Importing Supplemental Data
Important: This topic is for users of the latest version of Connect . If your account still uses Classic Connect, download the Classic Connect User Guide.
You can use Connect to import records to a Supplemental Data table in Oracle Responsys.
After an import job runs, the upload file is archived on the server. If the job is successful, the upload file is deleted. If the job fails, the upload file is deleted only in the following circumstances:
- The file is empty
- The file has data issues, such as invalid data format
- The upload file and the count file have different number of records.
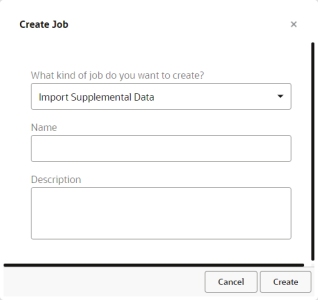
To create an Import Supplemental Data job:
- Click
 Data on the side navigation bar, and select Connect.
Data on the side navigation bar, and select Connect. - Click Create Job on the Manage Connect page.
- Select Import Supplemental Data from the drop-down list and provide a name and description of the import job.
A job name cannot be longer than 100 characters and can include only the following characters: A-Z a-z 0-9 space ! - = @ _ [ ] { }
- Click Done.
The Connect wizard opens. You may complete the steps in any order, and can save your changes and continue at a later time.
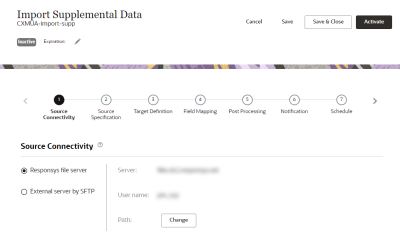
- Complete the steps:
- After you configure all the steps, click Save. To save and activate the job, click Activate.
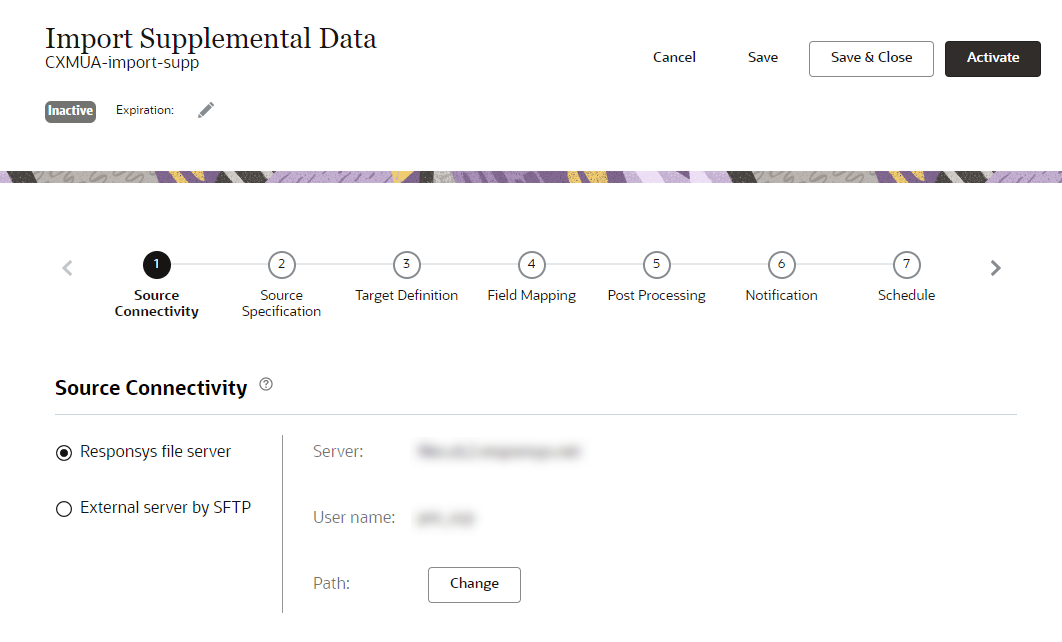
Important: Before you can save or activate the job, you must either set an expiration date, or set the job to never expire. To set an expiration date, click Edit next to Expiration. When the job expires, it is deleted and cannot be recovered. Learn more about managing the expiration date.
next to Expiration. When the job expires, it is deleted and cannot be recovered. Learn more about managing the expiration date.
After you finish:
- After you save your job, you can use the Manage Connect page to manage the job. Learn more about managing jobs.
- When you save your job, Connect may return errors. Click Show Errors to review the errors and quickly jump to the page that needs fixing. You must resolve all errors before you can activate the job.
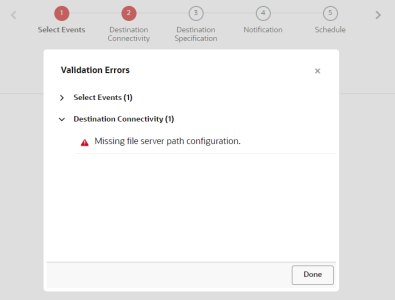
Step 1: Source Connectivity
In this step, you provide file server specifications for retrieving your source file.

Select one of the following options:
- Responsys File Server:
Connect jobs can import data via your Responsys SCP (Secure Copy Protocol) account file server.
This account includes three directories: upload, download, and archive.
Important: If not already established, Oracle Responsys Support and your IT team will need to work together to generate an SSH-2 public/private key pair. This ensures secure access to your SCP account via an SSH/SCP client. You may also create your own directories using an SSH (Secure Shell) client.
- If you select this option, click Change to specify the directory where your files are located.
- External server by SFTP:
If you select this option, provide the following information:
- Hostname: Select the hostname from the drop-down list.
- Directory Path: Enter the pathname of the associated directory.
- Username: Enter the username for accessing your SFTP connection.
- Authentication: Depending on the way your server is set up, select either Password or Key.
If this is your first job using key authorization, click Access or Generate Key Information, and enter the email address to receive the public key and instructions for adding the key to your SFTP account. After installing the public key, click Test Connection to confirm that your SFTP connection configuration is valid.
Tip: For information about key authentication, see Selecting, Importing or Generating Public Keys.
Step 2: Source Specification
In this step, you provide information about the file to be imported.
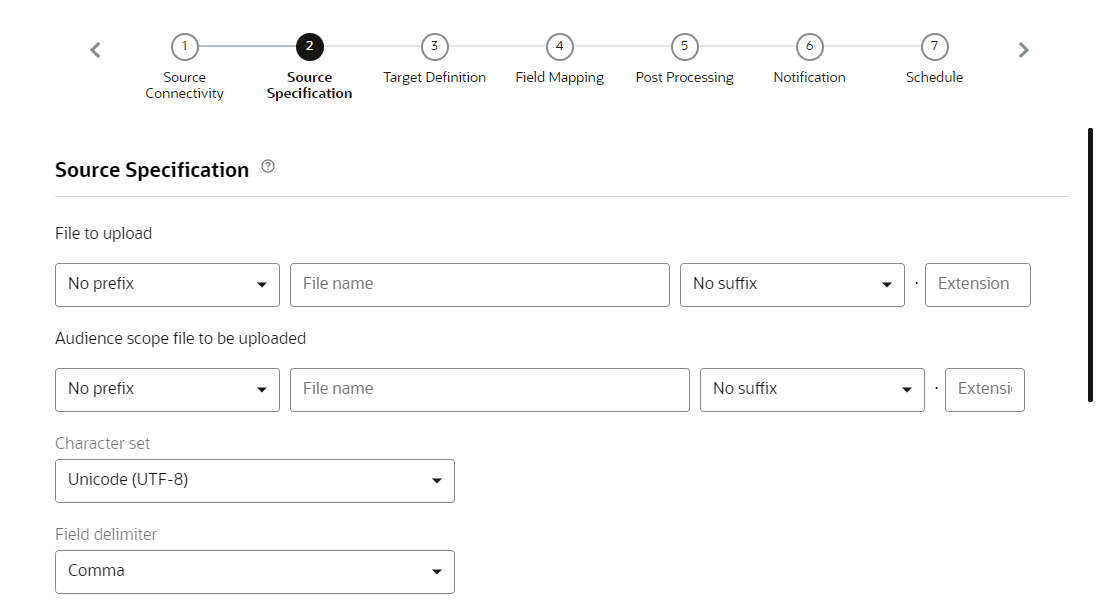
- File to upload: The full name and file extension of the file to import. You can add the file creation date as a prefix or suffix.
- Audience scope file to be uploaded: This option is available when importing profile data and only if Organizational Access Control and Targeting by Organization are enabled for your account. Learn more about the required file format.
- Character set: The character set of the file. If your file contains emojis, you will need to select Unicode (UTF-8) as your character set.
- Field delimiter: The delimiter that divides the fields (columns) in the file.
- Field enclosure: Specify whether text columns and values are enclosed in single or double quotation marks.
- Date format: Select the date format of the import file. For information about supported date formats, see Supported Date Formats in Connect.
- First line contains column names: Select this checkbox if the first line in the file contains field names.
- File is encrypted with PGP/GPG key: Select this checkbox if the file is encrypted using a key and needs to be decrypted before uploading.
- File is signed with PGP/GPG key: Select this checkbox if the file is signed with a key.
- File to confirm expected record count: Optionally, select this checkbox and specify a file to use for comparing the record count to the number of imported records. For example, if the expected record count in this file is 300, but your imported file only contains 100 records, a transfer error is noted and the upload process is abandoned
Step 3: Target Definition
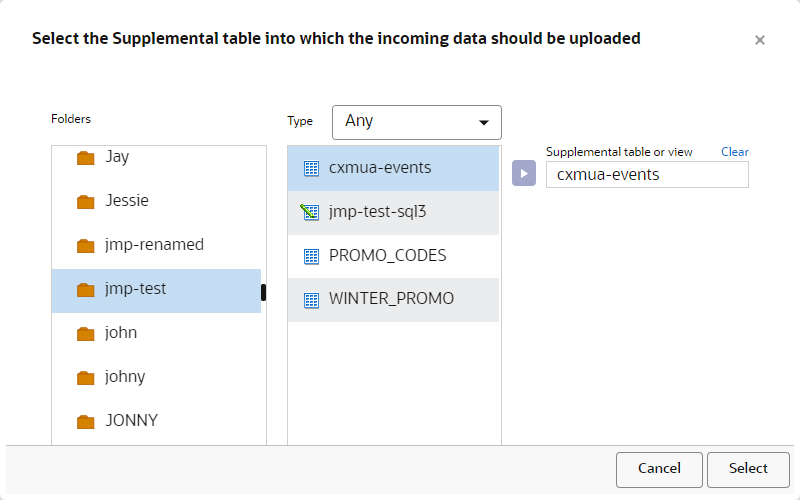
In this step, you select the Supplemental Data table that you want to import data to.
Note: You'll also need to select target tables while mapping fields in Step 4.

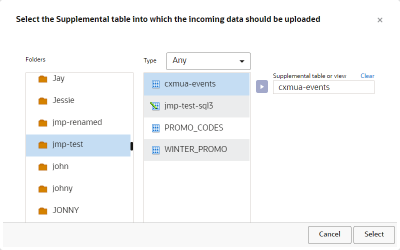
To add a target definition:
- On the Target Definition step, click Add + and select the Supplemental Data table into which to import data.
- In the Configuration section, specify the following options:
- Insert as new records in target table: If your supplemental table does not have a primary key, you can select this checkbox to append records to the supplemental table as new records.
Note: This option only displays if your account allows you to create supplemental tables without primary keys. If you're interested in creating supplemental table without primary keys, please log in to My Oracle Support and create a service request.
- Remove all existing records and upload: Select this checkbox to replace the existing records with the newly uploaded records.
- Merge into table using following field: If you are not removing all existing records, select the field for merging new records into existing records.
- If there is a match, overwrite all mapped fields in existing records: Select this checkbox to replace existing records with new data when a record matches. If you do not select this checkbox, the incoming record is ignored.
- If there is not a match, import new record: Select this checkbox to import records if there is no match. If you do not select this checkbox, the incoming record is ignored.
- Insert as new records in target table: If your supplemental table does not have a primary key, you can select this checkbox to append records to the supplemental table as new records.
Step 4: Field Mapping
In this step, you map columns from the source file to fields in the target table. Mapping fields specifies which source field corresponds to which target field.
You can manually map the fields, use an upload file for the mapping, or automatically generate the field mapping.
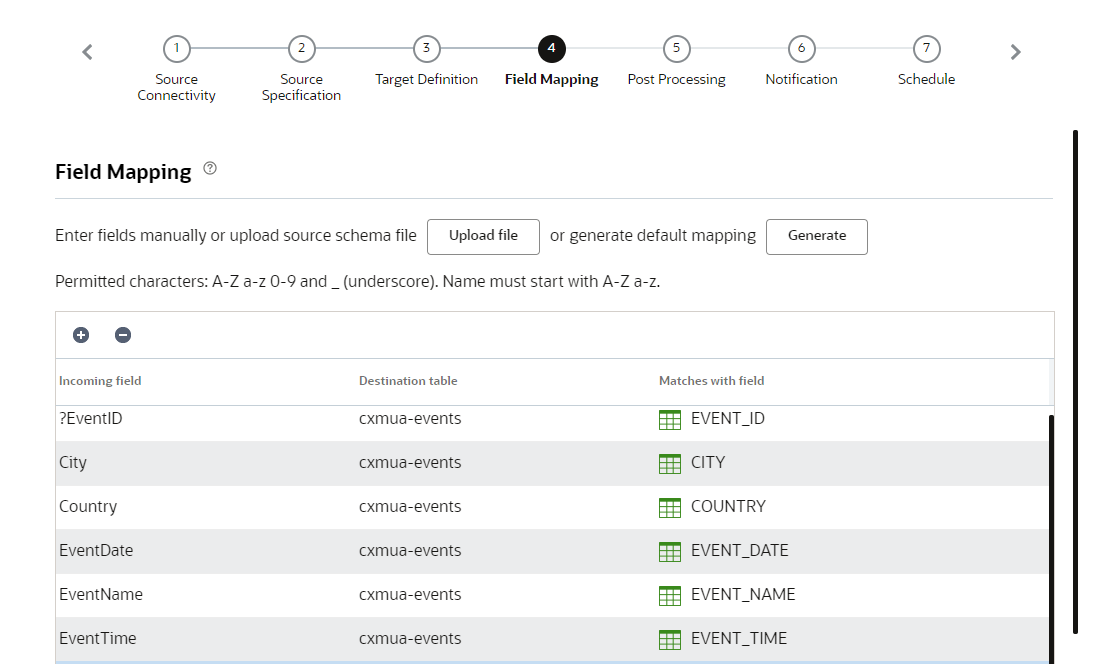
Note the following:
- Long field names are truncated to 30 characters.
- Field names must begin with a letter or number and may contain only letters, digits, and _ (underscore).
- When created, field names are not case-sensitive, but are later translated to all uppercase.
- If any changes result in duplicate field names, you will need to manually rename them.
- All system field names (defined and reserved by Oracle Responsys) end with an underscore character, for example EMAIL_ADDRESS_. As a best practice, uploaded field names should not end with an underscore character since these are reserved for system fields.
- When possible, match like-named incoming fields with existing fields, for example, match CUST_ID to CUSTOMER_ID_.
For more details about data type and field name requirements, see Data Types and Field Names.
To upload a mapping file:
- On the Field Mapping step, click Upload File.
- Select the mapping file and complete the details.
- Fields are delimited by: Select the delimiter (typically a tab or comma) that divides the columns in the file.
- Fields are enclosed by: Specify whether text columns and values are enclosed in single or double quotation marks.
- First line contains column names: Select this checkbox if the first line contains field names.
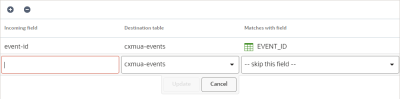
To map fields manually:
- On the Field Mapping step, click Add +.
- Type the name of the incoming field in the space provided.
- Select the target destination for that field.
- Select the matching field name in the target.
If you do not want to match a field, select skip this field.
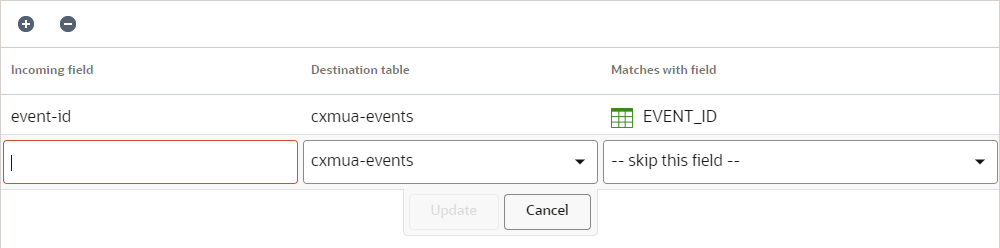
- Click Update.
Step 5: Post Processing
In this step, you can launch campaigns after a successful job run. You may select up to 40 campaigns.
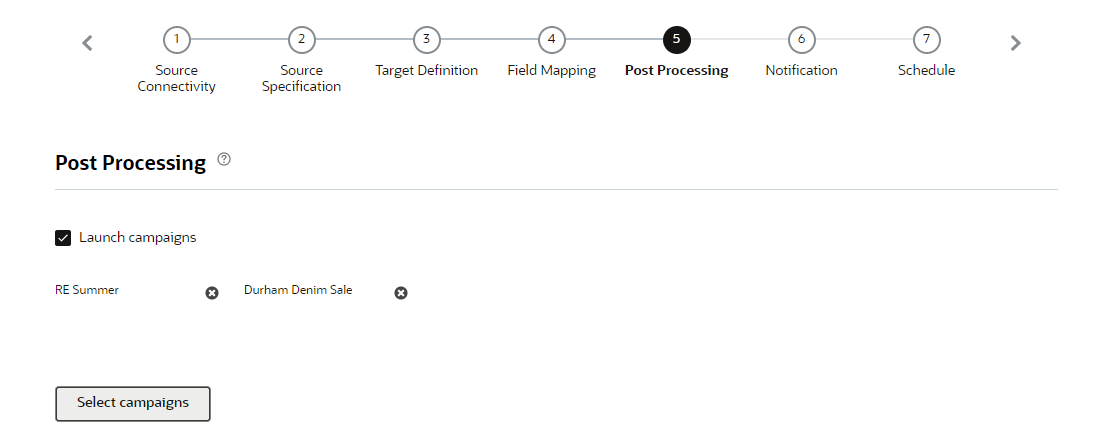
To receive progress notifications about campaigns launches, ensure that each campaign's settings specify one or more email addresses to receive progress notifications.
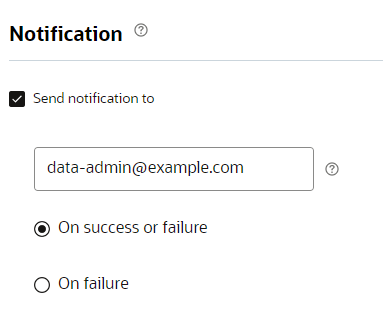
Step 6: Notification
In this step, you set up email notifications for the job. You can choose to send notifications after the success or failure of a job.
Step 7: Schedule
In this step, you schedule the job. The job can run once on a specified date and time, or on a recurring schedule. To run the job on demand, use the Do not schedule option.
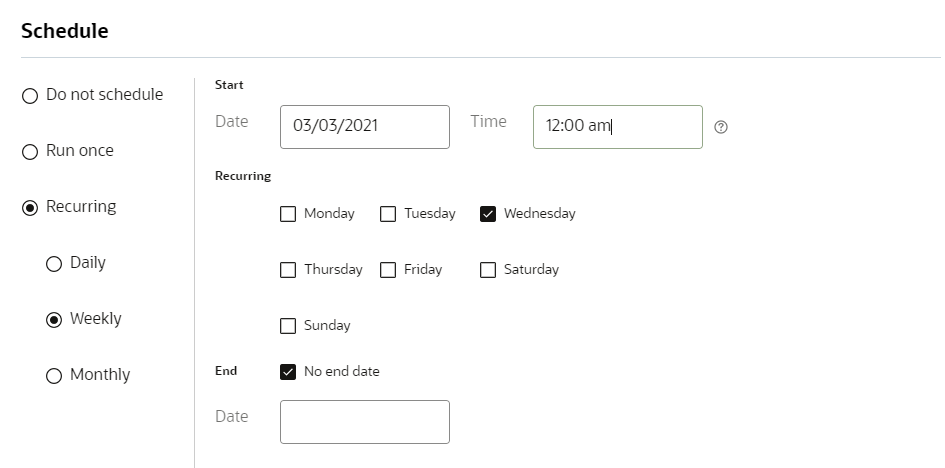
IMPORTANT: To ensure that leap years and months with 31 days do not cause issues, you cannot schedule a recurring monthly run on the 29th, 30th or 31st day of a month. You can schedule the job to run on a day of the week that is the last in the month, for example the last Friday of the month.
When setting the start time of a job, select one of four time slots within the hour: 0-14, 15-29, 30-44, 45-59. For each scheduled job, the system picks a random minute (for example, 12 within the 0-14 segment). This distributes the start times of jobs more evenly.
The job will start at random times within the chosen time slot. If you try to set up a new job in a slot that overlaps with the current time, an error message may be issued that states that the time selected occurs in the past. Therefore, as best practice, choose the time slot that is after the current time slot.