10gリリース5(10.2.0.5.0)
B53907-01
 目次 |
 索引 |
| Oracle Enterprise Manager アドバンスト構成 10gリリース5(10.2.0.5.0) B53907-01 |
|


Oracle Enterprise Manager 10g Grid Controlが基づくアーキテクチャは柔軟性に富んでおり、最も効率的かつ実用的な方法でGrid Controlコンポーネントをデプロイできます。この章では、様々なコンピューティング環境でGrid Controlアーキテクチャをどのようにデプロイできるかを示す一般的な構成をいくつか示します。
一般的な構成を論理的に進めていきます。最初に最も簡単な構成を示し、最後にロード・バランサ、Oracle Real Application ClustersおよびOracle Data Guardなどの高可用性コンポーネントのデプロイを含む複雑な構成を示します。
この章では次の項について説明します。
この章で説明する一般的な構成は単なる例です。使用環境にデプロイする実際のGrid Controlの構成は、それぞれのニーズに応じて異なります。
たとえば、この章の例は、OracleAS Web Cacheポートを使用してGrid Controlコンソールにアクセスすることを前提としています。デフォルトでは、Grid Controlを最初にインストールした場合、デフォルトのOracleAS Web CacheポートにナビゲートするとGrid Controlコンソールが表示されます。実際には、管理者がOracleAS Web Cacheを迂回し、Oracle HTTP Serverに直接接続するポートを使用するように構成を変更できます。
別の例として、本番環境でファイアウォールを実装し、その他のセキュリティ関連事項について考慮する場合があります。この章で説明する一般的な構成は、使用環境でのファイアウォールの実装およびセキュリティ・ポリシーの実行方法を示すわけではありません。
|
関連項目
Grid Controlコンポーネント間の接続のセキュリティの詳細は Grid Controlコンポーネント間のファイアウォール構成の詳細は第6章「Enterprise Managerのファイアウォールの構成」 |
この章は、一般的な構成について説明しているだけではなく、アーキテクチャ、およびGrid Controlコンポーネント間のデータのフローを理解する際にも役立ちます。この知識を基に、ユーザー独自の管理要件に合ったGrid Controlの構成方法を適切に決定できます。
Grid Controlアーキテクチャは、次のソフトウェア・コンポーネントで構成されています。
この章の残りの項では、これらのコンポーネントを様々な組合せで、単一ホストまたは複数のホストにデプロイする方法について説明します。
図3-1は、Grid Controlを単一ホストにインストールする際に、各Grid Controlコンポーネントが相互作用するように構成する方法を示します。これは、Grid Controlのインストール手順を使用して、「新規データベースを使用したEnterprise Manager 10g Grid Control」インストール・タイプをインストールするときのデフォルトの構成です。
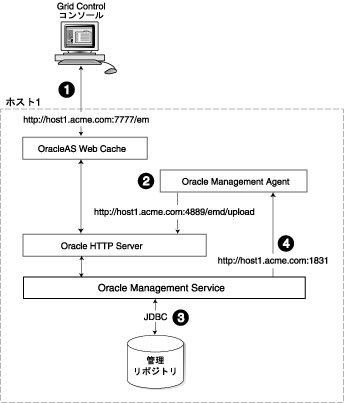
すべてのGrid Controlコンポーネントを単一ホストにインストールした場合、管理データは次のフローで移動します。
REPOSITORY_URLプロパティで定義されます。
AGENT_HOME/sysman/config/emd.properties (UNIX) AGENT_HOME¥sysman¥config¥emd.properties (Windows)
ORACLE_HOME/sysman/config/emoms.properties (UNIX) ORACLE_HOME¥sysman¥config¥emoms.properties (Windows)
管理サービスは、管理エージェントのURLを使用して管理エージェントの可用性を監視し、Enterprise Managerジョブおよびその他の管理機能を発行します。
管理エージェントのURLは、管理エージェント・ホーム・ディレクトリにある次の構成ファイルのEMD_URLプロパティで指定されます。
AGENT_HOME/sysman/config/emd.properties (UNIX) AGENT_HOME¥sysman¥config¥emd.properties (Windows)
次に例を示します。
EMD_URL=http://host1.acme.com:1831/emd/main/
また、Grid Controlコンソールに表示される管理エージェントの名前は、管理エージェントのURLで使用される管理エージェントのホスト名とポートで構成されます。
単一ホストへのすべてのGrid Controlコンポーネントのインストールは、使用するOracle環境を集中管理する場合、最初に使用可能な機能を検討するには効率的な方法です。
単一ホスト環境から、管理リポジトリのデータベースが別のホストにあり、管理サービスとリソースが競合しない、より分散型のアプローチへと論理的に発展します。このような構成の利点はスケーラビリティにあります。管理リポジトリと管理サービスのワークロードを分割できるようになります。また、システムの負荷に応じて各層へのリソースの割当てを調整できる柔軟性が得られます。(そのような構成を図3-2に示します。)詳細は、3.4.2.1項「管理サービスに対する負荷の監視」を参照してください。
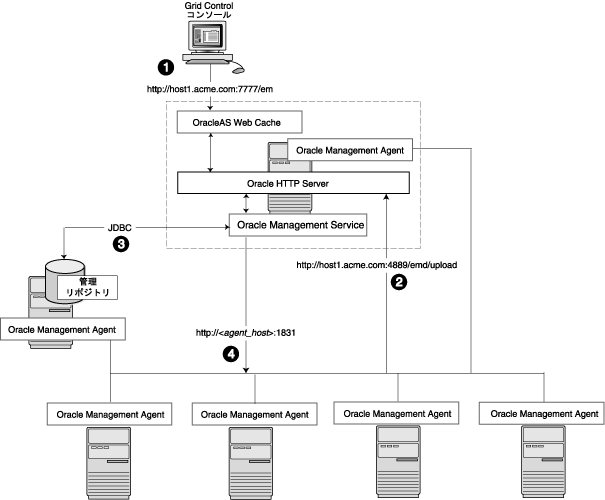
より分散したこの構成では、管理対象ターゲットのデータは、Grid Controlコンソールを介して管理者が収集、格納および利用できるように次のフローで移動します。
emd.propertiesファイルで定義されている管理サービスのアップロードURLを介して、データを管理サービスにアップロードします。アップロードURLは、OracleAS Web Cacheを迂回し、Oracle HTTP Serverを介してデータを直接アップロードします。
emoms.properties構成ファイルで定義されます。
emd.propertiesファイルのEMD_URLプロパティで定義されます。3.2項で説明したように、管理エージェントには組込みHTTPリスナーが含まれているので、管理エージェントのホストにOracle HTTP Serverは必要ありません。
より大規模な本番環境では、管理サービスの負荷を軽減し、データ・フローをより効率的にするために、追加の管理サービスが必要です。
次の項でこの構成について、より詳しく説明します。
図3-3は、Grid Control環境のスケーラビリティを向上させるために管理サービスが追加された標準的な環境を示しています。
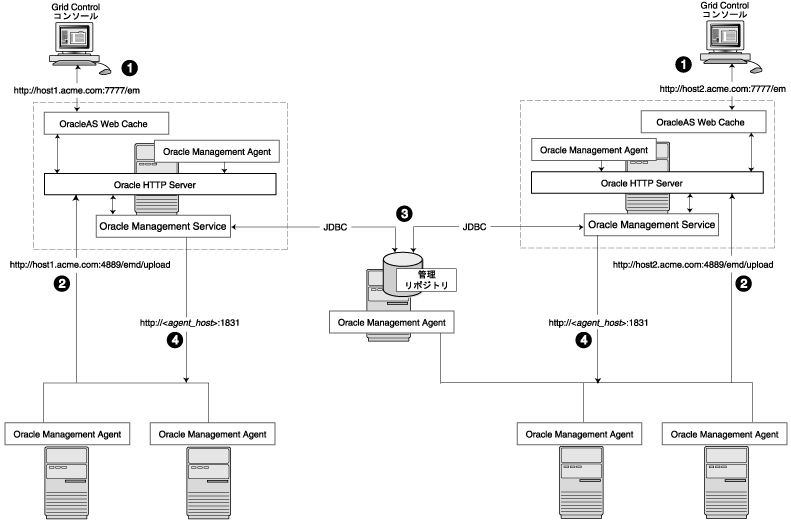
複数の管理サービス構成では、管理データは次のフローで移動します。
emd.propertiesファイル内のアップロードURLに基づいて、特定の管理サービスにそのデータをアップロードします。データはOracleAS Web Cacheを迂回し、Oracle HTTP Serverを介して管理サービスに直接アップロードされます。複数の管理サービスをインストールする場合は、常に、管理サービスが共有ディレクトリにアップロードすることがベスト・プラクティスです。これにより、1つの管理エージェントからダウンロードされた管理ファイルをすべての管理サービスが処理できるようになります。これで、管理エージェントからのアップロード・データの破損が原因でいずれかの管理サーバーが失われるのを防止できます。
この機能は、管理サービスの各プロセスのコマンドラインから、次のように構成します。
emctl config oms loader -shared <yes|no> -dir <load directory>
|
重要 ロード・バランサを追加することで、次の問題を回避できます。
ロード・バランサの詳細は、3.5項「高可用性構成 - 最大可用性アーキテクチャ」を参照してください。 |
emoms.propertiesファイルで定義された同じデータベース接続情報を使用し、その管理エージェントから管理リポジトリにデータをロードします。管理サービスは同じ接続情報を使用して、Grid Controlコンソールによって要求されたデータを管理リポジトリから取得します。
3.2項で説明したように、管理エージェントのURLは、各管理エージェント・ホーム・ディレクトリにあるemd.propertiesファイルのEMD_URLプロパティで定義されます。各管理エージェントには組込みHTTPリスナーが含まれているので、管理エージェント・ホストにOracle HTTP Serverは必要ありません。
管理サービスは、管理エージェントからのアップロード情報の受信者としてのみ存在するわけではありません。管理リポジトリからデータの取得も行います。管理サービスは、クライアントのWebブラウザでリクエストされ、そのブラウザでの表示に使用されるHTMLページの形式にこのデータをレンダリングします。また、管理サービスは、Enterprise Managerジョブの通知配信およびディスパッチなどのバックグラウンド・プロセス・タスクを実行します。
そのため、管理サービスへの管理エージェントの割当ては注意して管理する必要があります。管理エージェントから管理サービスへの不適切な負荷分散は、次のような結果を招く場合があります。
次の項では、管理サービスの負荷およびレスポンス時間の監視についてのヒントをいくつか示します。
使用環境がSLBで構成されていない場合、ワークロードを均等に分散させるには、管理サービスごとに構成されている管理エージェントの数を常に把握して、それぞれの管理サービスに対する負荷を監視する必要があります。
Grid Controlコンソールの「設定」で、管理エージェントおよび管理サービスのリストをいつでも表示できます。
「管理サービスとリポジトリ」の「概要」ページのチャートを使用して、次の項目を監視します。
ローダーは管理サービスの一部で、メトリック・データを定期的に管理リポジトリに追加します。ローダー・バックログ・チャートで、バックログが多くローダー出力が少ないことが示されている場合、ロードが保留中のデータがあります。これはシステムのボトルネックを示すか、別の管理サービスが必要なことを示します。チャートは、直前24時間のすべてのOracle Management Serviceについて集められたファイルの合計バックログを示します。画像をクリックすると、直前24時間の個々の管理サービスのローダー・バックログ・チャートが表示されます。
通知配信バックログ・チャートは、割り当てられた時間内に処理できなかった通知の配信数を表示します。通知は管理サービスによって配信されます。この数はすべての管理サービスについて合計され、10分ごとにサンプリングされます。グラフは直前24時間のデータを表示します。通知のバックログの増加を判別するのに役立ちます。このグラフが直前24時間に絶え間なく増加していることを示す場合、別の管理サービスの追加、通知ルール数の削減、およびすべてのルールと通知メソッドが有用で有効であるかどうかの検証を検討してください。
「管理サービスとリポジトリ」ページの情報は、管理サービスに対する負荷の判断に役立ちます。さらに重要なのは、管理サービスのパフォーマンスがGrid Controlコンソールのパフォーマンスにどのように影響するかを検討することです。
EM WebサイトのWebアプリケーション・ターゲットを使用して、Grid Controlコンソールのページのレスポンス時間を確認します。
すべてのページのレスポンス時間が長時間にわたって増加している場合、またはGrid Controlコンソール内の特定のよく使用されるページについてレスポンス時間が異常に長い場合、管理サービスの追加を検討してください。
|
注意: 使用するWebアプリケーションを監視するには、Application Performance ManagementおよびWebアプリケーション・ターゲットを使用できます。詳細は、第7章「サービスの構成」を参照してください。 |
可用性の高いシステムは、ほとんどすべてのビジネスの成功に欠かせないものです。それと同時に、これらのミッションクリティカルなシステムを監視する管理インフラストラクチャの可用性が高いことも重要です。Enterprise Manager Grid Controlのアーキテクチャでは、スケーラビリティと可用性の確保が徹底的に図られています。Grid Controlは、ビジネスを支える資産の管理に集中できることを目的とするとともに、ビジネスの品質保証契約を満たすように対処します。
高可用性のGrid Controlを構成する目的は、ホストや管理サービスの障害など、パフォーマンスまたは可用性の問題が発生した場合にシステムの各コンポーネントと管理データのフローを保護することにあります。
最大可用性アーキテクチャ(MAA)は、Enterprise Managerの各コンポーネントで障害を防ぐことにより、可用性の高いEnterprise Managerの実装を可能にします。
様々なEnterprise Managerコンポーネントの障害で次のような影響が生じます。
Enterprise Managerコンソールは引き続き使用可能であり、管理リポジトリの履歴データも表示できますが、Enterprise Managerによるターゲットの監視が停止されます。
Enterprise Managerコンソールが使用できなくなり、Enterprise Managerのほとんどすべてのサービスが利用できなくなります。
管理エージェントによってアップロードされたデータの保存に関してEnterprise Manager側で障害が発生し、Enterprise Managerのほとんどすべてのサービスが利用できなくなります。
全体的に見て、どのEnterprise Managerコンポーネントで障害が発生しても重大なサービスの中断をもたらす可能性があります。したがって、可用性の高いアーキテクチャを使用して各コンポーネントを強化することが非常に重要となります。
単一インスタンス・データベースを管理リポジトリとして使用して、アクティブ-アクティブ・モードまたはアクティブ-パッシブ・モードで実行するようにEnterprise Managerを構成できます。次の説明はアクティブ-アクティブ・モードの要約です。
高可用性ハードウェアおよびソフトウェアのソリューションを利用する一般的なGrid Control構成の詳細は、次の各項を参照してください。これらの構成は、最大可用性アーキテクチャ(MAA)の一部です。
Enterprise Managerをインストールする前に、管理リポジトリの設定に使用するデータベースを準備する必要があります。Oracleインストールのベスト・プラクティスをすべて継承できるように、Database Configuration Assistant(DBCA)を使用してデータベースをインストールします。
データベース・ホームの$ORACLE_HOME/rbdms/adminディレクトリに移動し、dbmspool.sqlを実行します。
これにより、管理リポジトリのスループット向上に役立つDBMS_SHARED_POOLパッケージがインストールされます。
Oracle Universal Installer(OUI)を使用したEnterprise Managerのインストール時に、管理リポジトリの構成で次の2つのオプションが表示されます。
MAAでは、オプション2の既存のデータベースを使用したインストールを選択する必要があります。既存のデータベースを指定するように要求されたら、管理リポジトリを設定するために前の手順で構成したデータベースを指定します。
管理リポジトリ・データベースのインストール時に構成するパラメータもあれば(前述のとおり)、管理サービスのインストール後に設定するパラメータもあります。Enterprise Managerコンソールが利用可能になると、このコンソールを使用してこれらのベスト・プラクティスを管理リポジトリで構成できます。ベスト・プラクティスは次の領域に分類されます。
これらの設定の詳細は、『Oracle Database高可用性ベスト・プラクティス』を参照してください。
管理リポジトリ構成後の次の手順では、Enterprise Manager Grid Controlの中間層である管理サービスをインストールして高可用性を実現します。中間層の冗長性とスケーラビリティを追加する手順について説明する前に、Oracle Process Management and Notification Service(OPMN)に基づく再起動メカニズムが管理サービス自体に組み込まれている点に留意してください。これにより、停止した管理サービスの再起動が試行されます。
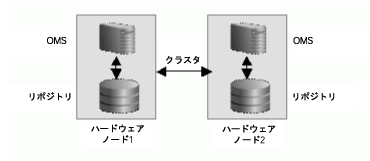
複数の管理サービス・ノードおよび管理リポジトリ・ノードで構成される大規模な環境を管理する場合は、管理リポジトリ・ノードとは異なるハードウェア・ノードに管理サービスをインストールすることを検討します(図3-4を参照)。これにより、将来的に管理サービスを拡張できます。
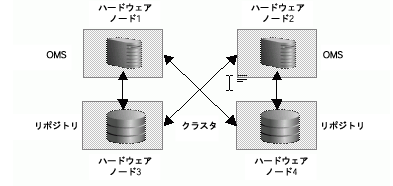
管理サービスのインストール場所の決定では、管理サービスと管理リポジトリの間のネットワーク待機時間についても考慮します。管理サービスと管理リポジトリの間の距離はネットワーク待機時間に影響する要因の1つとなる場合があり、Enterprise Managerのパフォーマンスを左右します。
管理サービス層と管理リポジトリ層の間のネットワーク待機時間が長い場合や、Enterprise Managerの実行に使用できるハードウェアが限定されている場合は、管理サービスを管理リポジトリと同じハードウェアにインストールできます(図3-5を参照)。その場合は、Enterprise Managerの高可用性を実現しつつ、コストの削減を図ることができます。
管理サービス・プロセスをすべてインストールしたら、冗長性のある方法でRAC管理リポジトリの各ノードと通信するように管理サービス・プロセスを構成する必要があります。そのためには、インストールした管理サービスごとに
$ORACLE_HOME/sysman/config/emoms.properitiesファイルのemdRepConnectDescriptorフィールドを変更します。この構成の目的は、データベース・サービスEMREPを介して管理リポジトリにアクセス可能な、データベース・クラスタ内のすべてのインスタンスを管理サービスに認識させることです。
Real Application Clusters(RAC)ノードは、その仮想IP名(vip)によって参照されます。システム識別子(SID)のかわりにservice_nameパラメータがconnect_dataモードで使用され、フェイルオーバーが有効になります。詳細は、『Oracle Database Net Services管理者ガイド』を参照してください。
oracle.sysman.eml.mntr.emdRepConnectDescriptor=(DESCRIPTION\= (ADDRESS_LIST\=(FAILOVER\=ON) (ADDRESS\=(PROTOCOL\=TCP)(HOST\=node1-vip.example.com) (PORT\=1521))(ADDRESS\=(PROTOCOL\=TCP)(HOST\=node2-vip.example.com) (PORT\=1521)) (CONNECT_DATA\=(SERVICE_NAME\=EMREP)))
この変更が完了したら、コマンドemctl config emrep -conn_desc "<tns alias>"を実行して、「管理サービスとリポジトリ」のターゲットで使用される監視構成に同じ変更を加えます。
最後に、サーバー・ロード・バランサの機能を利用できるように管理サービスを変更します。この変更により、すべての管理サービス・ノードでは、Enterprise Managerコンソールのトラフィックがサーバー・ロード・バランサを介してリダイレクトされます。その結果、Enterprise Managerユーザーには1つのURLのみが示されます。
URLのリダイレクト時にブラウザがロード・バランサを迂回しないように、Grid Controlは、管理サービスを再度保護する一環としてssl.confファイルを再構成します。ロード・バランサの構成後に、管理サーバーのホームからコマンドemctl secure omsを発行します。
$ORACLE_HOME/Apache/Apache/conf/ssl.confにあるOracle HTTP Server構成ファイルのPortの値を443に変更します。この処理は、管理サービスと管理エージェントの間でデフォルトのセキュアな構成を実行していることを前提としています。
Oracle Universal Installer(OUI)の「その他の管理サービスの追加」オプションを使用して、1つ以上の追加の管理サービスをインストールします。高可用性のためには最低でも2つの管理サービスが必要ですが、追加の管理サービス・プロセスは、見込まれるワークロードやシステム使用状況データに基づいてインストールできます。サイジングの推奨事項については、
第11章「Oracle Enterprise Managerのパフォーマンスのサイジングおよび最大化」を参照してください。
最初の管理サービスでは高可用性の設定が完了しているので、その構成を追加の管理サービスに新しいemctlコマンドで簡単にコピーできます。追加の管理サービスをインストールする前に、次の考慮事項に留意してください。
emctl config emkey -copy_to_reposを使用して最初の管理サービスの管理リポジトリにemkeyを一時的にコピーする必要があります。
『Oracle Enterprise Manager Grid Controlインストレーションおよび基本構成』に記載されている手順に従って、管理サービス・ソフトウェアをインストールします。ソフトウェアのみをインストールして構成は後で行う(追加の管理サービス)オプションに関する項を参照してください。最初の管理サービスと一致するようにソフトウェアを最新のパッチ・セットに更新します。最初の管理サービスから構成をコピーするemctlコマンドでは、ソフトウェア・バイナリはコピーされません。追加の管理サービスをインストールしたら、次の手順を実行して最初の管理サービスから構成をコピーします。
emctl exportconfig oms -dir <location for the export file>を使用して、最初の管理サービスから構成をエクスポートします。
emctl importconfig oms -file <full path of the export file>を使用して、エクスポートした構成を追加の管理サービスにインポートします。
emcli setup -url=https://slb.example.com/em -username sysman -password <sysman password> -nocertvalidateを使用して、EMCLIを設定します。
emctl secure agent -emdWalletSrcUrl https://slb.example.com:<upload port>/emを使用して再度保護します。
Grid Control 10gリリース2の管理サービスには、共有ファイルシステム・ローダーという高可用性機能が備わっています。共有ファイルシステム・ローダーでは、管理エージェントから受信した管理データ・ファイルが、共有受信ディレクトリという共通の共有場所に一時的に格納されます。すべての管理サービスは、共有受信ディレクトリの同じ記憶域を使用するように構成されます。管理サービスは内部的な調整を行い、管理リポジトリへのファイルのアップロードのワークロードを複数の管理サービス間で分散します。管理サービスが停止した場合は、動作している管理サービスがそのワークロードを引き継ぎます。
共有ファイルシステム・ローダーを使用するように管理サービスを構成するには、次の手順を実行する必要があります。
ソフトウェア・ライブラリの場所はすべての管理サービスからアクセスできる必要があるため、共有ファイルシステム・ローダーのディレクトリと同様の考慮事項がここでも適用されます。詳細は、第15章「ソフトウェア・ライブラリの使用方法」を参照してください。
この項では、管理エージェントから複数の管理サービスへのデータのアップロードのバランスをとるためのロード・バランサの構成に使用できるガイドラインを示します。
次の例は、2つの管理サービス・プロセスのホストAとホストBへのインストールが完了していることを前提としています。インストールを容易にするには、アプリケーション・サーバー・プロセスがインストールされていない2つのホストで作業を開始します。これにより、次の表に示すように、デフォルトのポートが確実に使用されます。例では、説明のためにこのデフォルト値を使用します。
デフォルトでは、管理サービス側の証明書のサービス名は、管理サービス・ホストの名前を使用します。管理エージェントがロード・バランサを介して管理サービスと通信している場合、管理エージェントは、この証明書を受け付けません。次のコマンドを実行して、両方の管理サービスで証明書を再生成する必要があります。
emctl secure -oms -sysman_pwd <sysman_pwd> -reg_pwd
<agent_reg_password> -host slb.acme.com -secure_port 1159
-slb_console_port 443
特に、ロード・バランサにパッケージされた管理ツールを使用して、各ホストが提供するホストとサービスで構成される仮想プールを構成する必要があります。高可用性の管理サービスを保証するには、仮想プール内で定義された2つ以上の管理サービスが必要です。構成例を次に示します。
この例では、プールと仮想サーバーの両方が作成されます。
プールabc_upload: 管理エージェントから管理サービスへの管理データのセキュアなアップロードに使用されます。
メンバー: hostA:1159、hostB:1159
永続性: なし
ロード・バランシング: ラウンド・ロビン
プールabc_genWallet: 新しい管理エージェントの保護に使用されます。
メンバー: hostA:4889、host B:4889
永続性: アクティブなHTTP Cookie、メソッド→挿入、制限時間60分間
ロード・バランシング: ラウンド・ロビン
プールabc_uiAccess: セキュアなコンソール・アクセスに使用されます。
メンバー: hostA:4444、hostB:4444
永続性: 単純(クライアントIPベースの永続性)、タイムアウト→3000秒(OC4Jセッション・タイムアウトの45分より長い必要があります。)
ロード・バランシング: ラウンド・ロビン
セキュアなアップロードのための仮想サーバー
アドレス: slb.acme.com
サービス: 1159
プール: abc_upload
管理エージェント登録のための仮想サーバー
アドレス: slb.acme.com
サービス: 4889
プール: abc_genWallet
UIアクセスのための仮想サーバー
アドレス: sslb.acme.com
サービス: https(443)
プール: abc_uiAccess
管理エージェントのホーム・ディレクトリのsysman/configディレクトリにあるemd.propertiesファイルのREPOSITORY_URLプロパティを変更します。ホスト名およびポートは、ロード・バランサの仮想サービスのものを指定する必要があります。
この構成により、管理エージェントからの接続を均等に管理サービス間で分散できます。管理サービスが使用できなくなった場合、ロード・バランサが使用可能な管理サービスに接続をダイレクトするように構成する必要があります。
この構成を正常に実装するため、基礎となる管理サービスを監視するようにロード・バランサを構成できます。たとえば、いくつかのモデルでは、ロード・バランサに監視を構成できます。監視によって次のものが定義されます。
たとえば、管理サービスの状態が5秒ごとに確認されるようにロード・バランサを構成できます。障害が3回連続して発生した場合、ロード・バランサはコンポーネントを使用不可としてマークし、そのコンポーネントにはリクエストをルーティングしません。監視は、文字列GET /em/uploadをHTTPを使用して送信し、応答Http XML File receiverを受信するように構成する必要があります。次の監視構成例を参照してください。
この例では、mon_upload、mon_genWalletおよびmon_uiAccessの3つの監視が構成されます。
監視mon_upload
タイプ: https
間隔: 60
タイムアウト: 181
送信文字列: GET /em/upload HTTP/1.0\n
受信ルール: Http Receiver Servlet active!
関連付け先: hostA:1159、hostB:1159
監視mon_genWallet
タイプ: http
間隔: 60
タイムアウト: 181
送信文字列: GET /em/genwallet HTTP/1.0\n
受信ルール: GenWallet Servlet activated
関連付け先: hostA:4889、hostB:4889
監視mon_uiAccess
タイプ: https
間隔: 5
タイムアウト: 16
送信文字列: GET /em/console/home HTTP/1.0\nUser-Agent: Mozilla/4.0
(compatible; MSIE 6.0; Windows NT 5.0)\n
受信ルール: /em/console/logon/logon;jsessionid=
関連付け先: hostA:4444、hostB:4444
管理サービスは、J2EE Webアプリケーションとして実装され、Oracle Application Serverのインスタンスにデプロイされます。多くのWebベースのアプリケーションと同様に、管理サービスはクライアント・ブラウザをHTMLページの特定のセット(ログオン画面や特定のアプリケーション・コンポーネントまたは機能など)に頻繁にリダイレクトします。
Oracle HTTP ServerがURLをリダイレクトするとき、Oracle HTTP Serverのホスト名を含むURLをクライアント・ブラウザに送り返します。ブラウザはOracle HTTP Serverのホスト名を含んだそのURLを使用して、Oracle HTTP Serverに再接続します。その結果、クライアント・ブラウザは管理サービスのホストに直接接続し、ロード・バランサを迂回します。
URLのリダイレクト時にブラウザがロード・バランサを迂回しないように、Grid Controlは、管理サービスを再度保護する一環としてssl.confファイルを再構成します。ロード・バランサの構成後に、管理サーバーのホームからコマンドemctl secure omsを発行します。
Grid Controlは、Grid Controlコンソールに戻るリンクを設定した電子メールを使用して、通知およびレポートを送信します。SLBが構成されている場合は、個々の管理サービスではなくSLBを指すリンクを電子メールに設定する必要があります。Grid Controlコンソールの「管理サービスとリポジトリ」ページに移動します。「コンソールURLの追加」をクリックし、UIアクセスで使用されるSLB仮想サービスを指定します。
管理エージェントからのデータのフロー管理のためのロード・バランサの使用は、高可用性のGrid Control環境の構成にロード・バランサが役立つ唯一の使用方法ではありません。ロード・バランサは、Grid Controlコンソールに対する負荷のバランスをとるため、そしてフェイルオーバー・ソリューションを提供するためにも使用できます。
図3-6は、ロード・バランサが管理エージェントと複数の管理サービスの間、およびGrid Controlコンソールと複数の管理サービスの間で使用される標準的な構成を示しています。
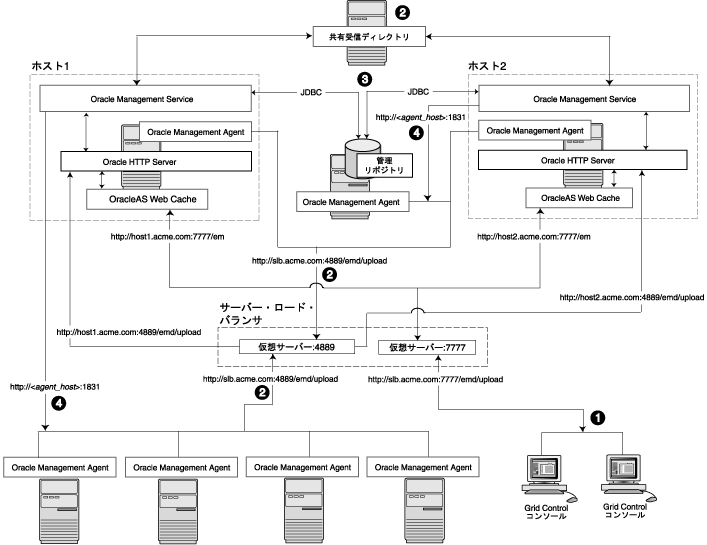
この例では、単一のロード・バランサが管理エージェントからのデータのアップロード、およびGrid Controlコンソールと管理サービスの間の接続に使用されます。
Grid Controlコンソールに対してロード・バランサを使用する場合、管理データは次のフローでGrid Controlアーキテクチャに送られます。
Enterprise Managerの高可用性の最後の項目が管理エージェントの構成です。管理エージェントの構成を始める前に、管理エージェントには高可用性がデフォルトで組み込まれている点に留意する必要があります。管理エージェントの起動時に自動作成されるウォッチドッグ・プロセスによって、各管理エージェント・プロセスが監視されます。管理エージェント・プロセスで障害が発生した場合は、ウォッチドッグがその管理エージェント・プロセスの再起動を自動的に試みます。
デフォルトのEnterprise Manager Grid Controlインストールにおける管理エージェント層と管理サービス層の間の通信は、ポイント・ツー・ポイント設定です。したがって、デフォルト構成では管理サービスが使用不可になるシナリオを防止できません。このシナリオでは、管理エージェントが監視情報を管理サービス(および管理リポジトリ)にアップロードできなくなり、その管理エージェントが2番目の管理サービスを指すように手動で構成するまでターゲットは監視対象外となります。
こうした状態を回避するには、ハードウェアのサーバー・ロード・バランサ(SLB)を管理エージェントと管理サービスの間で使用します。このロード・バランサは各管理サービスの状態とステータスを監視し、どのような障害が発生しても、ロード・バランサを介して作成された接続が稼働中の管理サービス・ノードに向けられるようにします。SLBを使用するその他の利点として、Enterprise Managerへのユーザー通信を管理するようにロード・バランサを構成できることがあげられます。ロード・バランサは、使用可能なリソースのプールを作成することでこの処理を行います。
ロード・バランサでは、すべての管理エージェントが使用可能な仮想IPアドレスを利用できます。ロード・バランサの設定後は、管理エージェントのトラフィックをSLB経由で管理サービスにルーティングするように管理エージェントを構成する必要があります。これを実行するには、管理エージェントのプロパティ・ファイルを数箇所変更します。
すべての管理エージェントを再度保護します。SLBの設定前にインストールされた管理エージェントは、管理サービスに直接アップロードされます。SLBの設定後、これらの管理エージェントはアップロードできなくなります。各管理エージェントで次のコマンドを実行することにより、これらの管理エージェントを再度保護してSLBにアップロードします。このコマンドは、Enterprise Managerリリース10.2.0.5で利用可能な管理エージェントで使用できます。これより前のリリースでは、emd.propertiesファイルを手動で編集し、secure agentコマンドを使用して管理エージェントを保護する必要があります。
emctl secure agent -emdWalletSrcUrl https://slb.example.com:
<upload port>/em
一部のインストールでは初期インストール時にSLBを利用できない場合がありますが、後でSLBが必要になることが見込まれることがあります。そのようなケースでは、初期インストールの一環として、SLBで使用する仮想IPアドレスを構成し、そのIPアドレスが既存の管理サービスを指すように設定することを検討します。管理エージェントと管理サービスの間のセキュアな通信は、ホスト名に基づいています。後で新しいホスト名を導入した場合でも、各管理エージェントを再度保護する必要はありません。各管理エージェントは、SLBによってメンテナンスされた新しい仮想IPを指すように構成されているためです。
管理エージェントから管理サービスへの管理データのフローを保護する計画を実行する前に、いくつかの主要な概念について理解しておく必要があります。
特に、管理エージェントは、管理サービスへの永続的な接続を保持しません。収集した監視データまたは緊急ターゲット状態変更をアップロードする必要がある場合、管理エージェントは管理サービスへの接続を確立します。ネットワーク障害またはホスト障害などにより接続ができない場合、管理エージェントはデータを保存し、後で情報の送信を再試行します。
管理サービスが利用できない状況を防止するために、管理エージェントと管理サービスの間でロード・バランサを使用できます。
ただし、そのような構成を実装する場合は、管理データのアップロードロード・バランシングする際のデータ・フローを理解しておく必要があります。
図3-7は、一連の管理エージェントがデータをロード・バランサにアップロードし、ロード・バランサが2つの管理サービスのいずれかにデータをリダイレクトする一般的なケースを示しています。
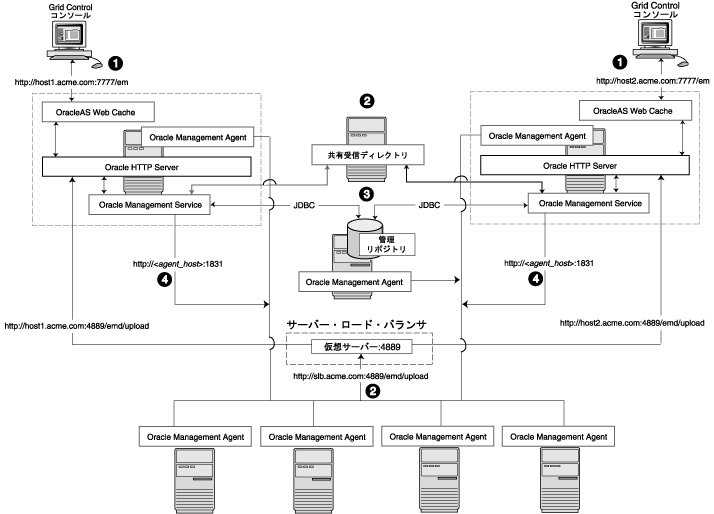
この例では、管理エージェント・データのアップロードのみがロード・バランサを介してルーティングされます。Grid Controlコンソールは、一意の管理サービスのアップロードURLを介して単一の管理サービスに直接接続します。このように抽象化することで、管理サービス・コンポーネントの1つが失われても、Grid Controlによって管理エージェントおよびGrid Controlコンソールに一貫性のあるURLが示されます。
管理エージェント・データの複数の管理サービスへのアップロードをロード・バランシングする場合、データは次のフローで送られます。
emd.propertiesファイルで定義されています。つまり、管理エージェントは、ロード・バランサによって公開される仮想サービスに接続します。ロード・バランサは、リクエストされたサービスを提供する使用可能なサーバーの1つにリクエストをルーティングします。
また、各管理サービスは、3.4項で定義した複数の管理サービス構成のように、JDBCを介して共通の管理リポジトリと通信します。
通常、高可用性では、アプリケーション障害やシステムレベルの障害など、ローカルな停止を防ぐのに対し、障害耐久力ではより大規模な停止を防ぎます。これには、自然災害、火災、停電、避難、または広範囲なサボタージュに起因する壊滅的なデータ・センターの障害などがあります。最大可用性については、サイトの損失が原因で業務を担う管理ツールが停止することはありません。
Enterprise Managerの最大可用性アーキテクチャでは、プライマリ管理インフラストラクチャで災害が発生した場合に、セカンダリ・データ・センターがその管理インフラストラクチャを引き継ぐことができる、リモート・フェイルオーバー・アーキテクチャのデプロイが規定されています。
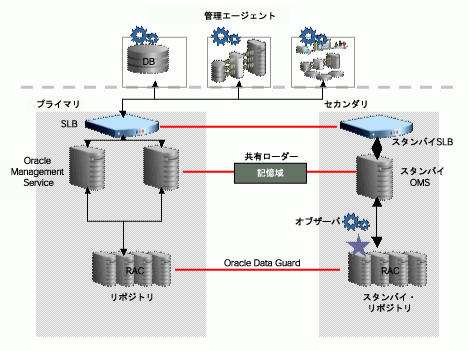
図3-8が示すように、Enterprise Managerでの災害時リカバリの設定では、基本的にはスタンバイRAC、スタンバイ管理サービスおよびスタンバイ・サーバー・ロード・バランサをインストールして、プライマリ・コンポーネントの障害発生時にこれらのスタンバイ・コンポーネントが自動的に起動するように構成します。
次の各項では、Enterprise Managerの主要コンポーネントで災害時リカバリを構成する際のベスト・プラクティスを示します。
次の前提条件を満たしている必要があります。
前述のとおり、この手順では、最初にGrid ControlのMAAガイドラインに従ってプライマリ・サイトを構成します。スタンバイ管理リポジトリ・データベースを設定する手順は、次のように規定されています。
スタンバイ管理リポジトリの各ホストに管理エージェントをインストールします。プライマリ・サイトのSLBを介してアップロードするように管理エージェントを構成します。
CRSおよびデータベース・ソフトウェアをスタンバイ管理リポジトリ・ホストにインストールします。プライマリ・サイトのものと同じバージョンを使用してください。
プライマリ管理リポジトリ・データベースをまだ構成していない場合は、アーカイブ・ログ・モードの有効化、フラッシュ・リカバリ領域の設定、およびフラッシュバック・データベースの有効化をプライマリ管理リポジトリ・データベースで行います。
Enterprise Managerでは、スタンバイ管理リポジトリ・データベースは物理スタンバイである必要があります。Enterprise Managerコンソールを使用して、前述の手順で準備したスタンバイ環境で物理スタンバイ・データベースを設定します。Enterprise Managerコンソールは、スタンバイRACデータベースの作成をサポートしていません。RACのスタンバイ・データベースを必要とする場合は、単一インスタンスを使用してスタンバイ・データベースを構成し、Enterprise ManagerコンソールのRACへの変換オプションを使用して、この単一インスタンス・スタンバイ・データベースをRACに変換します。また、単一インスタンス・スタンバイの作成時には、その後のRACへの変換を容易にするために共有記憶域にデータベース・ファイルを作成する必要があります。
Data Guardを有効にするには、ブローカ操作の過程でインスタンスを再起動し、特定の名前を付けたサービスを各インスタンスのローカル・リスナーに静的に登録する必要があります。GLOBAL_DBNAME属性の値を<db_unique_name>_DGMGRL.<db_domain>の連結に設定します。たとえば、LISTENER.ORAファイルで次のように指定します。
SID_LIST_LISTENER=(SID_LIST=(SID_DESC=(SID_NAME=sid_name) (GLOBAL_DBNAME=db_unique_name_DGMGRL.db_domain) (ORACLE_HOME=oracle_home)))
Enterprise Managerコンソールを使用して、物理スタンバイ・データベースを検証します。「Data Guard」ページの「ログ切替え」ボタンをクリックしてログの切替えを行い、ログが受信されてスタンバイ・データベースに適用されていることを確認します。
スタンバイ管理サービスをインストールする前に、次の考慮事項に留意してください。
『Oracle Enterprise Manager Grid Controlインストレーションおよび基本構成』に記載されている手順に従って、管理サービス・ソフトウェアをインストールします。ソフトウェアのみをインストールして構成は後で行う(追加の管理サービス)オプションに関する項を参照してください。プライマリ・データベースの接続設定をレスポンス・ファイルで指定します。管理サービスをインストールしたら、次の手順を実行してプライマリ管理サービスから構成をコピーします。
emctl exportconfig oms -dir <location for the export file>
emctl importconfig oms -file <full path of the export file>を使用して、エクスポートした構成をスタンバイ管理サービスにインポートします。
oracle.sysman.eml.mntr.emdRepConnectDescriptor=
<connect descriptor of standby database>を使用してemoms.propertiesファイルを更新することにより、スタンバイ管理サービスがスタンバイ管理リポジトリ・データベースを指すように設定します。
emcli setup -url=https://slb.example.com/em -username sysman -password <sysman password> -nocertvalidateを使用)。
emctl secure agent -emdWalletSrcUrl https://slb.example.com:<upload port>/emを使用して再度保護します。
追加のスタンバイ管理サービスを設定するには、前述の手順を繰り返します。
スイッチオーバーは、プライマリ・サイトからスタンバイ・サイトに操作を転送する計画アクティビティです。通常、スイッチオーバーは、災害時リカバリ(DR)シナリオのテストや検証、およびプライマリ・インフラストラクチャでの計画メンテナンス・アクティビティで実行されます。この項では、スタンバイ・サイトへのスイッチオーバーの手順を説明します。いずれの方向のスイッチオーバーでも同じ手順が適用されます。
Enterprise Managerコンソールを使用して管理リポジトリ・データベースのスイッチオーバーを実行することはできません。かわりにData Guard Brokerのコマンドライン・ツールDGMGRLを使用します。
リカバリが最新であることを確認します。Enterprise Managerコンソールを使用して、「Data Guardの概要」ページの「スタンバイ・データベース」セクションでスタンバイ・データベースの「applyLag」列の値を確認できます。
各管理サービスでコマンドopmnctl stopallを実行することにより、プライマリ・サイトのすべての管理サービスを停止します。
- alter system set job_queue_processes=0;を実行することにより、管理リポジトリ・データベースで実行しているEnterprise Managerジョブを停止します。
プライマリ・サイトのすべてのファイルがスタンバイ・サイトで使用可能であることを確認します。
DGMGRLを使用して、スタンバイ・データベースへのスイッチオーバーを実行します。このコマンドは、プライマリ・サイトとスタンバイ・サイトのどちらでも実行できます。スイッチオーバー・コマンドは、プライマリ・データベースとスタンバイ・データベースの状態の検証、ロールのスイッチオーバーの適用、旧プライマリ・データベースの再起動、および新規スタンバイ・データベースとしての旧プライマリ・データベースの設定を行います。
SWITCHOVER TO <standby database name>;
スイッチオーバー後の状態の検証:
SHOW CONFIGURATION; SHOW DATABASE <primary database name>; SHOW DATABASE <standby database name>;
opmnctl startallを実行することにより、スタンバイ・サイトのすべての管理サービスを起動します。
- alter system set job_queue_processes=10;を実行することにより、スタンバイ・サイトの管理リポジトリ・データベース(新しいプライマリ・データベース)で実行するEnterprise Managerジョブを起動します。
管理サービスおよび管理リポジトリ・ターゲットは、プライマリ・サイトのいずれかの管理サービスの管理エージェントによって監視されます。スイッチオーバーまたはフェイルオーバーの後にターゲットが監視されるようにするには、スタンバイ・サイトのいずれかの管理サービスで次のコマンドを実行することにより、スタンバイ・サイトの管理エージェントにターゲットを再配置します。
emctl config emrep -agent <agent name> -conn_desc
ネットワークを適切に変更して、プライマリSLBをスタンバイSLBにフェイルオーバーします。つまり、クライアント(ブラウザおよび管理エージェント)の変更を必要とせずに、すべてのリクエストをスタンバイSLBで処理するようにします。
これで、スイッチオーバー操作は完了です。アプリケーションにアクセスしてテストし、サイトが完全に使用可能でプライマリ・サイトと機能的に同じであることを確認します。
別の方向でスイッチオーバーするには、同じ手順を繰り返します。
元のプライマリ・データベースで障害が発生し、適時にリカバリが見込めない場合は、スタンバイ・データベースをプライマリ・データベースに変換できます。これを手動フェイルオーバーと呼びます。データ損失の有無は、プライマリ・データベースとターゲット・スタンバイ・データベースがプライマリ・データベースの障害発生時に同期化されていたかどうかによって決まります。
この項では、スタンバイ・データベースにフェイルオーバーして、管理リポジトリ・データベースをすべての管理エージェントと再同期化してEnterprise Managerアプリケーションの状態をリカバリし、フラッシュバック・データベースを使用してスタンバイとして元のプライマリ・データベースを使用可能にする手順について説明します。
3.5.6.6項「自動フェイルオーバー」で後述するファスト・スタート・フェイルオーバーとこのタイプのフェイルオーバーを対比させるために、ここでは手動という言葉を使用します。
プライマリ・サイトのすべてのファイルがスタンバイ・サイトで使用可能であることを確認します。
プライマリ・サイトのデータベースを停止します。DGMGRLを使用してスタンバイ・データベースに接続し、FAILOVERコマンドFAILOVER TO <standby database name>;を実行します。
フェイルオーバー後の状態の検証:
SHOW CONFIGURATION; SHOW DATABASE <primary database name>; SHOW DATABASE <standby database name>;
フェイルオーバーの完了後は、元のプライマリ・データベースを再度有効にする場合を除いて、元のプライマリ・データベースを新しいプライマリ・データベースのスタンバイ・データベースとして使用することはできません。
Data Guardを最大保護レベルまたは最大可用性レベルで実行している場合は、フェイルオーバーでデータの損失が発生しないため、この手順をスキップしてください。一方、データの損失が発生する場合は、新しいプライマリ・データベースをすべての管理エージェントと同期化する必要があります。
スタンバイ・サイトのいずれかの管理サービスで、次のコマンドを実行します。
emctl resync repos -full -name "<name for recovery action>"
このコマンドは、スタンバイ・サイトの管理サービスの起動時に各管理エージェントで実行される再同期化ジョブを発行します。
リポジトリの再同期化は、リソースを大量に消費する操作です。管理リポジトリの適切なチューニングは、操作の迅速な完了に大きく役立ちます。サイトのパフォーマンスを維持するルーチン・ハウスキーピング・ジョブについては、第11章「Oracle Enterprise Managerのパフォーマンスのサイジングおよび最大化」を参照してください。特に、My Oracle Supportのノート271855.1に記載されている、アドバンスト・キューイングの表に関連付けられたIOT/索引の結合を日常的に行わない場合は、再同期化の前にこの手順を実行すると、再同期化操作の迅速な完了が促進されます。
各管理サービスで次のコマンドを実行することにより、スタンバイ・サイトのすべての管理サービスを起動します。
opmnctl startall
管理サービスおよび管理リポジトリ・ターゲットは、プライマリ・サイトのいずれかの管理サービスの管理エージェントによって監視されます。スイッチオーバーまたはフェイルオーバーの後にターゲットが監視されるようにするには、スタンバイ・サイトのいずれかの管理サービスで次のコマンドを実行することにより、スタンバイ・サイトの管理エージェントにターゲットを再配置します。
emctl config emrep -agent <agent name> -conn_desc
ネットワークを適切に変更して、プライマリSLBをスタンバイSLBにフェイルオーバーします。つまり、クライアント(ブラウザおよび管理エージェント)の変更を必要とせずに、すべてのリクエストをスタンバイSLBで処理するようにします。
障害が発生したサイトへのアクセスがリストアされ、フラッシュバック・データベースが有効になっている場合は、元のプライマリ・データベースを新しいプライマリ・データベースの物理スタンバイとして回復できます。
opmnctl stopall
shutdown immediate;
startup mount;
DGMGRLを使用して旧プライマリ・データベースに接続し、REINSTATEコマンドを実行します。
REINSTATE DATABASE <old primary database name>;
SHOW CONFIGURATION; SHOW DATABASE <primary database name>; SHOW DATABASE <standby database name>;
失敗した操作は、示されたエラーの修正後にこのページから手動で再発行する必要があります。通常、通信関連のエラーは管理エージェントの停止に起因し、管理エージェントの再起動後にこのページから操作を再発行することで修正できます。
廃止された古い管理エージェントなど、なんらかの理由により起動できない管理エージェントでは、このページを使用して手動で操作を停止する必要があります。すべてのジョブが完了または停止ステータスの場合は、再同期化が完了したものと考えられます。
これで、フェイルオーバー操作は完了です。アプリケーションにアクセスしてテストし、サイトが完全に使用可能でプライマリ・サイトと機能的に同じであることを確認します。
サイトの操作を元のプライマリ・サイトに再度移動する必要がある場合は、スイッチオーバーの手順を実行します。
この項では、ファスト・スタート・フェイルオーバーおよびオブザーバ・プロセスを使用して、障害検出とフェイルオーバー手順の完全自動化を実現する手順について詳しく説明します。概括すると、このプロセスは次のように行われます。
次の手順を実行します。
Enterprise Managerアプリケーションの構成および起動プロセスを自動化するスクリプトを開発します。Grid Controlに添付されている、OH/sysman/haディレクトリ内のサンプルを参照してください。このディレクトリにはスタンバイ・サイト用のサンプル・スクリプトが格納されており、必要に応じてカスタマイズする必要があります。パスワード・プロンプトを介さずにリモート・シェル・スクリプトを実行できるように、ssh等価を設定してください。スタンバイ・データベース・ホストがアクセスできる場所にこのスクリプトを置きます。同様のスクリプトをプライマリ・サイトに置きます。
#!/bin/sh # Script: /scratch/EMSBY_start.sh # Primary Site Hosts # Repos: earth, OMS: jupiter1, jupiter2 # Standby Site Hosts # Repos: mars, # OMS: saturn1, saturn2 LOGFILE="/net/mars/em/failover/em_failover.log" OMS_ORACLE_HOME="/scratch/OracleHomes/em/oms10g" CENTRAL_AGENT="saturn1.example.com:3872" #log message echo "###############################" >> $LOGFILE date >> $LOGFILE echo $OMS_ORACLE_HOME >> $LOGFILE id >> $LOGFILE 2>&1 #startup all OMS #Add additional lines, one each per OMS in a multiple OMS setup ssh orausr@saturn1 "$OMS_ORACLE_HOME/opmn/bin/opmnctl startall" >> $LOGFILE 2>&1 ssh orausr@saturn2 "$OMS_ORACLE_HOME/opmn/bin/opmnctl startall" >> $LOGFILE 2>&1 #relocate Management Services and Repository target #to be done only once in a multiple OMS setup #allow time for OMS to be fully initialized ssh orausr@saturn1 "$OMS_ORACLE_HOME/bin/emctl config emrep -agent $CENTRAL_AGENT -conn_desc -sysman_pwd <password>" >> $LOGFILE 2>&1 #always return 0 so that dbms scheduler job completes successfully exit 0
データベース・イベントDB_ROLE_CHANGEトリガーを作成します。このトリガーは、データベース・ロールがスタンバイからプライマリに変更されると起動します。Grid Controlに添付されている、OH/sysman/haディレクトリ内のサンプルを参照してください。
-- -- -- Sample database role change trigger -- -- CREATE OR REPLACE TRIGGER FAILOVER_EM AFTER DB_ROLE_CHANGE ON DATABASE DECLARE v_db_unique_name varchar2(30); v_db_role varchar2(30); BEGIN select upper(VALUE) into v_db_unique_name from v$parameter where NAME='db_unique_name'; select database_role into v_db_role from v$database; if v_db_role = 'PRIMARY' then -- Submit job to Resync agents with repository -- Needed if running in maximum performance mode -- and there are chances of data-loss on failover -- Uncomment block below if required -- begin -- SYSMAN.setemusercontext('SYSMAN', SYSMAN.MGMT_USER.OP_SET_IDENTIFIER); -- SYSMAN.emd_maintenance.full_repository_resync(('AUTO-FAILOVER to '||
v_db_unique_name); -- SYSMAN.setemusercontext('SYSMAN', SYSMAN.MGMT_USER.OP_CLEAR_IDENTIFIER); -- end; -- Start the EM mid-tier dbms_scheduler.create_job( job_name=>'START_EM', job_type=>'executable', job_action=> '<location>' || v_db_unique_name|| '_start_oms.sh', enabled=>TRUE ); end if; EXCEPTION WHEN OTHERS THEN SYSMAN.mgmt_log.log_error('LOGGING', SYSMAN.MGMT_GLOBAL.UNEXPECTED_ERR, SYSMAN.MGMT_GLOBAL.UNEXPECTED_ERR_M || 'EM_FAILOVER: ' ||SQLERRM); END; /
Enterprise Managerコンソールのファスト・スタート・フェイルオーバー構成ウィザードを使用すると、FSFOを有効にしてオブザーバを構成できます。
これで、自動フェイルオーバーの設定は完了です。
次の各項で、各Grid Controlコンポーネントのインストールおよび構成のベスト・プラクティスについて説明します。
管理エージェントは手動で起動します。管理対象ホスト上のクリティカルなリソースを確実に監視するためには、ホストの起動時に管理エージェントを自動的に起動することが重要です。このためには、管理エージェントを自動的に起動するためのあらゆるオペレーティング・システム・メカニズムを使用します。たとえば、UNIXシステムで、UNIXの/etc/init.d内に起動時に管理エージェントをコールするエントリを挿入したり、Windowsサービスが自動的に起動されるように設定します。
管理エージェントが起動されると、ウォッチドッグ・プロセスによって管理エージェントが監視され、障害時には管理エージェントの再起動が試行されます。このウォッチドッグの動作は、管理エージェント・プロセスの起動前に設定された環境変数によって制御されます。この動作を制御する環境変数を次に示します。ここで説明しているテストはすべて、デフォルトの設定で行われたものです。
EM_RETRY_WINDOWの時間枠内でEM_MAX_RETRIESを超える回数の再起動試行が必要であることが検出される場合、ウォッチドッグは管理エージェントを再起動しません。
管理エージェントは、管理エージェント・ホーム・ディレクトリの下の$AGENT_HOME/$HOSTNAME/sysman/emdサブツリー内のローカル・ファイルを使用して、その中間状態および収集済情報を持続します。
これらのファイルが管理リポジトリにアップロードされる前に失われたり、破損した場合には、監視データの損失、および管理リポジトリにまだアップロードされていないという保留中アラートが発生します。
少なくとも、ストライプ化された冗長記憶域またはミラー化された記憶域にこれらのサブディレクトリを構成してください。可用性をさらに高めるには、$AGENT_HOME全部を冗長記憶域に置きます。管理エージェント・ホーム・ディレクトリを表示するには、コマンドラインでemctl getemhomeを入力するか、Grid Controlコンソールで「管理サービスとリポジトリ」タブおよび「エージェント」タブを使用します。
管理サービスには、管理リポジトリにロードされる前の中間収集データの結果が含まれます。ローダー受信ディレクトリにはこれらのファイルが含まれます。管理サービスがデータを受信してすぐにロードできる場合、ローダー受信ディレクトリは通常は空です。管理サービスがファイルを受け取ると、管理エージェントはそれらのファイルがコミットされたとみなすため、そのローカル・コピーを削除します。これらのファイルが管理リポジトリにアップロードされる前に失われた場合は、データ損失が発生します。少なくとも、ストライプ化された冗長記憶域またはミラー化された記憶域にこれらのサブディレクトリを構成してください。管理サービスが共有ファイルシステム・ローダー用に構成されている場合は、すべてのサービスが同じローダー受信ディレクトリを共有します。共有ローダー受信ディレクトリは、NetApp Filerのようなクラスタ・ファイル・システム上に置くことをお薦めします。
Grid Controlでは、多数の一般的なターゲットを監視するための一連のデフォルト・ルールが事前に構成されています。特定の監視要件にあわせて、これらのルールを、Grid Controlインフラストラクチャおよびシステム上の他のターゲットを監視するように拡張できます。
Enterprise Managerで実行されるデフォルトの監視を拡張するための推奨方法を次に示します。「プリファレンス」ページの「通知ルール」を使用して、「構成」/「ルール」ページに表示されたデフォルト・ルールを調整します。
管理サービスのステータスが警告または消去のしきい値に到達した場合に警告するように、エージェントのアップロードの問題ルールを変更します。
Enterprise Managerには、電子メール通知、PL/SQLパッケージおよびSNMPアラートを介するエラー報告メカニズムが備わっています。これらのメカニズムを、本番サイトのインフラストラクチャに基づいて構成してください。通知に電子メールを使用する場合は、Grid Controlコンソールから、(使用可能な場合は)複数のSMTPサーバーを使用して管理者への通知を行うように通知ルールを構成します。これを行うには、「設定」から「通知メソッド」オプションのデフォルトの電子メール・サーバー設定を変更します。
データベースのバックアップ手順は、標準として定着しています。Grid Controlコンソールに備わっているRMANインタフェースを使用して、管理リポジトリのバックアップを構成します。詳細な実装手順は、RMANのドキュメントまたは最大可用性アーキテクチャのドキュメントを参照してください。
管理リポジトリの他、管理サービスと管理エージェントも定期的にバックアップする必要があります。構成を変更した後は必ずバックアップを実行する必要があります。これらの層をバックアップするためのベスト・プラクティスは、11.3項「Oracle Enterprise Managerのバックアップ、リカバリおよび障害時リカバリの考慮事項」で説明しています。
Grid Controlで問題が発生した場合、まず最初に診断する必要があるのはコンソールそのものです。「管理システム」タブから、すべての管理サービス操作および現在のアラートの概要を表示できます。他のページにも、管理サービス・プロセスの状態と、記録されたエラーが要約して示されます。管理リポジトリへのロードを待機中のファイル量と、管理エージェントによる完了を待機中の処理量がサマリー・ページに履歴表示されるため、これらのページはパフォーマンス問題の原因の特定に役立ちます。
Grid Controlコンソールからターゲットの状態および可用性を評価する場合、特に管理サービスの停止後には、UIへの情報表示が遅れます。監視対象ホストの状態が変更された後は、Grid Controlコンソールでのターゲットの状態が遅延する場合があります。「管理システム」ページを使用して、処理が保留されているファイルのバックログを調べてください。
管理エージェントで特定の監視対象ターゲットの状態の評価に使用されるモデルは、ポーリングに基づいています。管理エージェントは、状態変更が検出されるとすぐに、管理サービスに通知を送ります。このため、管理エージェントが実際に状態変更を検出するまでに遅延が発生する可能性があります。
|
 Copyright © 2003, 2009 Oracle Corporation. All Rights Reserved. |
|