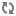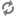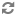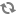A language analysis is a set of rules that the MDEX Engine applies when it indexes text in any of the languages in a particular language group. The languages in this group have common characteristics that require specialized handling by an appropriate language analysis.
Every form of language analysis provides, at a minimum, tokenization: the breaking up of compound phrases into their constituent words or characters. Language analysis can optionally include stemming, which makes it possible to match inflected word forms that share a stem; for example, to treat "family", "families", and "family's" as forms that match each other. Each language analysis includes a different set of other text management features, such as ignoring "stop words" (that is, words with little or no value for searches, such as "the") or ignoring accents (diacritic folding).
The MDEX Engine can apply a language analysis to records, record properties, dimension tags on records, or to all record data processed by an MDEX Engine. Only one language analysis can be applied to any of these units at a time.
Oracle Commerce Guided Search supports two standard forms of language analysis, Latin-1 and OLT (Oracle Language Technologies), which are designed for use with different languages. Customers can create and use non-standard language analyses, if neither Latin-1 nor OLT meets their requirements. For detailed information about Latin-1 and OLT language analysis, see Latin-1 and OLT Language Analysis.
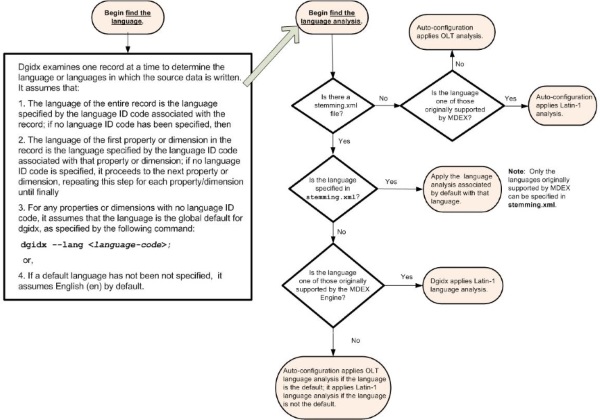
To choose a language analysis to use for processing a particular record, the MDEX Engine follows these steps:
If it finds a language ID code for the record, it assumes that all the record's content is in that language and applies the appropriate the language analysis to the record as a whole.
If it does not find a language ID code for the record, it examines the properties of the record in sequence, as follows:
It examines each property to determine whether a language ID code has been specified for that property.
If it finds that a language ID code has been specified for the property, it associates that language with the property value and proceeds to the next property in the record.
If it does not find a language ID code for a property, it proceeds to the next property.
When it has examined all properties, it applies the default language for MDEX as a whole (as specified by
dgidx) to any properties for which no language ID code is specified; or, if no default language has been specified,--lang<language code>It applies
en(United States English) to any properties for which a language ID code is not specified.
The MDEX Engine then analyzes the next record, beginning with Step 1.
Note
In the preceding sequence of steps, the MDEX Engine treats dimensions the same way that it treats properties.
For information about how language ID codes can be associated with records, properties, and dimensions, see Assigning Language IDs globally, per record, and per property. For information about dgidx, refer to the Oracle Commerce Guided Search Administrator's Guide.
When dgidx has determined the language of the record, property, or
dimension, it consults the
stemming.xml
file (if one exists) to determine whether it contains an entry
for that language. If an entry exists, dgidx uses information in the entry to
decide which language analysis to apply to the language, and which features of
that analysis to use. If no stemming file exists, or one exists but does not
contain an entry for a particular language, an applicable default language
analysis is applied. For information about
stemming.xml, see
Specifying Language
Analysis in stemming.xml.
The following figure illustrates the process by which the MDEX Engine chooses a language analysis as described above: