

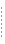

|
|
BEA AquaLogic Service Bus では、システム処理に必要な実行時情報をモニタおよび収集できます。AquaLogic Service Bus で集約された実行時統計はダッシュボードに表示できます。ダッシュボードでは、システムのヘルス状態をモニタし、サービスでアラートが生成された場合に通知を受けることができます。この情報を使用すると、時間をかけずに簡単に、発生した問題を特定し、診断できます。
AquaLogic Service Bus のモニタでは、操作リソース、サーバ、およびサービス レベル アグリーメントをモニタします。図 3-1 に、AquaLogic Service Bus モニタのアーキテクチャを示します。
統計コンフィグレーション マネージャでは、操作リソースごとの統計コンフィグレーションを保存し、管理します。操作リソースは、モニタ サブシステムにより統計情報を収集できる単位として定義されます。操作リソースには、プロキシ サービス、ビジネス サービス、Web Services Definition Language (WSDL) オペレーションなどのサービス レベル リソース、パイプラインのフロー コンポーネントなどがあります。パイプラインの追加、更新、削除などのサービス定義の変更は、統計コンフィグレーション マネージャに通知されます。
クラスタ内の管理対象サーバがそれぞれ統計コレクタをホストします。統計コレクタは、統計コンフィグレーション マネージャの指示に従って、操作リソースの統計を収集します。また、集約間隔の時間が経過するまで、収集した統計のサンプル履歴も保持します。システム定義のチェックポイント間隔ごとに、統計コレクタは回復の目的で現在の統計のスナップショットを永続ストアに格納し、情報を統計集約機能に送信します。
クラスタ内の管理対象サーバの 1 つはクラスタ全体の統計の集約機能に指定され、「集約サーバ」または「アグリゲータ」と呼ばれます。システム定義のチェックポイント間隔ごとに、クラスタ内の各管理対象サーバは統計のスナップショットを集約機能に送信します。次に、集約機能はこの情報を結合し、クラスタ全体の統計を統計取得 API によりクライアントに提供します。集約機能のクライアントはダッシュボード、SLA マネージャ、およびサービス モニタ モジュールです。
システムにデータ ポイントを提供するために、ランタイム プロキシ サービス パイプラインなどのシステムの操作リソースが統計コレクタのメソッドを呼び出し、そのリソース自体、統計、およびデータ ポイントを示します。
アラートは、AquaLogic Service Bus で発生し、サービス レベル アグリーメントの違反の可能性を示します。アラートは以下の用途に使用できます。
アラートは、プロキシ サービスのメッセージ フローでも発生させることができます。メッセージ フローのアラートは、以下の用途に使用できます。
SLA アラートのアラート ルール、またはプロキシ サービスのメッセージ フローのアラート アクションにアラートの重大度をコンフィグレーションできます。以下のいずれかの重大度のレベルを使用して、アラートをコンフィグレーションできます。
アラートが発生すると、アラート送り先に通知されます。アラート ルールにアラート送り先をコンフィグレーションしていない場合は、AquaLogic Service Bus Console に通知が送信されます。アラート送り先の詳細については、「アラート送り先について」を参照してください。
SLA アラートは、サービス レベル アグリーメント (SLA) の違反に対する応答を自動化したものです。これらのアラートは AquaLogic Service Bus ダッシュボードに表示されます。サービスがサービス レベル アグリーメントまたは事前定義された条件に違反した場合に生成されます。SLA アラートを発生させるには、サービス レベルとグローバル レベルの両方で SLA アラートを有効にする必要があります。サービスのモニタを有効または無効にする方法については、「サービスのモニタ」を参照してください。[アラート履歴] パネルには、システムにおける違反またはイベントの発生に関する情報を表示する、カスタマイズ可能なテーブルがあります。
ビジネスおよびパフォーマンスの要件に従い、許容できないサービス パフォーマンスを指定するアラート ルールを定義する必要があります。アラート ルールをコンフィグレーションするときに、アラート ルールごとにそのルールの集約間隔を指定できます。この集約間隔は、サービスに設定された集約間隔の影響を受けません。集約間隔の詳細については、「集約間隔」を参照してください。アラート ルールにより、コンフィグレーションされたアラート送り先に通知を送信できます。アラート ルールの定義については、『AquaLogic Service Bus Console の使い方』の「アラート ルールの作成」を参照してください。
サービス レベル アグリーメントを検証するには、以下の使用例を考慮してください。
特定のプロキシ サービスで、応答時間の低下が原因で SLA アラートが生成されているとします。この問題を調査するには、AquaLogic Service Bus Console にログインし、このプロキシ サービスの詳しい統計を確認する必要があります。このレベルで、パイプラインにおけるサードパーティの Web サービス呼び出しステージに非常に時間がかかっており、これが実際のボトルネックになっていることを特定できます。これらのアラートを、サービス レベル アグリーメントのネゴシエーションの基盤として使用できます。サードパーティの Web サービス プロバイダとのサービスレベル アグリーメントの再ネゴシエーションに成功したら、この Web サービス プロバイダが新しいアグリーメント条件に準拠しているかどうかを追跡するアラート メトリックをコンフィグレーションする必要があります。
メッセージ フローのレポート カテゴリで使用できるアラート アクションを定義するたびに、メッセージ フローでパイプライン アラートを生成できます。
XQuery エディタなどのパイプライン エディタで使用できる条件構文や if-then-else 構文を使用して、パイプライン アラートをトリガする条件も定義できます。アラートの送り先を定義するには、アラート ルールにアラート送り先リソースをコンフィグレーションする必要があります。
パイプラインを含むアラート本文とコンテキスト変数を完全に制御できるようになります。また、メッセージの一部を抽出することもできます。ステージでのアラート アクションのコンフィグレーション方法の詳細については、『AquaLogic Service Bus Console の使い方』の「プロキシ サービス : アクション」にある「アラート」を参照してください。アラートはアラート送り先に通知されます。
AquaLogic Service Bus Console の [ダッシュボード] ページに、サービスで生成されたすべてのアラートをまとめて表示できます。
アラート送り先は、アラートがディスパッチされるリソースです。
AquaLogic Service Bus Console は、すべてのアラート通知のデフォルトのアラート送り先です。アラート送り先をコンフィグレーションしているかどうかに関わらず、アラートは AquaLogic Service Bus Console に通知されます。SLA 違反によって生成されたアラート、またはパイプラインにコンフィグレーションされたアラート アクションの結果として生成されたアラートの情報が示されます。[ダッシュボード] ページには、AquaLogic Service Bus の全般的なヘルス情報が表示されます。サーバ、サービス、およびアラートで構成されたシステムの状態の概要が示されます。
ダッシュボードの情報を解釈する方法については、「AquaLogic Service Bus ダッシュボード」を参照してください。
AquaLogic Service Bus では、以下のアラート送り先を 1 つまたは複数コンフィグレーションできます。
電子メールは、アラート送り先の 1 つです。このアラート送り先をコンフィグレーションするには、SMTP サーバ グローバル リソースを使用するか、WebLogic サーバの JavaMail セッションを使用する必要があります。SMTP サーバ リソースの詳細については、『AquaLogic Service Bus Console の使い方』の「SMTP サーバの概要」を参照してください。JavaMail セッションのコンフィグレーションの詳細については、WebLogic Server Administration Console オンライン ヘルプの「JavaMail へのアクセスのコンフィグレーション」を参照してください。
SMTP サーバ グローバル リソースは SMTP サーバのポート番号のアドレス、および認証資格 (必要な場合) を取り込みます。この認証資格はサービス アカウントとして格納されるのではなく、インラインで格納されます。Alert Manager は、パイプライン アラートと SLA アラートの両方が発生すると、電子メール アラート送り先を使用して発信電子メール メッセージを送信します。アラートが電子メールで配信されるときに、アラートの詳細で構成されるメタデータが、コンフィグレーションされたペイロードにプレフィックスされます。
受信者の電子メール ID を [メール受信者] フィールドに指定できます。電子メール アラート送り先のコンフィグレーションの詳細については、『AquaLogic Service Bus Console の使い方』の「アラート送り先」にある「電子メール受信者の追加」を参照してください。
簡易ネットワーク管理プロトコル (SNMP) トラップにより、サードパーティ製ソフトウェアを AquaLogic Service Bus でのサービス レベル アグリーメント (SLA) のモニタに結びつけることができます。SNMP を使用してアラートの通知を有効にすることで、Web サービス管理 (WSM) ツールおよび ESM (Enterprise Service Management) ツールは、アラート通知をモニタして SLA 違反とパイプライン アラートをモニタできます。
簡易ネットワーク管理プロトコル (SNMP) は、リソースの管理に関する情報をネットワーク上で交換できるようにするアプリケーション層プロトコルです。SNMP により、リソースをモニタし、必要に応じて、リソースから取得したデータに基づいて処理を行うことができます。AquaLogic Service Bus では、SNMP version 1 と SNMP version 2 の両方がサポートされています。SNMP は、以下のコンポーネントで構成されます。
このリソースは、モニタ対象のリソースです。リソースとその属性が管理情報ベース (MIB) に追加されます。
管理情報ベース (MIB) は、モニタ対象のすべてのリソースを階層的に格納するデータ構造です。MIB はリソースの属性も格納します。各リソースには、オブジェクト識別子 (OID) と呼ばれるユニークな識別子が割り当てられます。SNMP コマンドを使用してリソースの管理に関する情報を取得できます。以下の節では、WebLogic Server MIB について説明します。
Weblogic Server インストーラは、以下の場所に MIB のコピーを作成します。
<BEA_HOME>/weblogic92/server/lib/BEA-WEBLOGIC-MIB.asn1
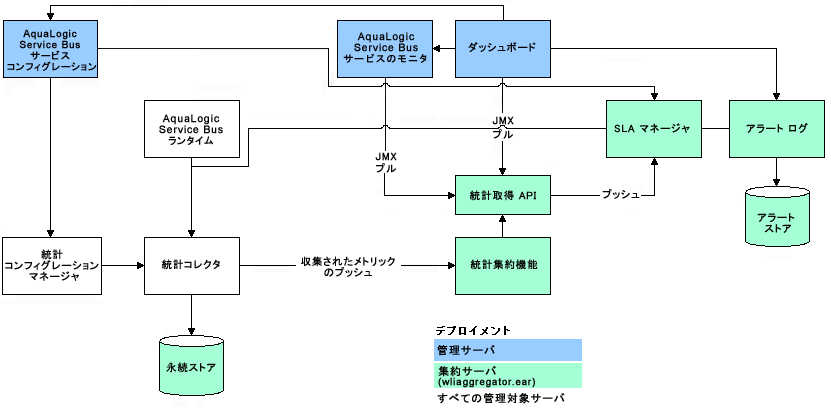
ここで、<BEA_HOME> は WebLogic Server のインストール先のディレクトリです。WebLogic Server は、その管理システムに非常に多くのデータ ポイントを公開します。WebLogic Server では、このデータを整理するために、階層データ モデルを使用して、ドメイン内で使用できるサービスとリソースの集合を表します。図 3-2 は、MIB 内のオブジェクトの階層を示しています。
たとえば、ドメイン内に MS1 および MS2 という 2 つの管理対象サーバを作成した場合、MIB には、1 つの serverTable オブジェクトが含まれ、このオブジェクトに 1 つの serverName オブジェクトが含まれます。さらに、serverName オブジェクトには、値 MS1 と MS2 をそれぞれ格納する 2 つのインスタンスが含まれます。MIB は、各管理対象オブジェクトにオブジェクト識別子 (OID) と呼ばれるユニークな番号を割り当てます。OID は一度割り当てられると変更できません。各 OID は一連の整数から構成されています。この整数の配列は、MIB ツリー内でのオブジェクトの場所を定義しています。パスの各ノードは、番号とそれに関連付けられた名前を持っています。
WebLogic Server MIB の詳細については、『WebLogic Server® 9.2 MIB Reference』にある WebLogic Server のドキュメントを参照してください。
各管理対象リソースは、SNMP エージェントを使用して MIB 内の関連情報を更新します。これを行うには、管理対象リソース内で特定の条件を検出し、SNMP マネージャにトラップ通知 (レポート) を送信するように SNMP エージェントをコンフィグレーションする必要があります。以下のいずれかの方法でトラップを生成するように、SNMP エージェントをコンフィグレーションできます。
SNMP マネージャは SNMP エージェントを管理します。また、SNMP マネージャは、ネットワーク管理システムへのプライマリ インタフェースでもあります。
ネットワーク管理システムはユーザとのインタフェースを形成します。SNMP マネージャを使用してデータを収集し、ユーザに示します。
Java Messaging Service (JMS) は、パイプライン アラートおよび SLA アラートのもう 1 つの送り先です。アラートの JMS 送り先には JNDI URL をコンフィグレーションする必要があります。アラート ルールをコンフィグレーションして JMS 送り先にメッセージをポストする場合、JMS 接続ファクトリおよびキューまたはトピックを作成し、WebLogic Server Administration Console の該当する JMS サーバを対象に設定する必要があります。この方法については、『Weblogic JMS のコンフィグレーションと管理』の「基本 JMS システム リソースのコンフィグレーション」にある JMS 接続ファクトリのコンフィグレーションおよびドメインの相互運用性を実現するための JMS リソースの命名規則を参照してください。JMS アラート送り先を定義するときは、送り先キューまたは送り先トピックを使用できます。メッセージのタイプは、バイトまたはテキストのいずれかです。JMS アラート送り先のコンフィグレーション方法の詳細については、『AquaLogic Service Bus Console の使い方』の「アラート送り先」を参照してください。
レポート送り先により、パイプライン アラートまたは SLA アラートの通知をデフォルトの AquaLogic Service Bus JMS レポート プロバイダ、または AquaLogic Service Bus に用意されているレポート API を使用して作成できるカスタム レポート プロバイダに送信できます。これにより、カスタム Java コードを使用して、サード パーティがアラートを受信および処理できます。レポートの詳細については、「レポート」を参照してください。
AquaLogic Service Bus では、発生するアラートに基づいて条件を定義する必要があります。この条件はアラート ルールと呼ばれます。アラート ルールでは、アラートの重大度とアラート送り先もコンフィグレーションします。
アラートは SLA 違反に対する応答を自動化したもので、ダッシュボードに表示されます。ビジネスおよびパフォーマンスの要件に従い、許容できないサービス パフォーマンスを指定するアラート ルールを定義する必要があります。アラート ルールをコンフィグレーションするときに、集約間隔を指定できます。アラートの集約間隔は、サービスに設定された集約間隔の影響を受けません。集約間隔の詳細については、「集約間隔」を参照してください。
| 注意 : | サービスのモニタを有効にしていない場合でも、アラート ルールを作成できます。 |
アラート ルールの作成方法の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「アラート ルールの作成」を参照してください。
[アラート ルール] ページで [アラート間隔] を [毎回] に設定した場合、アラート ルールが true に評価されるたびにダッシュボードに通知が発行されます。[アラート間隔] を [1 回通知] に設定した場合、ルールが始めて True に評価されたときに通知が発行されます。それ以降は、条件がリセットされ、もう一度 True に評価されるまで、通知は生成されません。
[アラート間隔] を [毎回] に設定した場合、アラート ルールの発生回数は、そのルールに関連付けられた集約間隔によって異なります。たとえば、集約間隔が 5 分に設定されている場合は、サンプル間隔が 1 分になります。5 つのデータ サンプルが利用可能になると、ルールが評価されます。したがって、ルールは作成されてから約 5 分後に初めて評価され、それ以降は 1 分ごとに評価されます。
[アラート間隔] を [1 回通知] に設定した場合、最初に集約間隔でアラートが発生した後は、同じ集約間隔でアラートが再び発生することはありません。
[アラート履歴] テーブルでアラート ルール (またはアラート概要) の名前をクリックすると、このページにアクセスできます。[アラートの詳細] ページには、アラートに関する詳しい情報が表示されます。図 3-3 に示すように、アラートにアノテーションを追加できます。アラート ルールの名前をクリックすると、[アラート ルールの詳細の表示] ページに移動します。サービスの名前をクリックすると、プロキシ サービスまたはビジネス サービスの [サービスのモニタの詳細] ページに移動します。[削除] をクリックすると、アラート ルールが削除されます。アラートの詳細の表示については、『AquaLogic Service Bus Console の使い方』の「モニタ」にあるアラートの詳細を参照してください。

[アラート ルールの詳細の表示] ページには、図 3-4 に示すように、特定のアラート ルールに関する詳細情報が表示されます。このページにアラート ルールの詳細を表示できます。このページでアラート ルールのコンフィグレーションを編集できます。アラート ルールの編集方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「アラート ルールの作成」の「コンフィグレーションを確認するには」を参照してください。
![[アラート ルールの詳細の表示] ページ](wwimages/alert_rules_details.gif)
この節では、質問と回答の形式で説明します。よくある質問のいくつかを次に示します。
サーバを起動し、サービスでは要求を処理していません。なぜアラートが生成されるのでしょうか。
回答 : モニタ サブシステムでサービスのデータ収集を開始すると、サーバを停止し再起動しても収集プロセスは中断されません。収集されたデータは保持され、統計収集は中断された箇所から再開されます。
アラート ルールを作成し、成功率が一定の割合を下回るとエラーが発生するように条件を定義しました。なぜ条件が true でないときにもアラートが発生するのでしょうか。
集約間隔 : 0 時間 5 分
成功率 < 80%
[サービスのモニタの概要] ページには、以下の値が示されています。
この場合、なぜアラートが発生したのでしょうか。この場合の成功率は 80% ではないでしょうか。
回答 : いいえ。表示されたメッセージ数の値は、エラーが発生したメッセージを含め、サービスで処理されたメッセージの総数です。したがって、この場合の成功率は 75% です。
JMS メッセージを送信する集約間隔 10 分のサービスを作成しました。[サービスのモニタの概要] ページにメッセージ数が表示されていました。一定時間の経過後、このサービスのメッセージ数が 0 と表示されるのはなぜでしょうか。
回答 : [サービスのモニタの概要] ページには、動的な統計が表示されます。この場合、直前 10 分間のメッセージ数が表示されます。直前 10 分間にシステムでメッセージが処理されていなかったため、メッセージ数は 0 と表示されました。
サービスの集約時間を変更しました。なぜ [サービスのモニタの概要] ページの [現在の集約間隔] にこのサービスの統計が表示されないのでしょうか。
回答 : 1 つのサービスの集約間隔を変更すると、すべてのサービスの統計情報およびそのサービスに関連付けられたアラートが削除されます。アラートは再度初期化され、集約間隔が終了した時点でトリガされます。
複数のエンドポイントがあるビジネス サービスにアラート ルールを定義しました。エンドポイントの 1 つがダウンしたとき、アラートがトリガされました。サービスに 1 つのエンドポイントしかない場合に、なぜエラーが生成されるのですか。
例 : 複数のエンドポイントがあるビジネス サービスにフェイルオーバ数 > 0 とアラート ルールを定義しています。エンドポイントの 1 つがダウンすると、アラートがトリガされます。しかし、サービスに 1 つのエンドポイントしかない場合、このサービスのフェイルオーバ数は増分されず、代わりに、エラーが発生します。
回答 : 再試行回数を 0 より大きい数に設定してください。再試行回数の設定については、『AquaLogic Service Bus Console の使い方』の「ビジネス サービス」にある「ビジネス サービスの追加」を参照してください。
ダッシュボードにはアラートが生成されたことが示されていますが、なぜ [サービスのモニタの詳細] ページの [現在の集約間隔] に反映されていないのですか。
回答 : アラート ルールは間隔の完了後に評価されます。これは、チェックポイントの完了後に発生します。ルールが true に評価されると、ルールのアクションがトリガされ、ログが生成されて、間隔数統計属性 ([現在の集約間隔のアラート]) の値が増加されます。このカウンタの更新値は 60 秒後の次のチェックポイントで処理されます。[サービスのモニタの詳細] ページには、アラート生成の約 1 分後の更新された数が表示されます。
午前 0 時をまたがるルールのアクティブな時間はどのようになりますか。
回答 : ルールのアクティブな時間が 22:00 ~ 09:00 と指定されている場合を考えてみましょう。
特定の日 (たとえば 6 月 7 日) に、ルールは以下のようにアクティブおよび非アクティブになります。
6 月 6 日午後 10 時 00 分から 6 月 7 日午前 9 時 00 分 - アクティブ
6 月 7 日午前 9 時 01 分から 6 月 7 日午後 9 時 59 分 - 非アクティブ
6 月 7 日午後 10 時 00 分から 6 月 8 日午前 9 時 00 分 - アクティブ
システムが 1 分ごとに受信するデータを集約するのをモニタすることにより、統計取得サブシステムがデータを使用できるようになります。統計コレクタのチェックポイント スレッドに対して、集約機能のスレッドは 25 秒の遅れがあります。
ドメインのモニタを無効にすると、そのドメインの統計の収集が無効になります。次の集約間隔以降はモニタ データは収集されません。つまり、データを取得しようとしても返されるデータがありません。ドメインのモニタを有効にした場合も同様です。最初はデータがまったく表示されませんが、最大 2 分後には、[サービス概要] ページにモニタの結果が表示されます。
AquaLogic Service Bus では、モニタ サブシステムは集約間隔中にメッセージ数や統計などの統計情報を収集します。集約間隔とは、統計データが収集され、AquaLogic Service Bus Console に表示されるまでの時間です。統計は、サンプル間隔と呼ばれる一定の間隔で再計算されます。そのため、集約間隔は、さまざまなサンプル間隔で構成されます。サンプル間隔の時間間隔は集約間隔によって異なります。ここでは、集約間隔の機能について説明します。
発注書を処理するためのプロキシ サービスをコンフィグレーションし、10 分の集約間隔をコンフィグレーションしたとします。システムで 10 分間のデータが収集されていないため、最初の 10 分が経過するまで、[サービス概要] ページには部分的に計算されたデータが表示されます。データ集約の最初の 10 分が経過した後は、常に直前 10 分間のデータが表示されます。たとえば、14 分経過した時点で、ダッシュボードには 4 ~ 14 分間のデータが表示されます。15 分経過以降メッセージが処理されていない場合、25 分経過した時点でサービスのデータは表示されなくなります。
サンプル間隔の期限が集約間隔を完了した場合に、特定の条件で、アラート ルールが発生することがあります。アラート ルールの集約間隔を更新したり、新しい集約間隔でアラート ルールを作成すると、新しい集約間隔がサービス、およびそのサービスに関連付けられた統計メトリックを持つアラート ルールに指定されている条件に設定されます。また、以前のアラート ルールに関連付けられた集約間隔の統計が新しいアラート ルールや更新されたアラート ルールに含まれている場合、新しいアラート ルールは統計を継承し、集約間隔のサンプル間隔が期限切れになるとアラート ルールが発生します。
たとえば、サービス s1 に、集約間隔を 10 分として条件 メッセージ数 > 10 でアラート ルール a1 を定義しているとします。この集約間隔のサンプル間隔は 5 分になります。サービスの統計はサンプル間隔ごとに収集され、集約間隔で集約されます。ここで、新しいアラート ルール a2 を作成し、集約間隔を 15 分として、条件は同じで メッセージ数 >10 のときにアラートが発生するようにします。新しい集約間隔のアラートは、t+15 分の時間間隔で発生する必要があります。ここで、t は新しい集約間隔を設定した時刻です。ただし、アラート ルール a1 の統計はすでに収集されているため、アラート ルール a2 のサンプル間隔が完了したときに、このアラート ルールが発生します。
集約間隔がモニタ情報の表示に与える影響の詳細については、「さまざまなリソースに関連付けられている統計」を参照してください。
作成したビジネス サービスまたはプロキシ サービスのモニタは明示的に有効にする必要があります。デフォルトでは、モニタは無効になります。モニタを有効にし、個々のサービスの集約間隔を設定した後、[システムの管理] モジュールの [グローバル設定] ページからこれらすべてのサービスのモニタを有効または無効にできます。詳細については、「グローバル レベルでの操作設定のコンフィグレーション」を参照してください。
実行時の [ダッシュボード] ページのデフォルトの更新間隔は 1 分です。ただし、情報がダッシュボードに表示されるまでに最大 3 分かかることがあります。このような遅延が発生するのは、プロキシ サービスがメッセージを処理した時間、メトリックが収集された時間、およびダッシュボードの更新間隔に時間のずれがあるためです。システムは次のように動作します。
たとえば、図 3-5 に示すように、プロキシ サービスが T1 でデータの送信を開始します。T2 (2 分目) で、統計コレクタがデータを集約機能に送信します。しかし、集約機能は、集約サイクルをすでに開始している場合は次の集約サイクルまでこのデータを結合しません。次のサイクルは、前の集約サイクルから 1 分後または最大 2 分後に始まります。データが結合されたら、AquaLogic Service Bus Console に表示できるようになります。コンソールは 1 分ごとに更新されるため、更新サイクルが直前に始まっていた場合、最大 3 分が経過するまでアラートはコンソールに表示されません。
デフォルトでは、ダッシュボードの更新間隔は 1 分に設定されていますが、この間隔を 2 分、3 分、4 分、5 分、10 分、20 分、または 30 分に設定できます。デフォルトでは、30 分間のアラート履歴データを表示できますが、このデータの表示を 1 時間、2 時間、3 時間、または 6 時間に設定できます。
ダッシュボードのポーリング間隔は、AquaLogic Service Bus Console の [操作] モジュールの [グローバル設定] で変更できます。この方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「ダッシュボードの設定の変更」を参照してください。
ダッシュボードには発生したすべてのアラートが表示されます。表示されるアラートは動的に更新されます。これらのアラートは、SLA 違反またはパイプライン アラートの結果として生成されます。サービス レベル アグリーメント (SLA) は、AquaLogic Service Bus のビジネス サービスとプロキシ サービスで想定される正確なサービス レベルを定義するアグリーメントです。一方、パイプライン アラートは、メッセージ パイプラインを通過するメッセージ数を記録したり、システムのヘルス状態以外のエラーをレポートするなど、業務上の目的でメッセージ フローに定義されています。テーブルの各行には、重大度、タイムスタンプ、関連サービスなど、コンフィグレーションした情報が表示されます。重大度のリンクをクリックすると、アラートの原因の分析に役立つアラートの詳細情報が表示されます。
この節は、AquaLogic Service Bus ダッシュボードに表示される情報を理解するのに役立ちます。ダッシュボードには、SLA アラートとパイプライン アラートに関する別々のビューが表示されます。
AquaLogic Service Bus Console にログオンすると、図 3-6 に示すように、デフォルトで SLA アラートのダッシュボードが表示されます。ダッシュボードには、[ダッシュボード設定] ページで設定したアラート履歴の期間でのモニタ情報が表示されます。サービス、サーバ、およびアラートで構成されるシステムの状態の概要が表示されます。
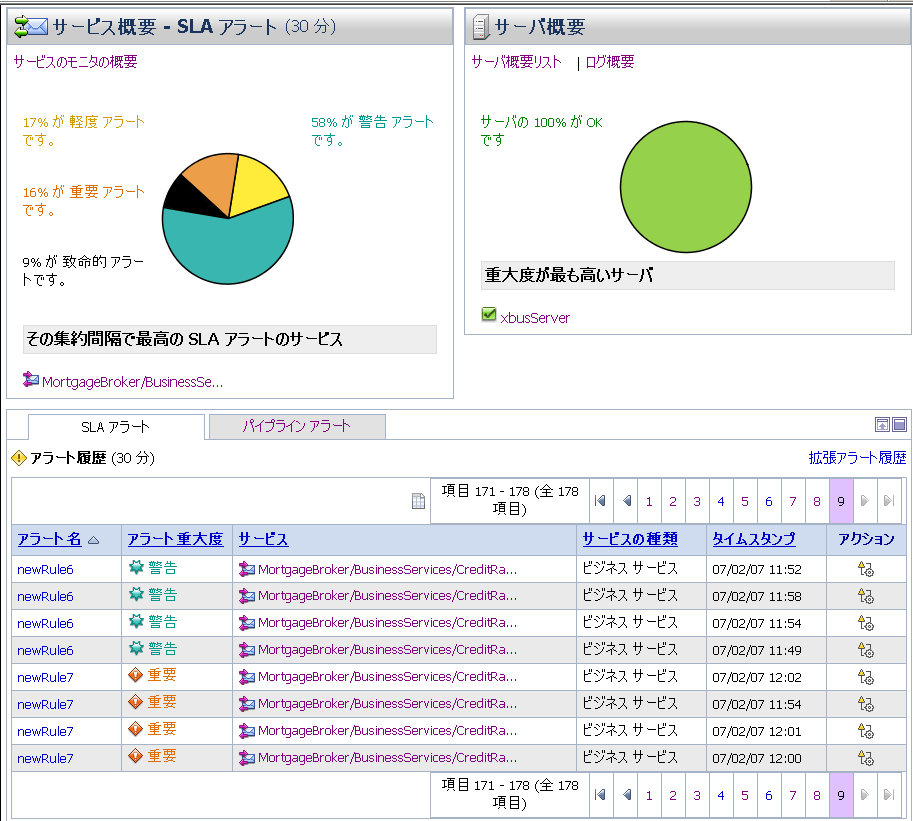
[サービス概要] パネルには、サービスの状態の概要が表示されます。[サービス概要] 円グラフには、[ダッシュボード設定] ページのアラート履歴で設定した期間で、SLA アラートの分布が重大度に応じて表示されます。アラートの重大度レベルはユーザがコンフィグレーションでき、絶対的な意味はありません。重大度のタイプには次のものがあります。
図 3-7 に示すように、最も多くのアラートを発生させたサービスが円グラフの下に表示されます。それぞれの現在の集約間隔でアラートの最も多いサービスから順に最大 10 個のサービスが表示されます。
![SLA アラートの [サービス概要] パネル](wwimages/service_summary_pane.gif)
[サービス概要] パネルから、次の部分をクリックして、アラートに関する詳細情報にアクセスできます。
| 警告 : | サービス (またはパイプライン ノードなどのコンポーネント) の名前を変更するか場所を移動すると、統計データは失われます。 |
詳細なアラート情報へのアクセス方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「ダッシュボードの統計の表示」を参照してください。
図 3-8 および図 3-9 に示すように、[サービスのモニタの概要] ページにはサービスのモニタ統計の 2 つのビューが表示されます。
1 つ目は、各サービスで収集された統計データの動的ビューです。このビューは、[統計の表示] フィールドで [現在の集約間隔] を選択すると表示されます。このビューに表示される集約間隔によって、表示される統計が決まります。たとえば、特定のサービスの集約間隔が 20 分である場合、そのサービスの行には直前 20 分間に収集されたデータが表示されます。このページから、すべてのサービスを表示したり、特定の条件に基づいてサービスを検索できます。このページの [現在の集約間隔] ビューに表示される統計の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サービスのメトリックの表示と検索」を参照してください。
![[サービスのモニタの概要] ページ - 現在の集約間隔](wwimages/service_summary_currentaggregationinterval.gif)
2 つ目のビューはメトリックの集計カウントです。このビューは、[統計の表示] フィールドで [最後のリセット以降] を選択すると表示されます。各行に表示される統計は、個々のサービスの統計を最後にリセットした時点、またはすべてのサービスの統計を最後にリセットした時点以降の統計です。このページから、すべてのサービスを表示したり、特定の条件に基づいてサービスを検索できます。選択したサービスまたはすべてのサービスについて統計をリセットすることもできます。このページの [最後のリセット以降] ビューに表示される統計の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サービスのメトリックの表示と検索」を参照してください。
![[サービスのモニタの概要] ページ - 最後のリセット以降](wwimages/service_summary_sincelastreset.gif)
図 3-10 および図 3-11 に示すように、[サービスのモニタの詳細] ページには、特定のサービスに関する詳細情報の 2 つのビューが表示されます。
1 つ目は、各サービスで収集された統計データの動的ビューです。このビューは、[統計の表示] フィールドで [現在の集約間隔] を選択すると表示されます。このビューに表示される集約間隔によって、表示される統計が決まります。たとえば、特定のサービスの集約間隔が 20 分である場合、そのサービスの行には直前 20 分間に収集されたデータが表示されます。このページから、すべてのサービスを表示したり、特定の条件に基づいてサービスを検索できます。このページの [現在の集約間隔] ビューに表示される統計の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サービスのメトリックの表示と検索」を参照してください。
![[サービスのモニタの詳細] ページ - 現在の集約間隔](wwimages/service_detail_currentaggregationinterval.gif)
![[サービスのモニタの詳細] ページ - 最後のリセット以降](wwimages/service_detail_sincelastreset.gif)
2 つ目のビューはメトリックの集計カウントです。このビューは、[統計の表示] フィールドで [最後のリセット以降] を選択すると表示されます。各行に表示される統計は、個々のサービスの統計を最後にリセットした時点、またはすべてのサービスの統計を最後にリセットした時点以降の統計です。このページから、すべてのサービスを表示したり、特定の条件に基づいてサービスを検索できます。このサービスの統計をリセットすることもできます。このページの [最後のリセット以降] ビューに表示される統計の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サービスのメトリックの表示と検索」を参照してください。
[サービスのモニタの詳細] ページの上記の各ビューには、次のタブがあります。
このパネルを使用すると、現在の集約間隔におけるアラートの状態およびサービスのサービス レベル統計をすばやく表示できます。最後のリセット以降の時間間隔でサービス レベル統計を表示する場合、最後のリセット以降に発生したアラートの総数が表示されます。このビューに表示されるメトリックの詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サービスのモニタの詳細の表示」を参照してください。
[SLA アラート] テーブルの [アラート履歴] (図 3-15 を参照) には、[ダッシュボード設定] ページで設定したアラート履歴の期間に発生したすべての SLA アラートが表示されます。以下の詳細情報が表示されます。
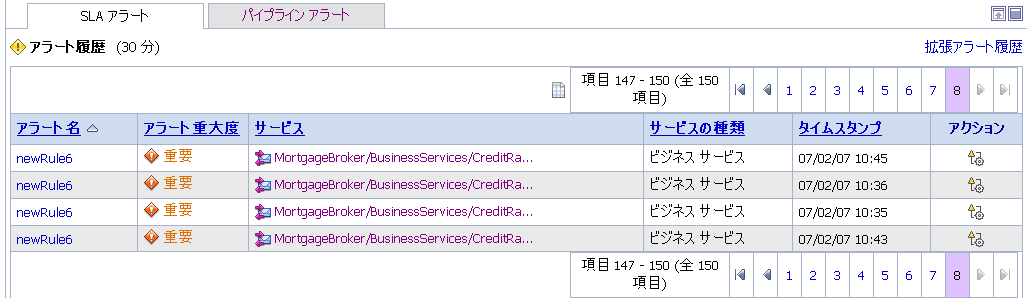
AM/PM の形式)。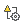 アイコンをクリックすると [アラート ルールの詳細の表示] に移動する。[アラート ルールの詳細の表示] ページの詳細については、「アラートの詳細の表示」を参照してください。
アイコンをクリックすると [アラート ルールの詳細の表示] に移動する。[アラート ルールの詳細の表示] ページの詳細については、「アラートの詳細の表示」を参照してください。
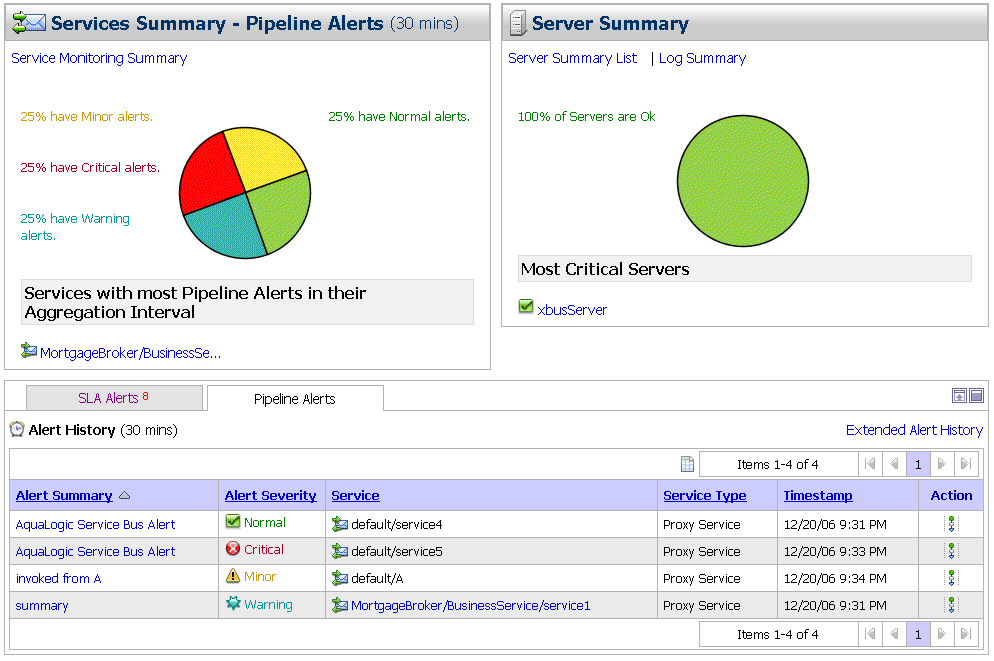
[アラート履歴] テーブルに表示される情報をカスタマイズするには、テーブルの上にある [テーブルのカスタマイズ]  アイコンをクリックします。図 3-21 に利用可能なフィルタを示します。[アラート履歴] テーブルのカスタマイズの詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「テーブルの表示のカスタマイズ」を参照してください。
アイコンをクリックします。図 3-21 に利用可能なフィルタを示します。[アラート履歴] テーブルのカスタマイズの詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「テーブルの表示のカスタマイズ」を参照してください。
アラートのリストを表示するには、[拡張アラート履歴] をクリックします。[拡張アラート履歴] の詳細については、「SLA アラートの拡張アラート履歴の表示」を参照してください。
SLA アラートの拡張アラート履歴のページには、ドメインで生成されたすべての SLA アラートに関する情報が表示されます。トリガされたすべてのアラートを表示したり、テーブルから特定のアラートを検索できます。[拡張 SLA アラート履歴] ページに表示されるデータの詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「アラートの表示と検索」を参照してください。

このページからアラートを削除したり、[アラート ルールの表示] ページに移動できます。[拡張 SLA アラート履歴フィルタ] ペインを使用すると、検索結果をフィルタできます。次の条件を使用してフィルタできます。
アラートの円グラフまたは棒グラフを表示するには、ページの [横棒グラフで表示] または [円グラフで表示] をクリックします。
また、必要な情報に応じてテーブルをカスタマイズできます。テーブルに表示される情報をカスタマイズするには、[テーブル カスタマイザ] アイコンをクリックします。[拡張 SLA アラート履歴] テーブルに表示される情報をカスタマイズするには、テーブル カスタマイザ (図 3-17 を参照) を使用する必要があります。

検索結果のカスタマイズの使用方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「アラートの表示のカスタマイズ」を参照してください。
AquaLogic Service Bus Console にログオンすると、デフォルトで SLA アラートのダッシュボードが表示されます。パイプライン アラートのダッシュボードを表示するには、[パイプライン アラート] をクリックします。ダッシュボードに直前 30 分間のモニタ情報が表示されます。図 3-18 に示すように、サーバ、サービス、およびパイプライン アラートで構成されるシステムの状態の概要が表示されます。
[サービス概要] パネル (図 3-19 を参照) には、重大度に基づいたアラートの分布が表示されます。
![パイプライン アラートの [サービス概要] パネル](wwimages/serviceSummary_pipelineAlerts.gif)
[サービス概要] パネルには、サービスの状態の概要が表示されます。[サービス概要] 円グラフには、[ダッシュボード設定] ページで設定したアラート履歴の期間でのすべてのサービスについて、重大度に応じてパイプライン アラートの割合が表示されます。アラートの重大度レベルはユーザがコンフィグレーションでき、絶対的な意味はありません。重大度のタイプには次のものがあります。
図 3-19 に示すように、最も多くのアラートを発生させたサービスが円グラフの下に表示されます。アラートの最も多いサービスから順に最大 10 個のサービスが表示されます。
[サービス概要] パネルから、次の部分をクリックして、アラートに関する詳細情報にアクセスできます。
| 警告 : | サービス (またはパイプライン ノードなどのコンポーネント) の名前を変更するか場所を移動すると、統計データは失われます。 |
詳細なアラート情報へのアクセス方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「ダッシュボードの統計の表示」を参照してください。
パイプライン アラートのアラート履歴 (図 3-20 を参照) には、[ダッシュボード設定] ページで設定した最後のアラート履歴期間にトリガされたパイプライン アラートの詳細が表示されます。以下の詳細情報が表示されます。
AM/PMの形式) です。![パイプライン アラートの [サービス概要] パネル](wwimages/pipelineicon.gif) アイコンをクリックしてメッセージ フローを編集します。
アイコンをクリックしてメッセージ フローを編集します。
アラートのリストを表示するには、[拡張アラート履歴] をクリックします。[拡張アラート履歴] の詳細については、「パイプライン アラートの拡張アラート履歴」を参照してください。
[アラート履歴] テーブルに表示される情報をカスタマイズするには、テーブルの上にある [テーブルのカスタマイズ] アイコンをクリックします。図 3-21 に利用可能なフィルタを示します。
表示するアラートのソート順序をカスタマイズするには、カラム ヘッダの横のソート アイコンをクリックします。
パイプライン アラートの [拡張アラート履歴] ページには、ドメインで生成されたすべてのパイプライン アラートに関する情報が表示されます。トリガされたすべてのアラートを表示したり、テーブルから特定のアラートを検索できます。詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「アラートの表示と検索」を参照してください。
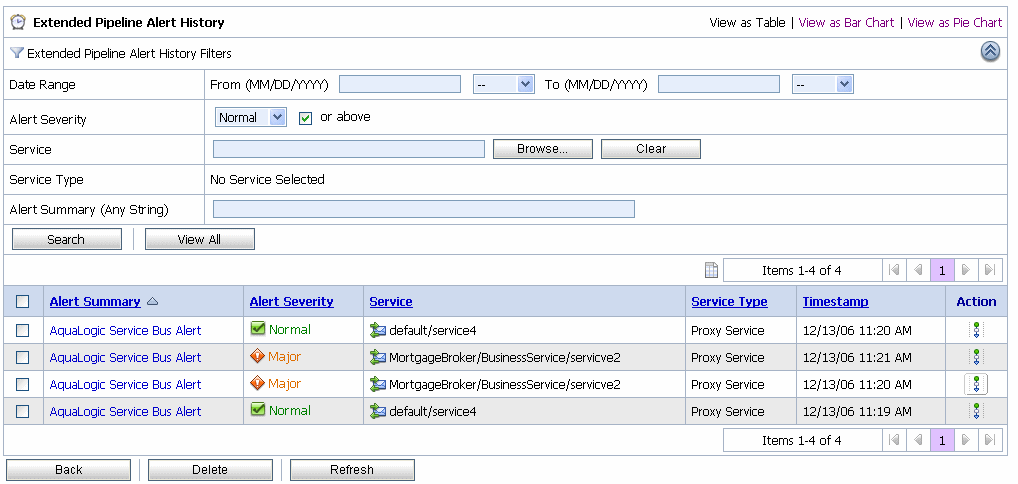
[拡張 SLA アラート履歴フィルタ] ペインを使用すると、検索結果をフィルタできます。次の条件を使用してフィルタできます。
アラートの円グラフまたは棒グラフを表示するには、ページの [横棒グラフで表示] または [円グラフで表示] をクリックします。
必要な情報に応じて、テーブルをカスタマイズすることもできます。テーブルに表示される情報をカスタマイズするには、[テーブル カスタマイザ] アイコンをクリックします。[拡張パイプライン アラート履歴] テーブルに表示される情報をカスタマイズするには、テーブル カスタマイザ (図 3-17 を参照) を使用する必要があります。詳細については、以下を参照してください。
[サーバ概要] パネルには、ドメインに関連付けられているすべてのサーバの状態が表示されます。サーバの状態の概要が表示されます。円グラフには、ドメインの各サーバの状態が示されます。各サーバの状態は WebLogic 診断サービスから派生します。図 3-23 に示すように、重大度が最も高い 5 個のサーバが表示されます。
| 注意 : | [サーバ概要] パネルは、ダッシュボードの SLA アラート ビューとパイプライン アラート ビューの両方に共通です。 |
WebLogic 診断サービスの詳細については、『WebLogic 診断フレームワークのコンフィグレーションと使い方』を参照してください。
![[サーバ概要] パネル](wwimages/server_summary_pane.gif)
致命的] - サーバに障害が発生し、サーバを再起動する必要があります。重大] - サーバに障害が発生しようとしています。障害を防ぐために何らかの措置をすぐに講じる必要があります。詳細については、サーバ ログと対応する RuntimeMBean を確認してください。警告] - 将来的にサーバに障害が発生する可能性があります。詳細については、サーバ ログと対応する RuntimeMBean を確認してください。OK] - サーバは障害なしで稼働しています。オーバーロード] - 設定されたしきい値を上回る処理がサーバに割り当てられています。これ以上の負荷は拒否される可能性があります。
[ログ概要] ページには、ドメインに関連付けられているサーバの概要ログが表示されます。ドメイン ログ ファイルは、ドメイン全体のステータスを確認するための中心となるファイルです。各サーバ インスタンスでは、メッセージのサブセットをドメイン全体のログ ファイルに転送します。デフォルトでは、重大度が注意以上のメッセージのみが転送されます。転送されるメッセージの集合を変更できます。詳細については、『ログ ファイルのコンフィグレーションとログ メッセージのフィルタ処理』の「WebLogic ロギング サービスについて」を参照してください。
パイプラインにロギング アクションをコンフィグレーションした場合、ログはサーバ ログに転送されます。これらのメッセージをドメイン ログに転送するよう WebLogic Server をコンフィグレーションしていない限り、AquaLogic Service Bus Console からこのログは表示できません。この方法については、WebLogic Server Administration Console オンライン ヘルプの「ログ フィルタの作成」を参照してください。
システムで現在発生しているメッセージの数を調べるには、[サーバ概要] パネルの [ログ概要の表示] リンクをクリックします。図 3-24 に示すように、重大度別に分類されたメッセージ数を示すテーブルが表示されます。
| 注意 : | ログ概要は、WebLogic Server Console で管理者権限を持っている場合にのみ表示できます。 |

これは、WebLogic 診断サービスでの定義に従い、実行中のサーバのヘルス状態に基づいて表示されます。WebLogic 診断サービスの詳細については、『WebLogic 診断フレームワークのコンフィグレーションと使い方』を参照してください。
特定のタイプのメッセージのドメイン ログを表示するには、そのメッセージのタイプに対応している数字をクリックします。図 3-25 に、AquaLogic Service Bus Console に表示されるドメイン ログ ファイルの例を示します。
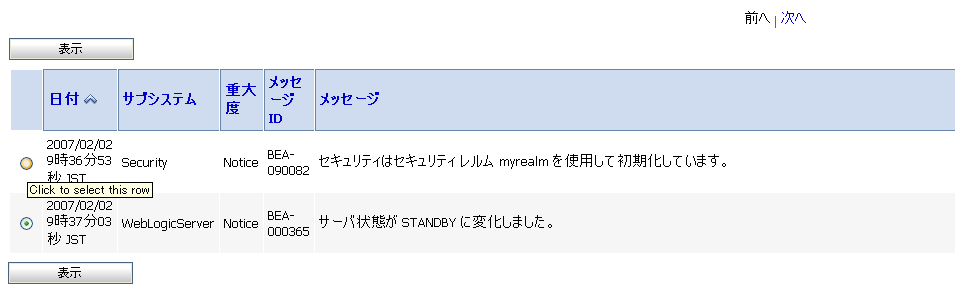
詳細については、『ログ ファイルのコンフィグレーションとログ メッセージのフィルタ処理』の「WebLogic ロギング サービスについて」にある「メッセージの属性」参照してください。
ページにある 1 つのログ ファイルの詳細を表示するには、該当するログを選択し、[表示] をクリックします。[ドメイン ログ ファイル エントリ] テーブルをカスタマイズして、次の情報を表示することもできます。
これらの情報の詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」にあるサーバ ログ ファイルの詳細の表示に関する説明を参照してください。[ドメイン ログ ファイル エントリ] テーブルのカスタマイズ方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にあるドメイン ログ ファイル エントリの表示のカスタマイズに関する説明を参照してください。
図 3-26 に示すように、[サーバ概要] ページには、サーバのカスタマイズ可能なテーブルが表示されます。
![[サーバ概要] ページ](wwimages/server_summary_table.gif)
図 3-26 に示すように、[サーバ概要] ページの上部には、システムで現在発生しているメッセージの数が表示されます。それぞれのタイプの状態メッセージについては、「ログ概要について」を参照してください。
ヘルス] - サーバのヘルス状態です。 致命的] - サーバに障害が発生し、サーバを再起動する必要があります。重大] - サーバに障害が発生しようとしています。障害を防ぐために何らかの措置をすぐに講じる必要があります。詳細については、サーバ ログと対応する RuntimeMBean を確認してください。警告] - 将来的にサーバに障害が発生する可能性があります。詳細については、サーバ ログと対応する RuntimeMBean を確認してください。OK] - サーバは障害なしで稼働しています。オーバーロード] - 設定されたしきい値を上回る処理がサーバに割り当てられています。これ以上の負荷をかけることはできません。| 注意 : | 複数の状態値に基づいて結果をフィルタするには、その状態に関連付けられているチェック ボックスをクリックします。 |
テーブルのこの情報を円グラフまたは棒グラフで表示するには、[横棒グラフで表示] または [円グラフで表示] をクリックします。
サーバの表示をフィルタするには、サーバ テーブルの上の [テーブルのカスタマイズ] をクリックします。図 3-27 に利用可能なフィルタを示します。
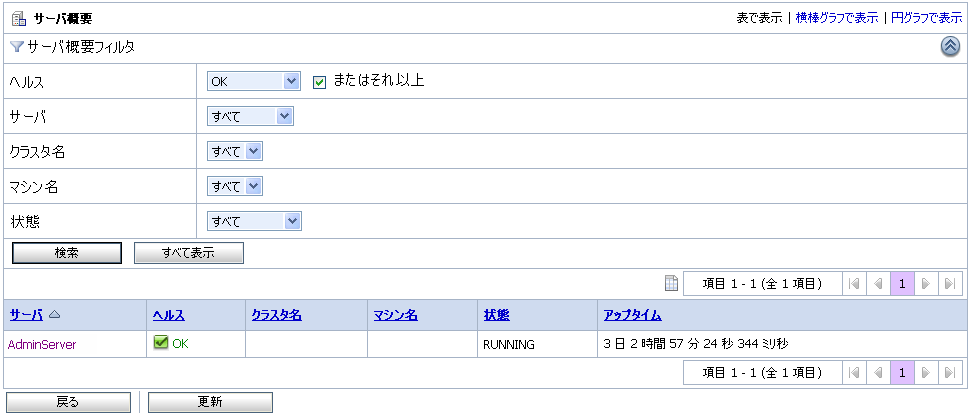
サーバ概要テーブル フィルタの使用方法については、『AquaLogic Service Bus Console の使い方』の「モニタ」にある「サーバ概要の表示のカスタマイズ」を参照してください。
[サーバの詳細表示] ページにアクセスするには、[重大度が最も高いサーバ] の下のサーバ名をクリックするか、[サーバ概要] ページでサーバ名をクリックします。
[サーバの詳細表示] ページを使用すると、図 3-28 に示すように、サーバ モニタの詳細を表示できます。
![サーバの詳細ページ - [全般] タブ](wwimages/server_details.gif)
このページに表示される情報は、WebLogic Server Administration Console のサーバの設定ページの [モニタ] タブのサブセットです。以下の詳細情報が表示されます。
詳細については、WebLogic Server Administration Console オンライン ヘルプを参照してください。
ダッシュボードから、サービスの平均実行時間、アラートの発生日時、サーバの実行時間など、システム固有の詳細な情報を容易に取得できます。
ダッシュボードとモニタは AquaLogic Service Bus Console でコンフィグレーションします。詳細については、『AquaLogic Service Bus Console の使い方』の「モニタ」を参照してください。
以下の節では、AquaLogic Service Bus Console でメッセージおよびシステムの処理をモニタする際に使用できるツールと機能について説明します。内容は次のとおりです。
ビジネス サービスまたはプロキシ サービスを作成した場合、そのサービスのモニタはデフォルトでは無効です。この節の内容は以下のとおりです。
個々のサービスの操作設定は、[プロキシ サービスの表示] ページ (図 3-29 を参照) または [ビジネス サービスの表示] ページ (図 3-30 を参照) で [操作設定] ビューから有効または無効にできます。
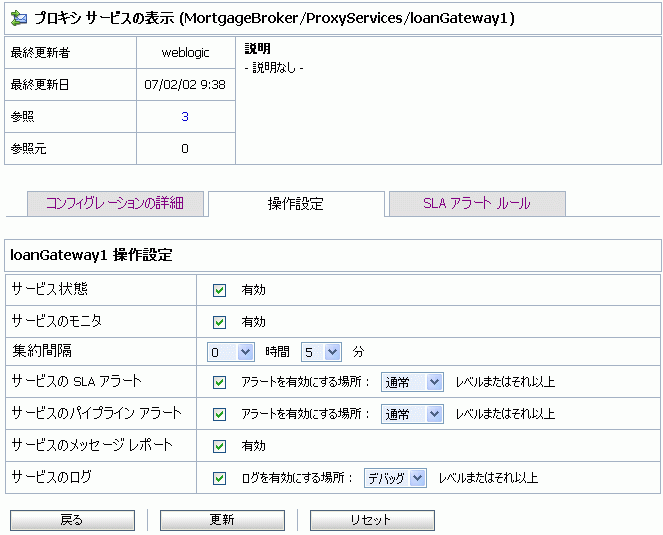

[プロキシ サービスの表示] ページおよび [ビジネス サービスの表示] ページには、プロキシ サービスまたはビジネス サービスの関する以下の情報が表示されます。
ルールの条件が一致するたびに、その重大度以上のすべてのアラートが発生します。
プロキシ サービスについてのみ、以下の設定を有効または無効にできます。
[グローバル設定] ページには [操作] モジュールからアクセスできます。[グローバル設定] ページ (図 3-31 を参照) を使用すると、サービスに以下の操作設定をコンフィグレーションできます。
| 注意 : |
モニタ統計により、特定のサービスで正常に処理されたメッセージと処理に失敗したメッセージの数を把握できます。この情報を調べるには、ダッシュボードで [サービスのモニタの概要] ページにアクセスし、表示をフィルタして該当するサービスを検索します。正常に処理されたメッセージまたは処理に失敗したメッセージの数を表示するだけでなく、サービスが属するプロジェクト、メッセージ処理の平均実行時間、およびサービスに関連するアラートの数を表示することもできます。現在の集約間隔のモニタ統計を表示できます。また、このサービスの統計を最後にリセットした時点、またはすべてのサービスの統計を最後にリセットした時点以降の期間のモニタ統計を表示できます。
統計をリセットするには、[サービスのモニタの概要] ページまたは [サービスのモニタの詳細] ページで [統計の表示] を [最後のリセット以降] に設定します。
| 注意 : | 統計をリセットするときは、WebLogic Server Administration Console の WebLogic セッション内で作業していないことを確認してください。 |
サービスの名前をクリックすると、そのサービスの [サービスのモニタの詳細] ページが表示されます。このページには、最小/最大応答時間およびサービスでのメッセージの実行にかかる全体の平均時間、成功と失敗の割合、セキュリティまたは検証のエラーのために失敗したメッセージの数、プロキシ サービス コンポーネント (パイプラインとルート ノード) に関連するメッセージの数などの情報が表示されます。サービスに関連付けられている特定のオペレーションの情報を表示できます。前述の場合と同様に、現在の集約間隔でのこれらの統計を表示できます。また、このサービスの統計を最後にリセットした時点、もしくは、すべてのサービスの統計を最後にリセットした時点からの期間の統計を表示できます。
ビジネス サービス操作の統計情報を [サービスのモニタの詳細] ページに表示するには、ビジネス サービスにメッセージをルーティングするプロキシ サービスのルート ノードで呼び出される操作の名前を指定する必要があります。たとえば、操作 C では、プロキシ サービス A がビジネス サービス B にメッセージをルーティングするとします。AquaLogic Service Bus のバインディング レイヤおよび転送レイヤで操作が呼び出されたことが認識された場合のみ、ビジネス サービス B の [サービスのモニタの詳細] ページで、[サービスのモニタの概要] ページとともに操作 C のメッセージ数が増加するようにします。これは以下のいずれかの方法で行います。
プロキシ サービスのルート ノードで操作の名前を指定しないと、AquaLogic Service Bus のバインディング レイヤおよび転送レイヤでは、操作が呼び出されたことを認識できません。そのため、[サービスのモニタの詳細] ページでは、オペレーション C のメトリックが [サービスのモニタの概要] ページとともには増加せず、ビジネス サービス B に送信されたメッセージ数を示すよう増加します。
次の節では、以下に関連付けられているさまざまな統計について説明します。
サービスには、AquaLogic Service Bus のサービス ディレクトリに登録された着信エンドポイントまたは発信エンドポイントがあります。このようなサービスは、WSDL などのその他のリソースやセキュリティ設定に関連付けられています。表 3-1 に、このリソースのタイプについてレポートされる統計を示します。また、統計のタイプも示しています。
パイプラインペア ノードとルート ノードという 2 つのタイプの FLOW_COMPONENT の統計が収集されます。パイプラインペア ノードとルート ノードの詳細については、AquaLogic Service Bus ユーザーズ ガイドの「AquaLogic Service Bus でのメッセージ フローの作成」にある「メッセージ フローの構築」を参照してください。表 3-2 に FLOW_COMPONENT についてレポートされる統計を示します。
WSDL などの WEBSERVICE_OPERATION リソースに関する統計が収集され、ランタイム XML ファイルに格納されます。表 3-3 に、このリソースのタイプについてレポートされる統計を示します。
監査により AquaLogic Service Bus のコンフィグレーションでの変更を追跡できます。
ここでは、実行できる次の 3 つのタイプの監査について簡単に説明します。
AquaLogic Service Bus Console でコンフィグレーションの変更を実行すると、追跡記録が作成され、コンフィグレーションの変更の履歴が保持されます。以前のオブジェクトのイメージのみが保持されます。コンソールを介してセッション中に変更されたコンフィグレーションの変更の履歴とリソースのリストを表示したり、これらにアクセスしたりできます。ただし、コンフィグレーションのすべての情報にアクセスするには、セッションをアクティブ化する必要があります。
実行中にメッセージ フローのパイプライン全体を監査するのは時間がかかります。ただし、レポート アクションを使用すると、実行中のメッセージ フローのパイプラインの監査を選択して実行できます。メッセージ フローのパイプラインの必要なポイントにレポート アクションを挿入し、必要な情報を抽出します。抽出された情報は、データベースに格納するか、監査レポートを作成するためにレポート ストリームに送信することができます。
メッセージがプロキシ サービスに送信され、転送レベルの認証または Web サービスのセキュリティの違反があった場合、WebLogic Server は監査トレイルを生成します。この監査トレイルを生成するには、WebLogic Server をコンフィグレーションする必要があります。これにより、メッセージ フローのパイプラインで発生するすべてのセキュリティ違反を監査できます。また、ユーザを認証するたびに監査トレイルが生成されます。セキュリティ監査の詳細については、AquaLogic Service Bus のセキュリティ ガイドの「WebLogic Security フレームワークのコンフィグレーション : 主な手順」を参照してください。
 
|
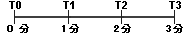
![ビジネス サービスの [サービスのモニタの詳細] ページ - [サービスのメトリック] ビュー](wwimages/servicemetrics.gif)
![[サービスのモニタの詳細] ページ - [操作] ビュー](wwimages/operations.gif)
![[サービスのモニタの詳細] ページ - プロキシ サービスの [フロー コンポーネント] ビュー](wwimages/flowComponents.gif)

![[グローバル設定] ページ](wwimages/global_settings.gif)