Setting up the import of data with Amazon Web Services (AWS)
Setting up the import of data with Amazon Web Services involves doing the following:
Learn more about correctly formatting source files and ingest jobs so that you can successfully import data:
-
Ensure source files are formatted correctly by reviewing CSV file standards for Oracle Unity and supported CSV parsers.
-
Review how to import empty or null data and the restrictions on empty/null data in the Oracle Unity data model.
Create the AWS source
To set up the data import, you will first need to create an AWS source, which provides all the details that Oracle Unity needs to run the ingest job and import data.
To create the AWS source:
-
Click the Oracle icon
 in the bottom-right corner to open the navigation menu.
in the bottom-right corner to open the navigation menu.
- Select Sources.
- In the top-right corner, click Create source.
Step 1: Define source details
The job details section allows you to define the type of source and how it will display in Oracle Unity.
Enter the information for the source.
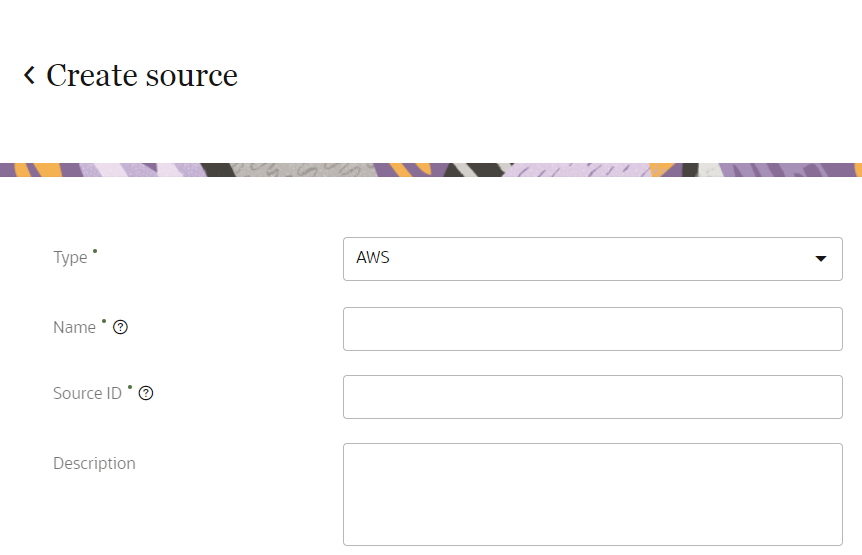
- Type: Use the drop-down list to select AWS.
- Name: Enter a name. The name must be 1 or more characters, up to a maximum of 50. Use only letters (a–z and A–Z), numbers (0–9), underscores (_), hyphens (-), and spaces. The first character cannot be a space.
- Source ID: When Oracle Unity ingests data using this source, it uses this value for the Source ID attribute of each object. The Source ID is auto-populated from the source name you enter. You can't change this value after you create the source.
- Description: Enter a description. This field is optional, but it is highly recommended to add descriptions for any entity created. This helps all other users get additional context when using and navigating Oracle Unity. The description can have a maximum of 512 characters with no restrictions on characters used. You can use characters from all languages supported in the language settings.
Step 2: Configure authentication settings
Enter the information to allow Oracle Unityto access the required data from AWS.
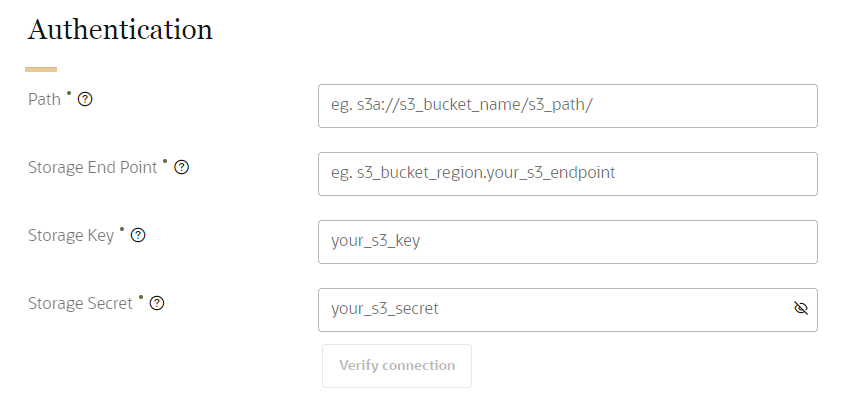
- Path: Enter the path of the folder on AWS that contains the data files to import in this format: s3a://[s3_bucket name]/[s3_path].
- Storage End Point: Enter the AWS region and endpoint in this format: s3_bucket_region.your_s3_endpoint. Learn more about Amazon Simple Storage Service endpoints and quotas from the AWS documentation.
- Storage Key: Enter the AWS storage key. Learn more about Creating object key names and Working with metadata from the AWS documentation.
- Storage Secret: Enter the AWS storage secret. Learn how to Create and retrieve a secret from the AWS documentation.
Once you enter all the details, click Verify connection to ensure that Oracle Unity can access the server. If there are connection issues, confirm the server path and authentication settings entered are correct.
Step 3: Configure files
The files details section defines the format of the source files.
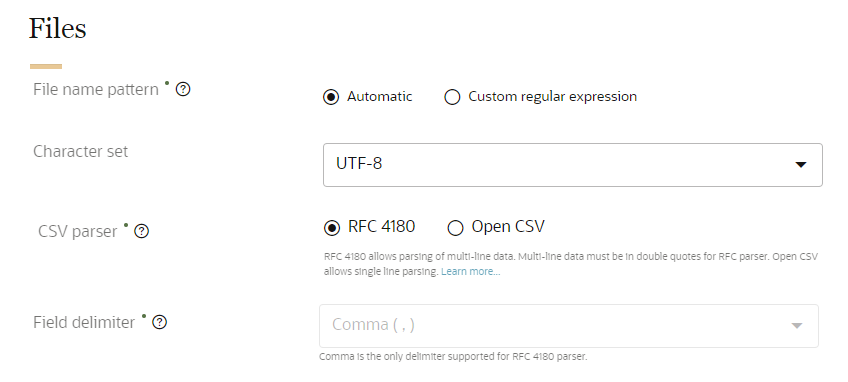
File name pattern
Please keep the following in mind for the file name pattern.
- The file name pattern defines what files Oracle Unity will import.
- If your source files use the file creation date as a prefix or suffix, select the correct timestamp format.
- If the source file is compressed, you have the option of using the following file extensions: .gz, .zip, and .gpg. You can also combine multiple compressed file types within a gpg archive.
- You can choose to define the following file name pattern formats: Automatic or Custom regular expression.
- Unless you want to define specific files for import, we recommend using an Automatic file name pattern. This allows Oracle Unity to automatically identify the appropriate files.
- The file name you define for Custom regular expression is case sensitive. If you select an Automatic file name pattern, the source object name you define when configuring the ingest job is case sensitive as well.
- Make sure that the name you give the Source object when configuring the ingest job allows the correct files to be imported. For example, to import address data, include "address" in the source object name.
To define an automatic file name pattern:
- Select Automatic.
When you select Automatic, Oracle Unity will do the following:
- Create a file name pattern based on the source object names in the ingest job configuration.
- Include files with a prefix or suffix in the file name pattern matching criteria.
- If there are compressed files (.gz, .zip, or .gpg), the appropriate extensions will be included in the file name pattern matching criteria.
- Match and import files that meet the matching criteria for the source object names in the ingest job configuration.
To enter the file name pattern in Custom regular expression:
- Select Custom regular expression.
- In the text field enter the regular expression so that Oracle Unity can search for and find the correct files to import.
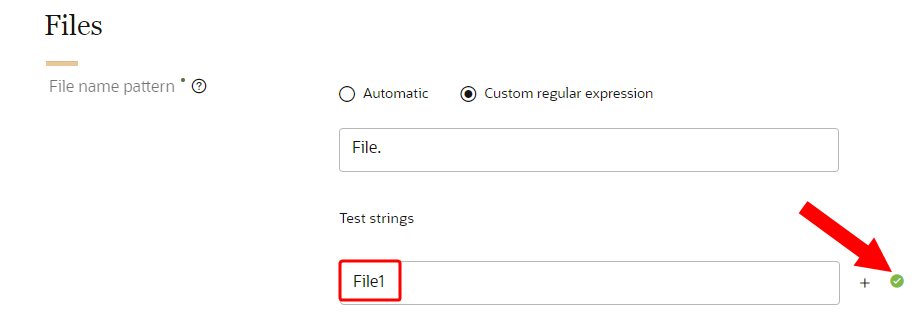
- Under Test strings, enter a sample file name to ensure that the regular expression is valid. A checkmark will display to show the test string is valid.
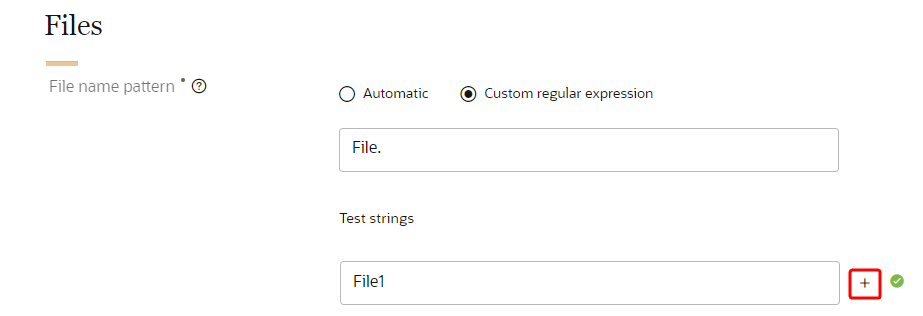
- To enter additional test strings, click Add
 . You can enter up to 10 test strings for validation.
. You can enter up to 10 test strings for validation.
Character set
Select the format of the character set for the source file. The following character sets are supported: UTF-8, ISO-8859-1, Windows-1251, and Windows-1252.
CSV parser
Select the type of CSV parser for the source: RFC 4180 or Open CSV. Learn more about CSV file standards.
-
RFC 4180 allows parsing of single-line and multi-line data. Learn more about the RFC 4180 parser.
-
Open CSV only allows parsing of single-line data. Learn more about the Open CSV parser.
Field delimiter
The field delimiter is the character in the source files that divides the fields. If you select the RFC 4180 parser, the comma (,) delimiter must be selected.
If you select the Open CSV parser, you can select one of the available characters (comma (,), semi-colon (;), pipe (|), or tab) or enter a custom delimiter.
When entering a custom delimiter, keep the following in mind:
- You cannot use the backward slash or double quote characters.
- You must use a single character. You cannot enter multiple characters for the delimiter.
Step 4: Save and publish the new source
When finished defining the source, scroll to the top of the page and click Save or Save and close.
Once you create the source, you will need to publish the changes.
After creating and publishing the source, you can create the ingest job.
Create the ingest job
You can now create the ingest job that will use the AWS source to transfer the data.
To create the ingest job:
-
Click the Oracle icon in the bottom-right corner to open the navigation menu.
- Select Data feeds.
- In the top-right corner, click Create data feed, then select Ingest job.
The Create ingest job page is displayed.
Step 1: Define job details
The job details section allows you to define how the ingest job will display in Oracle Unity.
To define the job details:
- Enter the details for the ingest job.
- Name: Enter a name. The name must be 1 or more characters, up to a maximum of 50. Use only letters (a–z and A–Z), numbers (0–9), underscores (_), hyphens (-), and spaces. The first character cannot be a space.
- Job ID: The Job ID field is auto-populated from the job name you enter. You can change this value before the job is created.
- Description: Enter a description. This field is optional, but it is highly recommended to add descriptions for any entity created. This helps all other users get additional context when using and navigating Oracle Unity. The description can have a maximum of 512 characters with no restrictions on characters used. You can use characters from all languages supported in the language settings.
- Source: Select the AWS source you created previously. Review the server and files details and make sure they are accurate.
- Once you have confirmed that the details are correctly configured, click Continue.
Step 2: Field mapping
Field mapping allows you to define how fields from your source files are mapped to the attributes in the data model.
To set up field mapping, you will need to do the following:
- Create a source object
- Add a sample file of the source fields
To create a source object:
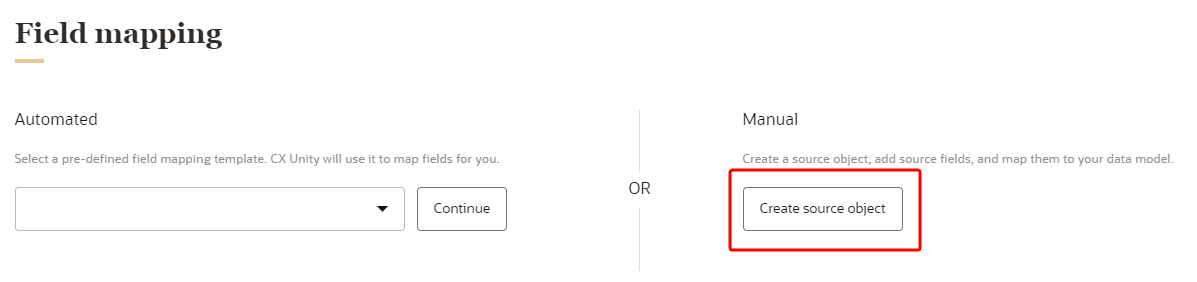
- Under Manual, click Create source object.
- Enter a name for the source object. The name must be 1 or more characters, up to a maximum of 50. Other than underscores (_) and hyphens (-), special characters are not allowed. The first character must be a valid letter. You can use characters from all languages supported in the language settings.
Note: Do not select an automated field mapping template.
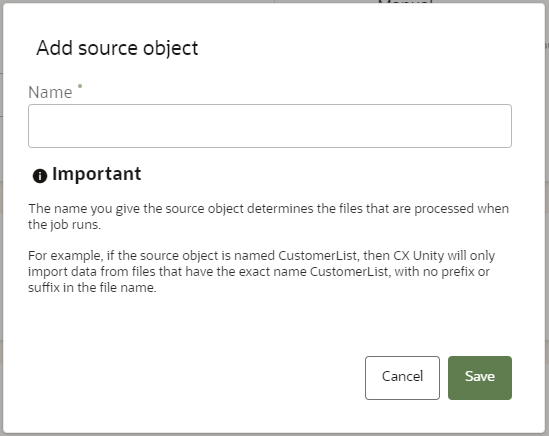
Important: The name you give the source object will determine the files that are processed when the job runs. For example, to import address data, make sure to include "address" in the source object name so that all files with "address" in the file name will be identified for import. If you select an Automatic file name pattern when configuring the source, Oracle Unity will use the source object name to create the file name pattern. Oracle Unity will include compressed files as well as files with a prefix or suffix when matching and importing files. Please be aware that the source object name you define is case sensitive.
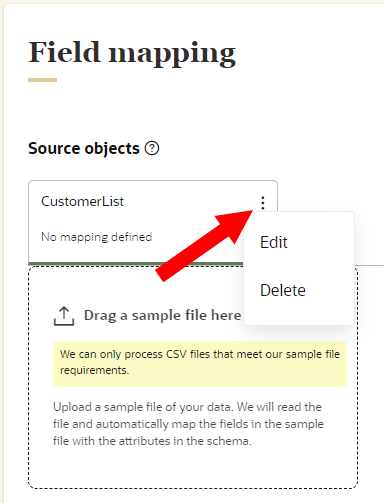
If needed, you can edit or delete the source object. If you delete a source object, all field mappings configured for the source object will be deleted as well.
To edit or delete the source object:
- Next to the source object name, click the Action menu (
 ).
). - Select Edit or Delete.
To complete manual field mapping, prepare a sample file that meets the following requirements:
- The sample file is in CSV or TXT format.
- The delimiter defined in the custom regular expression for the source file matches the delimiter in the sample file.
- The sample file is less than 100MB.
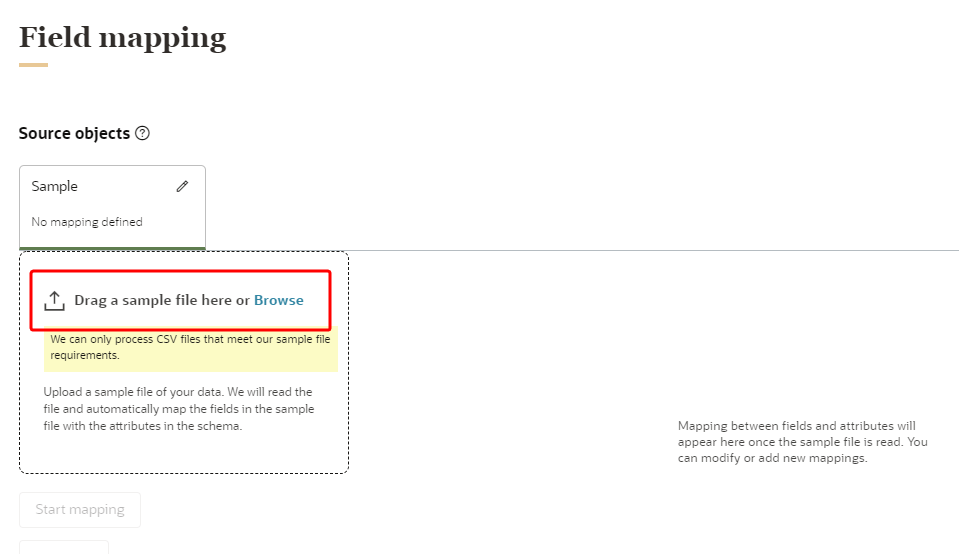
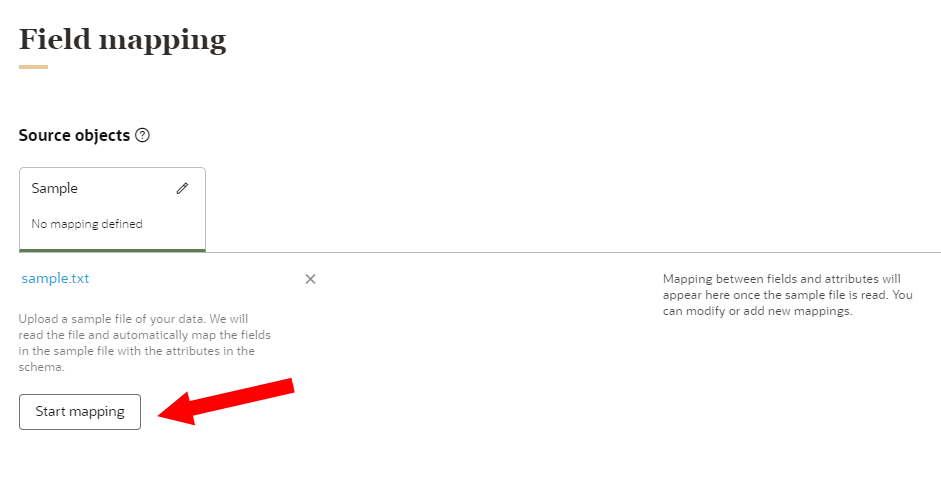
To add a sample file:
- Drag the sample file to the sample file section or click Browse and select the file on your computer. You have the option of adding sample values to the fields.
- Click Start mapping.
- Follow the steps below to start mapping source object fields to data model attributes.
Mapping source object fields to data model attributes
Notes: You cannot access or search for hidden data objects and attributes for field mapping. Learn more about Hidden data model items in ingest jobs.
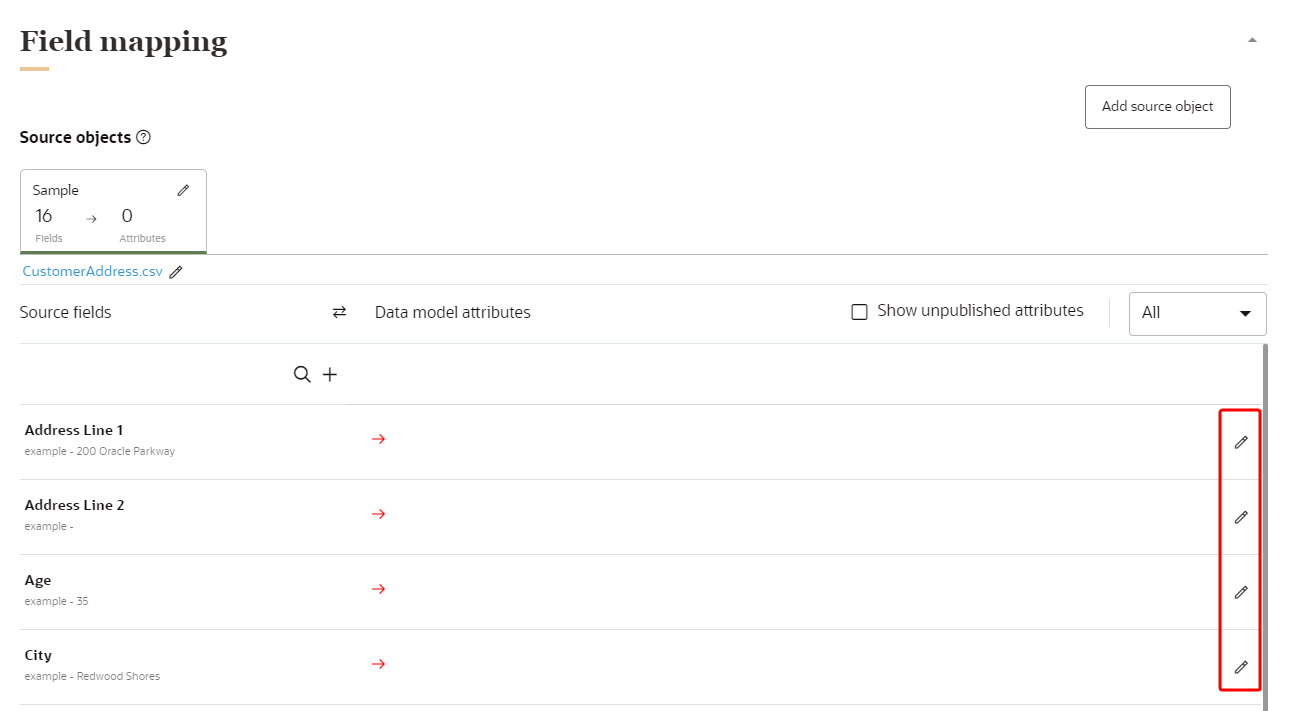
To map source object fields to data model attributes:
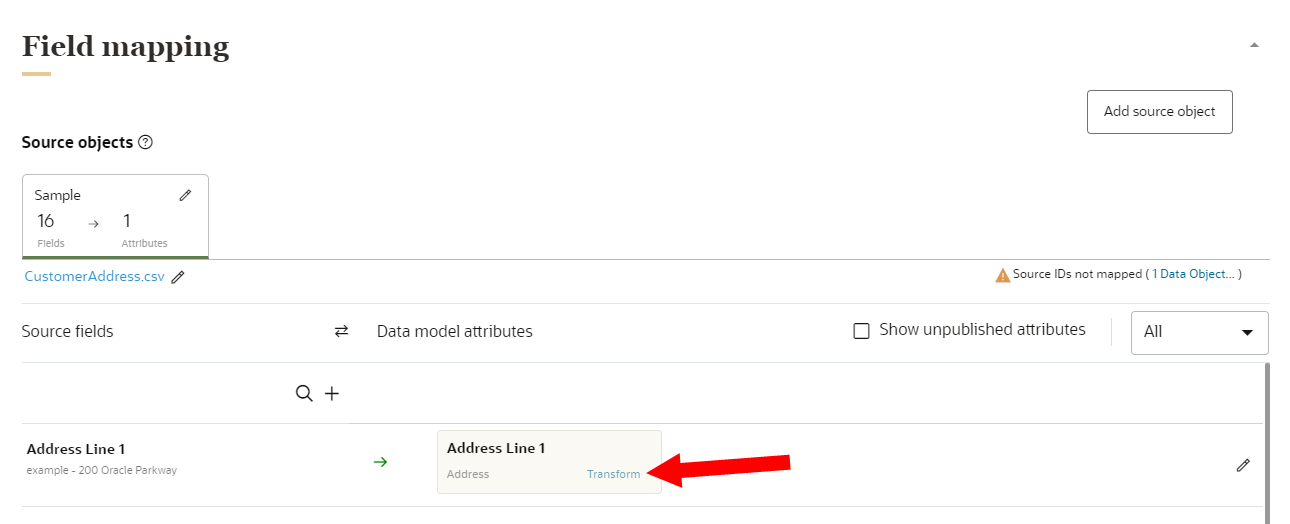
- For each of the mapped source fields, click Edit
 to start adding attributes from the data model.
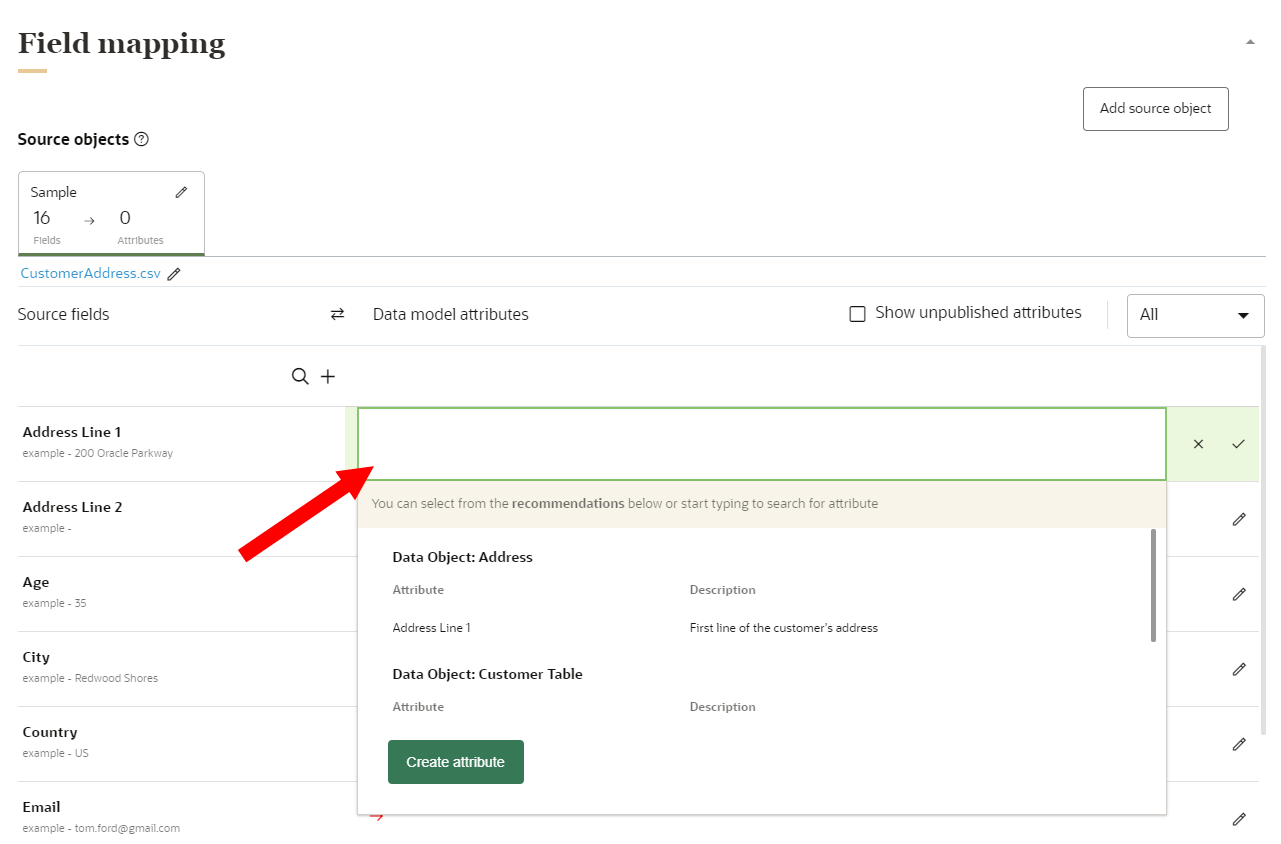
to start adding attributes from the data model. - A list of recommended attributes may display for you to add. You can also use the search field to find attributes to add. You can search by data object name, attribute name, or attribute description.
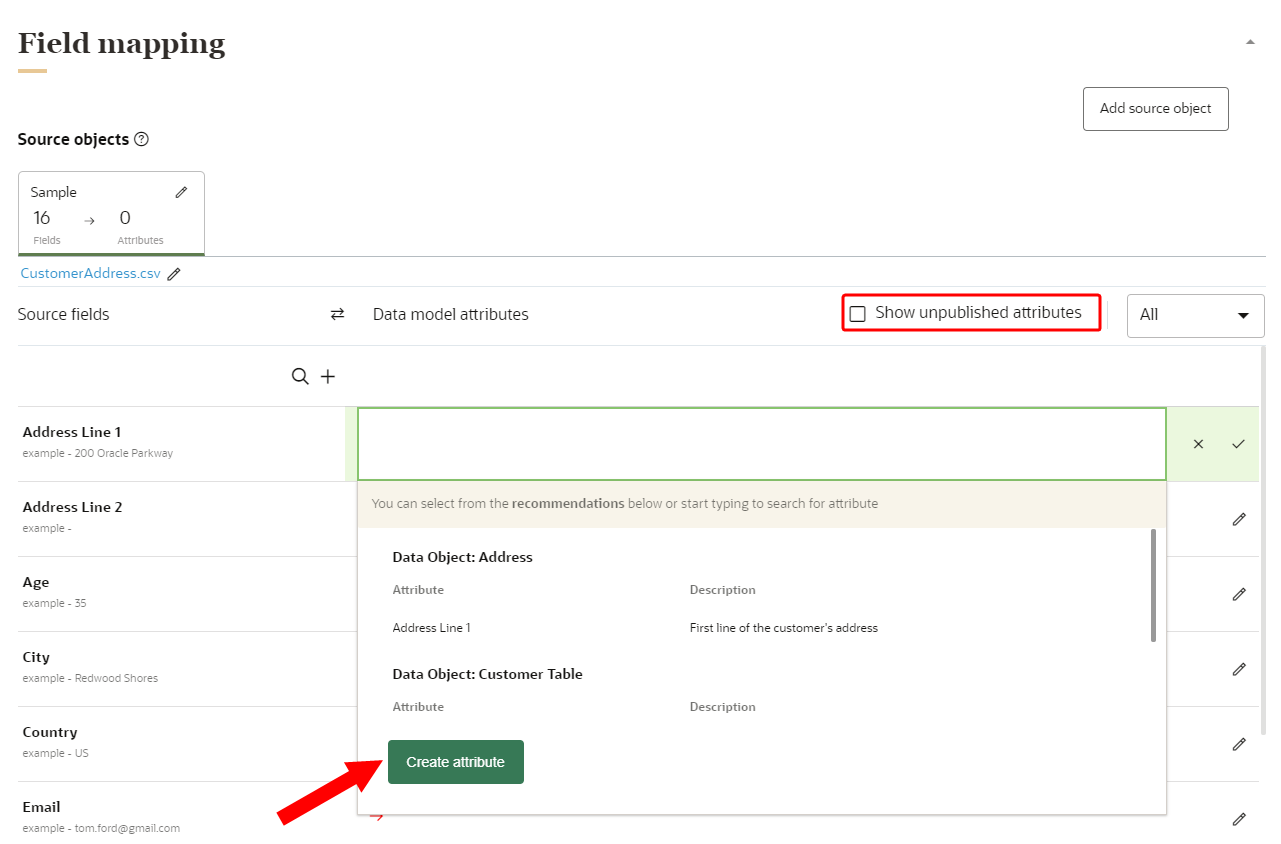
- If you need to add an attribute that is not currently part of the data model, click Create attribute. Attributes you create will need to be published before the ingest job runs. You can review attributes that need to be published by clicking the checkbox for Show unpublished attributes. Learn more about Creating attributes and Publishing changes.
- To add the attribute, click the Checkmark
 .
. - To add a transformation on an attribute, click Transform.
- Concatenation transformation
- Date transformation
- Lookup/static transformation
- URL transformation
- Hash transformation
- Prefix-Suffix transformation
- Replace transformation
- Substring transformation
- Trim transformation
- To add another source object to be mapped, click Add source object.
Learn more about the different transformations available:
Important notes about configuring field mapping
-
A single source field can be mapped to one or more data model attributes. Conversely, one or more source fields can be mapped to a single data model attribute. If you map multiple source fields to a single data model attribute, you want Oracle Unity to store multiple values in that one data model attribute. Because of this, you need to ensure you select the appropriate transformation, so that Oracle Unity can correctly combine those multiple values.
- A notification will display if not every data object used in a mapping has its source mapped to an incoming field. Mapping all source data object IDs ensures that duplicate data is removed before it is stored in the system. Review the Source data object IDs not mapped notification before completing field mapping. The notification will identify each unmapped data object with a color.
- A red circle indicates that the unmapped source data object ID (SourceXID attribute) will cause the ingest job to not import the data successfully, even if the ingest job successfully completes. This is because the Incoming records flag for the data object is set to No (insertOnly parameter set to false). Learn more about the Incoming records flag.
- A yellow circle indicates that the source data object ID (SourceXID attribute) is unmapped, but the ingest job will still successfully import the data. This is because the Incoming records flag for the data object is set to Yes (insertOnly parameter set to true). If the SourceXID attribute is not mapped, Oracle Unity will automatically add a unique identifier to the SourceXID attribute when the data is imported. Learn more about the Incoming records flag.

Example: You map the First name attribute from the Customer data object to the FirstName source field in the sample file. You must also map the corresponding SourceCustomerID attribute in the Customer data object to a source field in the sample file so that the data can be successfully imported. This is because the Incoming records flag for the Customer data object is set to No.
Example: You map the Order Total attribute from the Event data object to the OrderTotal source field in the sample file, but you don’t map the SourceEventID attribute to a source field. You will receive a warning the source data object ID is unmapped, but the ingest job will still be able to import the data successfully. This is because the Incoming records flag for the Event data object is set to Yes.
Managing source fields
You can create new source fields if you need to update the field mapping for an existing ingest job. To search through the existing list of source fields, click Find ![]() next to Source fields.
next to Source fields.
You can also edit and delete existing source fields if you need to update the name of the field or remove fields that you no longer need for the ingest job. Source fields you delete will also remove any field mappings you configured for that field.
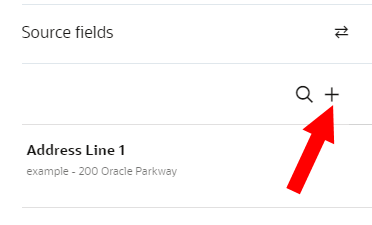
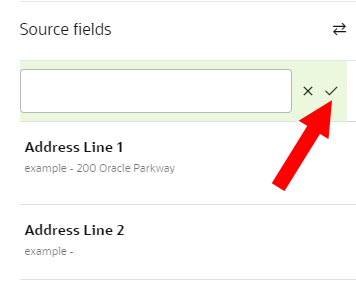
To create new source fields:
- Next to Source fields, click Add.
- Enter the name of the source field. You can use characters from all languages supported in the language settings.
- Click the Checkmark.
- Update the source field as needed by mapping it to data model attributes.
To edit source fields:
- Hover your mouse over the source field name you want to update and click Edit
 .
. - Enter the new source field name and click the checkmark . You can use characters from all languages supported in the language settings.
To delete source fields:
- Hover your mouse over the source field name you want to remove and click Delete
 .
. - Review the confirmation message and click Yes.
Step 3: Schedule and notify
You will need to configure the schedule and notification settings for the ingest job.
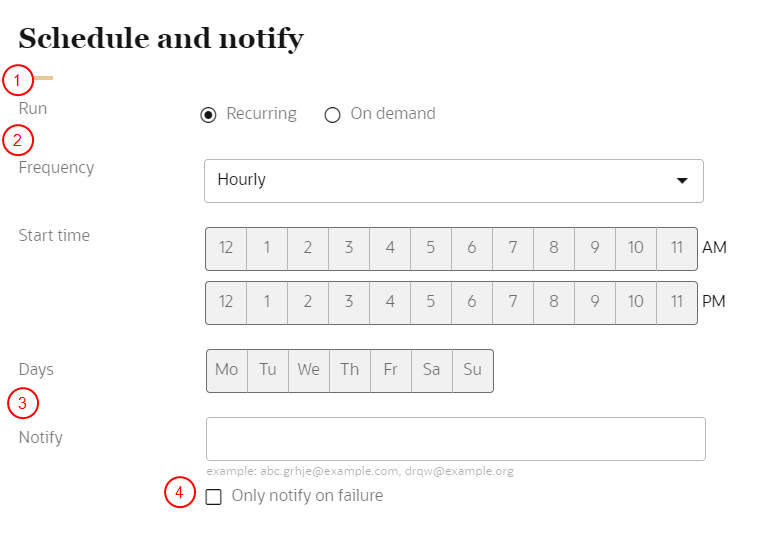
To schedule the ingest job and define the notification settings:
- Configure the schedule for the ingest job:
- Click Recurring to automatically run the job on a regular schedule. If a job is still running while the next one is scheduled to run, the next scheduled run will not start until the current one completes. Two scheduled instances of the same ingest job can't run simultaneously.
- Click On demand to run the job as needed.
- If the job is recurring, select the Frequency, Start time, and Days it will run.
- In the field for Notify, enter the email addresses of people to be notified when the job runs. You can use characters from all languages supported in the language settings. Separate multiple emails with a comma.
- If you only want a notification if the job fails, click the checkbox for Only notify on failure.
Please note that the metrics for ingest jobs in notification emails are approximations and will not always be 100% accurate.
Step 4: Save and publish the ingest job
After saving the ingest job you will need to publish the changes before it can run.
To save and publish the ingest job:
- Scroll to the top of the page and click Save or Save and close.
- Follow the steps for Publishing changes.
When the publishing task is completed, the ingest job can run. Learn more about Managing ingest jobs.