第 6 章 検索について Web Publisher には、リモート サーバ上のドキュメントのプロパティや内容を検索できる機能があります。サーバでは、ファイルのインデックスが作成されるため、検索結果のファイルは、Web ブラウザで表示することができます。 この章では、次のトピックについて説明します。
Web Publisher には、リモート サーバ上のドキュメントのプロパティや内容を検索できる機能があります。サーバでは、ファイルのインデックスが作成されるため、検索結果のファイルは、Web ブラウザで表示することができます。
検索するデータの準備
検索の実行 (基本)
クエリ演算子の使用
コレクションの属性について
META タグ付きの属性
このドキュメントのインデックスが、上記の META タグで作成されている場合は、検索の際、作者、作成日時、製品の各フィールドに、該当する値を入力します。たとえば、「Writer <contains> Smith」や「PubDate > 1/1/00」などのクエリを入力することができます。
クエリの作成 - 検索条件を入力します。
検索結果の表示 - 入力した条件に一致するドキュメントが一覧表示されます。
ドキュメントの表示 - 検索結果の一覧から選択したドキュメントを表示させることができます。
ドキュメント情報コレクションの内容の表示 - 各コレクションで保持されている情報を確認することができます。
検索クエリの作成
検索結果の表示
コレクションの内容の表示
標準検索クエリ フォーム
高度な HTML 検索クエリ ページ
ガイド付き検索アプレット
Web ブラウザの場所フィールドに次の URL を入力します。
http://yourServer/search
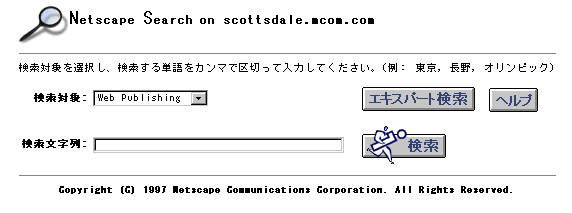
図 6.1 標準検索クエリ ページ
表示された検索クエリ ページで、[検索対象] フィールドのドロップダウン リストから検索対象となるコレクションを選択します。
[For] フィールドに検索クエリとして使用する単語またはフレーズを入力します。演算子を組み合わせて複雑なクエリを作成することもできます。検索演算子の詳細については、「クエリ演算子 (リファレンス)」を参照してください。
[検索] ボタンをクリックしてクエリを実行します。 個々のサーバではなくワールド ワイド ウェブを検索することもできます。これを行うには、[Web を検索] ボックスを使用して [検索] をクリックします。
Web ブラウザの場所フィールドに次の URL を入力して標準クエリ ページを表示させます。
ブラウザで Java を無効にします。これを行うには、[詳細] オプション プリファレンス メニューのコマンドを使用します。
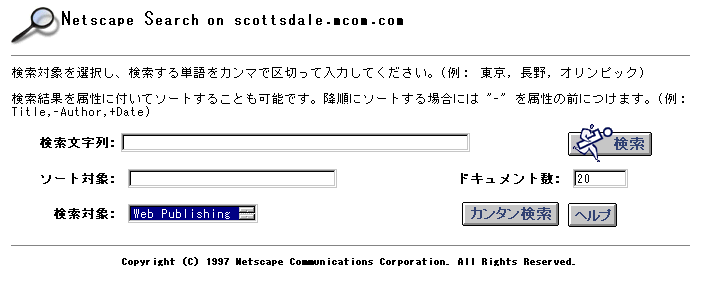
標準検索フォームの [ガイド付き検索] をクリックして高度な HTML クエリ ページを表示させます。 図 6.2 高度な HTML 検索クエリ ページ
図 6.2 高度な HTML 検索クエリ ページ
[For] フィールドに、検索する単語またはフレーズを入力します。演算子を組み合わせて複雑なクエリを作成することもできます。検索演算子の詳細については、「クエリ演算子 (リファレンス)」を参照してください。
属性値 (複数可) を入力して結果をその属性値に基づいてソートすることができます。デフォルトでは、昇順ソートですが、-Pubdate のように負の符号を付けることにより降順ソートにすることができます (ソートの詳細については、「結果のソート」を参照)。
検索結果ページの各ドキュメントのフィールド数や、一度に表示される数は、必要に応じて調節することができます。検索結果を一度に 1 ページに表示できない場合は、[前へ] や [次へ] ボタンを使用することにより、ほかのページにアクセスできます。
[検索対象] フィールドのドロップダウン リストを使用して検索対象となるコレクションを選択します。Ctrl キーを押しながらほかのコレクションをクリックすることにより、複数のコレクションを選択できます。1 つのクエリ内のすべてのコレクションは同じ言語である必要があります。
[検索] ボタンをクリックしてクエリを実行します。
ノートリンク管理やエージェント サービスの属性もリストに表示されますが、これらは Web Publisher 4.0 では使用できないため、これらの属性を選択しても有効な結果は得られません。
標準検索クエリ ページからガイド付き検索アプレットにアクセスするには、以下の操作を行います。
次の URL を入力して標準検索クエリ ページを表示させます。
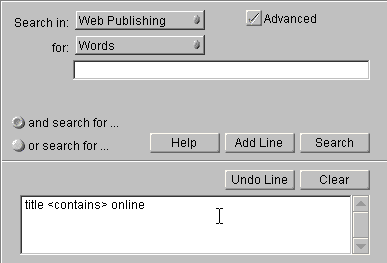
標準検索ページの [ガイド付き検索] をクリックすると、Java ベース ガイド付きクエリ ページが表示されます。 図 6.3 ガイド付き検索クエリ アプレット
図 6.3 ガイド付き検索クエリ アプレット
[検索対象] フィールドのリストから検索対象のコレクションを選択します。
[For] ボックスの一覧から検索項目の種類を選択します。この例では、[Words] を選択します。
空白のテキスト フィールドに、検索する単語を入力します。検索演算子の詳細については、「クエリ演算子 (リファレンス)」を参照してください。
[Add Line] をクリックし、クエリの最初の部分を追加します。フォームの下部にある大きなテキスト表示ボックスにその単語が表示されます。
ほかの検索項目をクエリに追加する場合は、ドロップダウン リストから該当する項目を選択します。この例では、[属性] を選択します。
フォームの右側に新しいドロップダウン リストが表示され、選択したコレクションで使用可能なすべての属性が一覧表示されます。この中から検索に使用する属性を選択します。
テキスト入力フィールドの上にあるドロップダウン リストから、クエリで使用するクエリ演算子 (Contains、Starts、Ends、Matches、Has a substring) や論理演算子 (=、<、>、<=、>=) を選択します。
空白のテキスト フィールドに、検索する属性値を入力します。
[Add Line] をクリックしてクエリに行を追加します。[Undo Line] をクリックして最後に追加した行を削除、または [クリア] をクリックしてクエリ全体をクリアすることもできます。
[検索] ボタンをクリックして検索を実行します。
アクセス許可チェック
条件に一致するドキュメントの一覧表示
結果のソート
ドキュメントの表示
各種コレクションの一部としてではなく、Web Publishing コレクションのみを検索した場合
Web Publishing コレクション以外のコレクションを検索した場合 (そのコレクションのみ、および複合コレクションの一部として検索した場合の両方を含む)
検索結果として表示されているドキュメントの URL をクリックした場合
検索クエリの単語やフレーズが強調表示される形式のドキュメントを表示するリンク (グラフィックなど) をクリックした場合
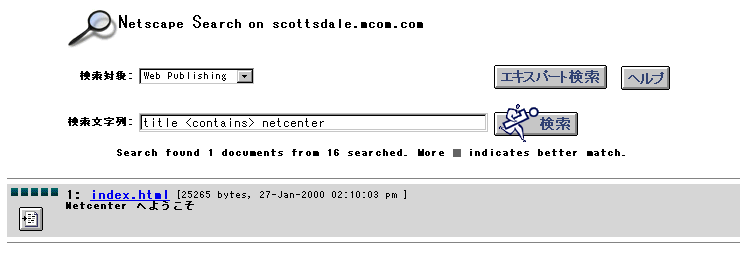
図 6.4 検索結果の例
検索に使用できるデフォルトの属性は、コレクションに含まれるファイル形式の種類によって異なります。各形式に対する属性の詳細については、「
単語間の近接度の比較や、完全に一致する単語をチェックする検索の結果エントリでは、ファイルの一致度を得点で表して順位を付けることが可能です。
結果のソート デフォルト、または高度な HTML クエリ ページの [ソート] フィールドに何も入力しなかった場合は、検索条件に一致するすべてのドキュメントが、一致度の高い順 (これが可能なクエリの場合)、またはサーバ ファイル データベースにおける位置 (一致度を表示できないクエリの場合) に応じて表示されます。
ドキュメントの表示デフォルトで iPlanet Web Serverをインストールした場合は、検索条件に一致するドキュメントの一覧表示から、1 つのドキュメントを選択して Web ブラウザで表示できます。ブラウザでは、ドキュメントを元の形式まま、または色、ボールド、点滅などのテキスト属性を使用して検索クエリの単語やフレーズが強調表示される形式で表示することができます。
ドキュメントを元の形式のまま表示するには、そのドキュメントへの URL を含むハイパーテキスト リンクをクリックします。そのドキュメントが HTML に変換されている場合は、その場所がこの URL で指定されます。このリンクをクリックすることにより、外部ビューアが起動し、ドキュメントが元の形式で表示されます。
コレクションの内容の表示 コレクション データベースでは、データベース内の内容を表示して各コレクションに設定されている属性を確認することができます。ただし、非表示で定義されている一部のコレクションは表示されません。通常、コレクションの内容には、以下の項目が含まれます。
コレクション名、ラベル、説明
コレクションの形式
コレクション内の属性の数および属性名の一覧
コレクション内のドキュメント数
コレクションのサイズとステータス
言語および文字セット
日付の入力形式と出力形式
効果的な検索を行うには、クエリ演算子の使用方法を理解する必要があります。検索では、ブール値検索のみが可能なため、ここではブール値検索規則に基づいて説明します。
ノート クエリ言語では、大文字小文字は区別されませんが、例では、わかりやすくするために大文字を使用します。
検索エンジンは、シンタックスに基づいて検索クエリを解釈します。たとえば、region と入力した場合は、region という単語に加え、語幹が一致する単語 (regions や regional など) も検出されます。検索結果は、「重要度」に応じて、入力した検索条件に一致する順に順位が付けられます。上の例では、region が、最も一致度が高い順位になります。
デフォルト時の解釈
検索規則
使用する演算子の決定
クエリ演算子 (リファレンス)
ワイルドカードの使用
OR - クエリ内の各単語やフレーズがカンマで区切られている場合は、少なくともどちらか一方を含むドキュメントが検出されます。つまり、これは実質上 OR 演算です。たとえば、Monterey, otter は、Monterey または otter のいずれかを含むドキュメントを検出するものとして解釈されます。OR には、山かっこ (<>) は必要ありません。
山かっこ
演算子を組み合わせる
クエリ演算子を検索する単語として使用する
完全に一致する単語のみ検索する
演算子の変更
山かっこ AND、OR、NOT の各演算子、および日付や数値の比較演算子を除くすべてのクエリ演算子は、<CONTAINS>や <WILDCARD>などのように山かっこで囲む必要があります。
演算子を組み合わせる 1 つのクエリで複数の演算子を使用することにより、正確な結果を得ることができます。たとえば、次のクエリを入力した場合は、Bay と Monterey を含み、Aquarium は含まないドキュメントが検出されます。
Monterey Bay Aquarium AND otter AND NOT shark
クエリ演算子を検索する単語として使用する すべてのクエリ演算子は、検索する単語として使用できますが、その場合は、演算子を引用符で囲みます。たとえば、次のクエリでは、潮の満ち引き (ebb and flow) という 1 つのフレーズを含むドキュメントを検索できます。
<CONTAINS> ebb "and" flow
完全に一致する単語のみ検索する 単語を引用符で囲むことにより、語幹一致単語の検索機能をオフにすることができます。たとえば、次のクエリを使用した場合は、完全に一致する単語のみ検索されます。
演算子を変更する AND、OR、NOT の各演算子を使用し、ほかの演算子を変更することもできます。たとえば、theme park というフレーズが含まれるタイトルのあるドキュメントを検索から除外する場合は、次のようなクエリを使用します。
Title NOT <CONTAINS> theme park
使用する演算子の決定 使用する演算子を決定する際には、以下を参照してください。クエリ言語では、大文字小文字は区別されないため、<starts> と <STARTS> は同じものとして扱われます。このドキュメントでは、わかりやすくするために大文字を使用します。
plan、plane、planet をはじめ、planned、plans、planetopolis など、plan で始まる単語を含むドキュメントを検索します。 詳細および例については、次の節を参照してください。
文字列全体は、バッククオーツで囲み、スペースは使用しません。
<WILDCARD>Zine\\*\\*\\*
一部の文字は、検索エンジンで特殊な検索文字として認識されるため、リテラルとして解釈させるにはバッククオーツを使用する必要があります。特別な検索文字は以下のとおりです。
カンマ ,
左右のかっこ ( )
二重引用符 "
バックスラッシュ (円記号) \
アット マーク @
左中かっこ {
左角かっこ [
バッククオーツ ` (ノート: バッククオーツは、サーバ管理者がこれをリテラルとして設定している場合のみ、リテラルと認識されます。)
たとえば、文字列 "a{b" を検索する場合は、次のように入力します。
<WILDCARD>`a{b`
また、バッククオーツを含む文字列 "c`t" を検索する場合は、次のように入力します。