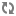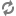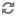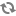You may be able to reduce the size of your index by filtering the property values to remove redundant entries. For example, suppose each XHTML document represents a product with several child SKUs. You might include the SKUs’ salePrice property in the index as a metadata property, so it can be used for faceting. Depending on the product, many of the SKUs may have the same value for salePrice. So the resulting entries in an XHTML document might look something like this:
<meta name="atg:float:childSKUs.salePrice" content="190.0"/>
<meta name="atg:float:childSKUs.salePrice" content="205.0"/>
<meta name="atg:float:childSKUs.salePrice" content="190.0"/>
<meta name="atg:float:childSKUs.salePrice" content="205.0"/>
<meta name="atg:float:childSKUs.salePrice" content="205.0"/>
By filtering out redundant entries, you can reduce this to:
<meta name="atg:float:childSKUs.salePrice" content="190.0"/>
<meta name="atg:float:childSKUs.salePrice" content="205.0"/>
To automatically perform this filtering, specify the UniqueFilter class in the XML definition file:
<property name="salePrice" filter="unique"/>
As a general rule, it is a good idea to specify the unique filter for a property if multiple items in an XHTML document may have identical values for that property. If you specify this filter for a property and every value of that property in an XHTML document is unique (or if only one item with that property appears in the document), the unique filter will have no effect on the resulting XHTML (either negative or positive). However, executing this filter increases processing time to create the document, so it is a good idea to specify it only for properties that will benefit from it.