================================== --> <!ENTITY % Name "CDATA" > <!ENTITY % Number "NMTOKEN" > <!ENTITY % Comment "CDATA" > <!ENTITY % IdRef "CDATA" > <!-- ======================================================== --> <!ENTITY % DocumentationAttributes " name %Name; #IMPLIED comment %Comment; #IMPLIED " > <!ENTITY % GenericAttributes " %DocumentationAttributes; id ID #IMPLIED " > <!ENTITY % MandatoryGenericAttributes " %DocumentationAttributes; id ID #REQUIRED " > <!-- NEW --> <!ENTITY % FileName "CDATA" > <!ELEMENT validvalue EMPTY> <!ATTLIST validvalue %DocumentationAttributes; value CDATA #REQUIRED > <!ENTITY % ValidValues " validvalue " > <!ELEMENT validvalues ( %ValidValues; )* > <!ATTLIST validvalues %GenericAttributes; > <!ELEMENT assign EMPTY > <!ATTLIST assign %DocumentationAttributes; variable %IdRef; #REQUIRED value CDATA #REQUIRED order %Number; #IMPLIED > <!ENTITY % Assignments " assign " > <!ELEMENT assignments ( %Assignments; )* > <!ATTLIST assignments %GenericAttributes; > <!ENTITY % Default "CDATA" > <!ENTITY % MaximumLength "%Number;" > <!ELEMENT variable EMPTY > <!ATTLIST variable %MandatoryGenericAttributes; default %Default; #IMPLIED maxlen %MaximumLength; "1" > <!ENTITY % VariableDeclaration " variable " > <!ELEMENT variables ( %VariableDeclaration; )* > <!ATTLIST variables %GenericAttributes; > <!ELEMENT value-map EMPTY > <!ATTLIST value-map %DocumentationAttributes; native CDATA #REQUIRED translated CDATA #REQUIRED > <!ENTITY % EscapedValuesMapDeclaration " value-map " > <!ELEMENT escaped-values-map ( %EscapedValuesMapDeclaration; )* > <!ATTLIST escaped-values-map %GenericAttributes; > <!-- NEW --> <!ENTITY % ImportAttributes " location %FileName; #REQUIRED " > <!ELEMENT import EMPTY > <!ATTLIST import %ImportAttributes; > <!ENTITY % Optionality "( R | O )" > <!ENTITY % Cardinality "CDATA" > <!ENTITY % FieldAttributes " name %Name; #REQUIRED comment %Comment; #IMPLIED id ID #IMPLIED optionality %Optionality; #IMPLIED validvalues IDREF #IMPLIED assign IDREF #IMPLIED " > <!ENTITY % NonTypeAttributes " name %Name; #IMPLIED comment %Comment; #IMPLIED " > <!-- ======================================================== --> <!-- NEW --> <!ENTITY % SeparatorChar "CDATA" > <!ENTITY % TerminatorChar "CDATA" > <!ENTITY % StructAttributes " %GenericAttributes; startswith CDATA #IMPLIED separatorchar %SeparatorChar; #IMPLIED terminatorchar %TerminatorChar; #IMPLIED " > <!-- ======================================================== --> <!ENTITY % Align "%Number;" > <!ENTITY % IntegerSize "( 1 | 2 | 4 | 8 )" > <!ENTITY % Endian "( big | little )" > <!ENTITY % IntegerAttributes " %GenericAttributes; endian %Endian; 'big' " > <!ENTITY % IntegerTypes " signed1 | unsigned1 | signed2 | unsigned2 | signed4 | unsigned4 | signed8 | unsigned8 " > <!ENTITY % FloatAttributes " %GenericAttributes; " > <!ENTITY % FloatTypes " float | double " > <!-- ======================================================== --> <!ENTITY % PadStyle "( head | tail | none )" > <!ENTITY % PadChar "CDATA" > <!ENTITY % DelimiterChar "CDATA" > <!ENTITY % StringAttributes " %GenericAttributes; " > <!ENTITY % PaddedStringAttributes " %StringAttributes; length %Number; #REQUIRED padchar %PadChar; #IMPLIED padstyle %PadStyle; #IMPLIED endchar %PadChar; #IMPLIED " > <!ENTITY % PrefixedStringAttributes " %StringAttributes; length IDREF #REQUIRED " > <!ENTITY % DelimitedStringAttributes " %StringAttributes; delimiter %DelimiterChar; #REQUIRED " > <!ENTITY % TerminatedStringAttributes " %StringAttributes; endchar %TerminatorChar; #REQUIRED " > <!ENTITY % StringTypes "padstring | pfxstring | limstring | simplestring | termstring" > <!-- ======================================================== --> <!ENTITY % DateFormat "( DDMMYY | DDMMYYYY | MMDDYY | MMDDYYYY | MMDDYYYY_HHMI | MMDDYYYY_HHMISS | MMDDYYYY_HHMISS_Z )" > <!ENTITY % DateAttributes " %GenericAttributes; format %DateFormat; #REQUIRED " > <!-- ======================================================== --> <!ENTITY % NumberAttributes " %GenericAttributes; " > <!-- ======================================================== --> <!ENTITY % ArrayAttributes " %GenericAttributes; " > <!ENTITY % FixedArrayAttributes " %ArrayAttributes; length %Number; #REQUIRED " > <!ENTITY % PrefixedArrayAttributes " %ArrayAttributes; length IDREF #REQUIRED " > <!ENTITY % DelimitedArrayAttributes " %ArrayAttributes; cardinality %Cardinality; #IMPLIED contchar %DelimiterChar; #IMPLIED endchar %DelimiterChar; #IMPLIED delimiter %DelimiterChar; #IMPLIED " > <!ENTITY % ImplicitArrayAttributes " %ArrayAttributes; " > <!-- ======================================================== --> <!ENTITY % ScalarElements " signed1 | unsigned1 | signed2 | unsigned2 | signed4 | unsigned4 | signed8 | unsigned8 | float | double | date | number | padstring | pfxstring | limstring | simplestring | termstring " > <!ENTITY % TypeElements "%ScalarElements; | struct | fixarray | pfxarray | limarray | imparray " > <!-- NEW --> <!ENTITY % MetaElements " assignments | escaped-values-map | import | typedef | validvalues | variables " > <!-- ======================================================== --> <!ENTITY % FieldElements "%TypeElements;" > <!-- NEW --> <!ENTITY % DefinitionElements "%TypeElements; | %MetaElements;" > <!ENTITY % StructElements "field | pad" > <!ENTITY % ArrayElements "%ScalarElements; | struct" > <!-- ======================================================== --> <!ELEMENT definitions ( %DefinitionElements; )* > <!ATTLIST definitions name %Name; #REQUIRED comment %Comment; #IMPLIED id ID #IMPLIED > <!-- ======================================================== --> <!ELEMENT struct ( %StructElements; )* > <!ATTLIST struct %StructAttributes; > <!-- ======================================================== --> <!ELEMENT field ( typeref | %FieldElements; ) > <!ATTLIST field %FieldAttributes; > <!-- ======================================================== --> <!ELEMENT typedef ( typeref | %TypeElements; ) > <!ATTLIST typedef %MandatoryGenericAttributes; validvalues IDREF #IMPLIED > <!-- ======================================================== --> <!ELEMENT signed1 EMPTY > <!ATTLIST signed1 %IntegerAttributes; size %IntegerSize; #FIXED "1" align %Align; "1" > <!ELEMENT unsigned1 EMPTY > <!ATTLIST unsigned1 %IntegerAttributes; size %IntegerSize; #FIXED "1" align %Align; "1" > <!ELEMENT signed2 EMPTY > <!ATTLIST signed2 %IntegerAttributes; size %IntegerSize; #FIXED "2" align %Align; "2" > <!ELEMENT unsigned2 EMPTY > <!ATTLIST unsigned2 %IntegerAttributes; size %IntegerSize; #FIXED "2" align %Align; "2" > <!ELEMENT signed4 EMPTY > <!ATTLIST signed4 %IntegerAttributes; size %IntegerSize; #FIXED "4" align %Align; "4" > <!ELEMENT unsigned4 EMPTY > <!ATTLIST unsigned4 %IntegerAttributes; size %IntegerSize; #FIXED "4" align %Align; "4" > <!ELEMENT signed8 EMPTY > <!ATTLIST signed8 %IntegerAttributes; size %IntegerSize; #FIXED "8" align %Align; "8" > <!ELEMENT unsigned8 EMPTY > <!ATTLIST unsigned8 %IntegerAttributes; size %IntegerSize; #FIXED "8" align %Align; "8" > <!-- ======================================================== --> <!ELEMENT float EMPTY > <!ATTLIST float %FloatAttributes; align %Align; "4" > <!ELEMENT double EMPTY > <!ATTLIST double %FloatAttributes; align %Align; "8" > <!-- ======================================================== --> <!ELEMENT padstring EMPTY > <!ATTLIST padstring %PaddedStringAttributes; > <!ELEMENT pfxstring EMPTY > <!ATTLIST pfxstring %PrefixedStringAttributes; > <!ELEMENT limstring EMPTY > <!ATTLIST limstring %DelimitedStringAttributes; > <!-- NEW --> <!ELEMENT simplestring EMPTY > <!ATTLIST simplestring %StringAttributes; > <!ELEMENT termstring EMPTY > <!ATTLIST termstring %TerminatedStringAttributes; > <!-- ======================================================== --> <!ELEMENT fixarray ( typeref | %ArrayElements; ) > <!ATTLIST fixarray %FixedArrayAttributes; > <!ELEMENT pfxarray ( typeref | %ArrayElements; ) > <!ATTLIST pfxarray %PrefixedArrayAttributes; > <!ELEMENT limarray ( typeref | %ArrayElements; ) > <!ATTLIST limarray %DelimitedArrayAttributes; > <!ELEMENT imparray ( typeref | %ArrayElements; ) > <!ATTLIST imparray %ImplicitArrayAttributes; > <!-- ======================================================== --> <!ELEMENT date ( typeref | %StringTypes; ) > <!ATTLIST date %DateAttributes; > <!-- ======================================================== --> <!ELEMENT number ( typeref | %StringTypes; ) > <!ATTLIST number %NumberAttributes; > <!-- ======================================================== --> <!ELEMENT typeref EMPTY > <!ATTLIST typeref %NonTypeAttributes; type %IdRef; #REQUIRED > <!-- ======================================================== --> <!ELEMENT pad EMPTY > <!ATTLIST pad %NonTypeAttributes; length %Number; #REQUIRED > <!-- ======================================================== -->
Token substituted text specifies the subject and message bodies of alert e-mail messages used with the step return code port. Token substituted text is free-form text interspersed with tokens representing values that can be filled in at runtime. The token substituted text converter creates an application type that has members for each of the tokens. You then define a transformation to populate these values. This produces the appropriate event type for delivery to an E-Mail adapter. The token substituted text translator substitutes the values into the text for outbound messages and parses the message for the token values for inbound messages.
|
See Also:
The following sections for additional token substituted text tasks:
|
Alert e-mails consist of subject and message bodies. The definition file records the name and definition of the text for subject and message bodies of alert e-mail messages. The file is divided into sections identified by lines starting with #:
# ENCODING ASCII_based_IANA_character_set # COMMENT comment_text # NAME Datatype_name # IDENTIFIER Identifier_token_value # DEFINITION Definition_including_token_substitutions
The DEFINITION section consists of free-form text where spaces and new lines appear in the output. For inbound translations, the text is parsed as long as the definition matches the start of the text (that is, trailing text is not significant). To indicate the use of a substituted value, the user inserts the following into the text:
{TOKEN_NAME}
ROLE_NAME or STEP_NAME are examples of tokens.
The following restrictions apply to substituted value use:
The token IDENTIFIER has a special meaning because it can uniquely identify the e-mail message type from all others. If you use this token, you must specify the value in the IDENTIFIER section. This is to allow identification of reply e-mails using event maps.
If you want to use a reserved character (#, {, \, and }) in the DEFINITION text, precede it with a backslash (\) as an escape character.
|
See Also:
"Inbound E-Mail Responses to an Alert E-Mail" for an example of |
Example A-50 shows the NAME and DEFINITION sections of the subject body of an alert e-mail. In the DEFINITION section, the tokens ROLE_NAME and STEP_NAME are substituted with values at runtime.
# NAME TRANSFORM_ALERT_SUBJECT # DEFINITION {ROLE_NAME}.{STEP_NAME} transformation failure
Example A-51 shows the NAME and DEFINITION sections of the message body of an alert e-mail. In the DEFINITION section, the tokens STEP_NAME, ROLE_NAME, EVENT_ID, and ERROR_CODE are substituted with values at runtime.
# NAME TRANSFORM_ALERT_MESSAGE # DEFINITION Transformation step {STEP_NAME} failed in business process {ROLE_NAME} for purchase order {EVENT_ID} with error {ERROR_CODE}.
Example A-52 provides an example in which the subject body tokens shown in Example A-50 and the message body tokens shown in Example A-51 are substituted with values.
FROM: ip@oracle.com SUBJECT: my_po_bp.transform_po transformation failure Transformation step transform_po failed in business process my_po_bp for purchase order #12345 with error: Error -: AIP-10422: Transformation step callout failed during execution: oracle.tip.ts.transformation.api.exception.DomainResourceException: Error -: AIP-14004: Error in invoking domain value function lookupBusinessViewDomain.
The following tokens are substituted with these values at runtime:
STEP_NAME is replaced with the value transform_po. This value is a constant that comes from the event transformation map.
ROLE_NAME is replaced with the value my_po_bp. This value is a constant that comes from the event transformation map.
EVENT_ID is replaced with the value #12345. This value comes from the source purchase order.
ERROR_CODE is replaced with the value:
Error -: AIP-10422: Transformation step callout failed during execution: oracle.tip.ts.transformation.api.exception.DomainResourceException:
Error -: AIP-14004: Error in invoking domain value function lookupBusinessViewDomain.
This value comes from the return code error message.
The alert e-mail transformation populates the following application datatypes of the subject and message bodies with values. While these datatypes members are optional, Oracle recommends that you populate each with a value.
The application event consists of two event body elements:
For inbound e-mail responses to alert e-mails, the DEFINITION section requires an additional identifier to uniquely identify the e-mail response through event maps. Create the event map as a check for the existence of the root node. At runtime, this checks for the existence of the identifier.
For an e-mail response, this is typically the start of the subject line, which is a concatenation of Re: (or a similar localized reply identifier) and the initial words of the alert subject. A separate definition of the identifier enables you to define a more meaningful datatype name. For example, if the following e-mail is sent as an approval notification:
FROM: ip@oracle.com TO: david.thompson@oracle.com SUBJECT: Purchase Order number 12345 needs approval Purchase Order 12345 for amount 12500.00 requires your approval. Please reply with the word 'Approve' if you approve, or 'Disapprove' If this should not be approved.
and the response is:
FROM: david.thompson@oracle.com TO: ip@oracle.com SUBJECT: Re: Purchase Order number 12345 needs approval Approve
The response subject definition is:
# NAME PO_APPROVAL_RESPONSE_SUBJECT # IDENTIFIER Re: Purchase Order # DEFINITION {IDENTIFIER} number {PO_ID} needs approval
This results in an application datatype for PO_APPROVAL_RESPONSE_SUBJECT named PO_ID.
This appendix describes the prepackaged support provided for the XSD, D3L, and token substituted text native formats and translators.
|
|
 Copyright © 2003 Oracle Corporation. All Rights Reserved. |
|