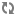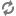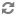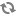The Aggregate Affinity Facts namespace includes query subjects dealing with affinity between products and catalogs.
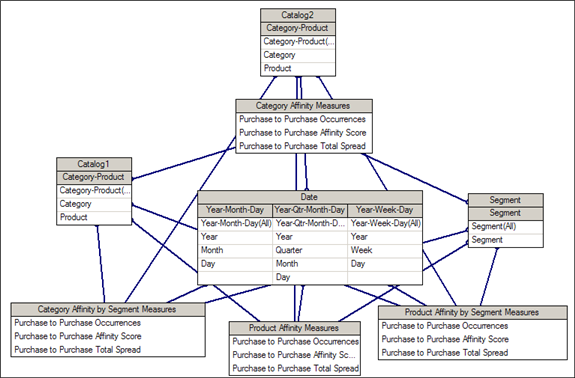
Aggregate Affinity Model View
The Product Affinity query subject provides access to affinity information about product pairs. It includes the affinity score, the number of times the product pair occurs, and the total spread.
Spread is defined as the number of days between purchases for each product in a product pair. For example, if Product 1 is purchased on April 1, and Product 2 is purchased on April 5, the spread is 4. The Purchase to Purchase Total Spread represents the sum of the spreads for all product pairs. Total Spread can be divided by Occurrences to give the average number of days separating products in a product pair.
The Category Affinity query subject provides the same information as Product Affinity, but with regard to categories.

The Product Affinity by Segment query subject allows you to break down product affinity data by the user’s segment.
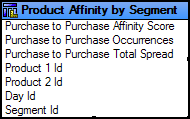
The Category Affinity by Segment query subject allows you to break down category affinity data by the user’s segment.

The Product1, Product2, Category1, and Category2 query subjects provide information about the products and categories involved in the purchases. Products and categories are described in the Catalog Metadata section; two query subjects are needed for each in order to make comparisons. Segment and Date query subjects are described in the Platform Metadata Model chapter.
All Affinities by Product or Category
The Aggregate Affinity Facts namespace includes a folder called All Affinities by Product or Category. This folder contains two additional query subjects, Product Affinity by Product and Category Affinity by Category. These query subjects are designed to make it easier to create reports that provide data in relationship to a fixed product or category.
The intent of affinity selling is to measure relationships between pairs of products or categories. Each pair has a designated Product1 and Product2. In order to eliminate duplicate data in the warehouse, products in the pair lists are ordered by a sort. For example, one pair may consist of Pants and Belts, while another pair consists of Shirts and Pants. Both pairs include Pants, but in one pair, Pants is Product1, and in another is Product2. This means that if you want to see all products paired with Pants, you must remember to include all pairs where Product1=Pants and where Product2=Pants. The resulting report will be difficult to interpret, since Pants could be in either position.
The Product Affinity by Product and Category Affinity by Category query subjects represent unions of the pairing tables. The union selects all rows from the table, then swaps Product 1 and Product 2 and again returns all of the rows. This means that the number of rows in the new query subject is exactly double the original table. It also means if a report requires all Products associated with Pants, the filter is simply on Product 1, and all associated products are in the Product 2 column. In this case, there will not be duplicate data.
For example, the original table might include the following data:
Product 1 | Product 2 | Affinity |
|---|---|---|
Belts | Pants | 2.3 |
Pants | Shirts | 1.7 |
Pants | Toothbrushes | 0.2 |
The union would look like the following table:
Product 1 | Product 2 | Affinity |
|---|---|---|
Belts | Pants | 2.3 |
Pants | Shirts | 1.7 |
Pants | Toothbrushes | 0.2 |
Pants | Belts | 2.3 |
Shirts | Pants | 1.7 |
Toothbrushes | Pants | 0.2 |
In the union query subject, you can see that Pants are associated with Shirts, Toothbrushes and Belts by looking solely at Product 1.
Aggregate Affinity Dimensional View
The Aggregate Affinity dimensional view includes Date, Segment, Catalog1 and Catalog2 dimensions found in the platform metadata model. The Affinity-specific dimensions contain only measures, and do not use hierarchies. The dimensional view is shown in the diagram that follows.