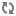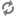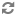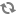Guided Search supports different collations for sorting in different languages. These include the Endeca collation, the Standard collation, and several language-specific collations. Guided Search uses the Endeca collation by default.
The Endeca collation places lower case characters before the upper case versions of those same characters. For example, the Endeca collation sorts text as follows:
0 < 1 < ... < 9 < a < A < b < B < ... < z < Z
The Endeca collation is optimized for unaccented languages and ignores accents and punctuation. For this reason, in applications that use English as their global language, the Endeca collation performs better during indexing and query processing than the Standard collation. In applications that use non-Latin scripts or Latin scripts with accents, the Endeca collation may produce unexpected results for accented characters.
The Standard collation sorts data according to the International
Components for Unicode (ICU) standard for the language you specify with
--lang flag. For details about the standard collation
for a particular language, see the Unicode Common Locale Data Repository
at
http://cldr.unicode.org/. In applications that
include internationalized data, the Standard collation is typically the more
appropriate choice because it accounts for character accents during sorting.
In addition to the Endeca and Standard collations, dgidx and the dgraph support the following language-specific ICU collations:
de-u-co-phonebk, a German collation that sorts according to phone book order rather than by dictionary order.es-u-co-trad, a Spanish collation that sorts the ch and ll characters in the traditional order rather than the standard order.zh-u-co-endeca, zh-TW-u-co-endecaFor basic Latin characters, lowercase characters are placed before uppercase characters. Otherwise, characters are sorted by the numeric value of their UNICODE encodings (that is, by "code point" order).zh-u-co-pinyin, zh-TW-u-co-pinyin, an alphabetic sort of the Romanization of the readings of Chinese characterszh-u-co-big5han,zh-TW-u-co-big5han, which collates in the order of the big5han character encoding once used for Traditional Chinese. The encoding is now Unicode, but the collation order remains in use.zh-u-co-gb2312han, zh-TW-u-co-gb2312han, a collation defined by the GB2312 standard (mainland China) for Simplified Chinese. It is a mixture of pinyin for common characters and radical/stroke for less common characters.zh-u-co-stroke, zh-TW-u-co-stroke, a collation based on the total stroke count of the characters and is typically used with Traditional Chinese.zh-u-co-unihan, zh-TW-u-co-unihan, a collation defined by the Unified Han (Unihan) standard and based on (most significant first) radical/stroke, then Unicode block, and finally code point.
The following section explains how to specify the collation that you want to use for your data.